생존분석
생존분석의 기본 개념
생존분석 (survival analysis) 이란 생존기간을 분석하여 생존함수 (survival function) 또는 생존곡선(survival curve)를 추정하는 통계기법을 말한다. 의학분야에서 생존분석은 새로운 치료방법이나 신약이 생존에 미치는 효과 등을 추정하는데 널리 이용된다.
생존자료는 어떤 정해진 시작점으로부터 사건의 발생시점까지의 기간으로 구성된다. 가령 치료 시작으로부터 사망이란 사건이 발생한 시점까지의 기간으로 구성되어 있으며, 이 시간을 생존시간이라 한다. 다른 연속형 변수를 다루는 통계와 달리 생존 자료는 1) 생존시간 + 2) 사건 발생 의 두 개념을 동시에 다루어야 한다.
또한 생존 자료는 다른 통계와 달리
1) 시간은 대부분 정규분포가 아니다.
2) 중도절단 censoring을 고려해야 한다
는 두 가지 특징을 갖는다.
생존분석에서는 시간, 사건발생 두변수가 종속변수로 필요하므로 일반적인 regression이나 logistic regression으로 분석할 수 없고, 별도의 분석법이 필요하게 된다.
Censored 의 의미
생존분석에는 사건의 발생 여부에 대한 불확실한 자료가 포함된다는 특징이 있다. 이러한 불확실한 자료를 중도절단된 자료(censored data)라 부르며 이러한 자료가 발생하는 이유는 다음과 같다.
① 추적이 불가능한 경우 loss to follow up
연구대상이 추적이 안 되는 경우로 환자가 다른 지역으로 이사하거나, 병원에 오지 않는 등 여러 이유로 추적관찰이 안 되는 경우
② 중도에 탈락된 경우 Withdraw from the study (drop out)
환자가 치료를 거부하거나 경제적인 이유로 치료를 포기하여 subsequent event를 모르는 경우
③ 연구의 종결 termination of the study
환자가 사망하기 전에 연구를 종료하는 경우로 확실히 subsequent event를 알 수 없다.
④ 원인불명의 사망 Death from unrelated causes
관계 없는 원인으로 사망하는 경우
이들 censored data의 경우에는 생존시간은 비록 불확실하지만 censored되기 직전까지는 사건이 발생하지 않았다는 부분적인 정보를 지니고 있다. 따라서 생존분석에서는 이러한 점을 최대로 이용하여 분석할 수 있는 장점이 있다. 만일 중도절단된 자료를 분석에서 모두 제외시킨다면 잘못된 연구결과를 얻을 수 있다.
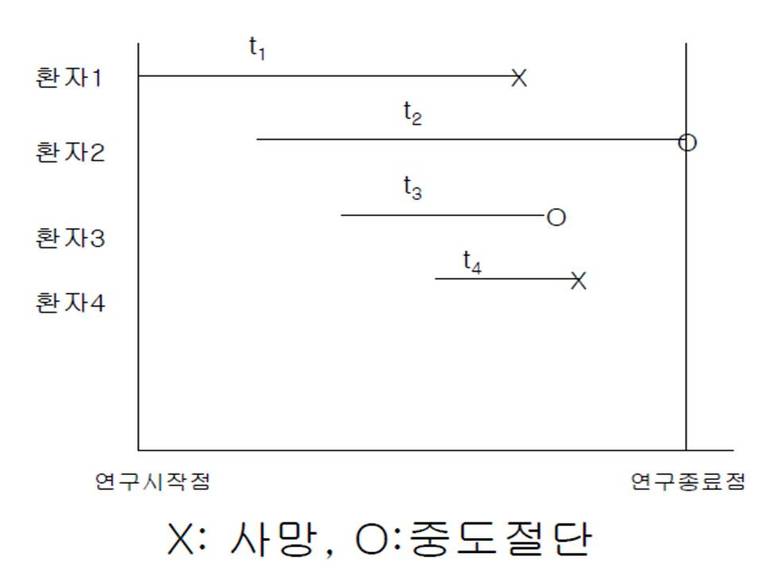
<그림 출처 김호교수님 강의록 http://plaza.snu.ac.kr/~hokim/ >
위의 그림에서 환자 1과 환자 4는 사망한 환자이므로 censored가 아닌 complete에 해당하며, 환자 2는 연구 종료 시점까지 살아있는 환자이므로 censored가 되며 환자 3은 follow up loss에 해당하므로 censored가 된다. 만일 환자 4가 질병에 의한 사망이 아니라 교통사고등 다른 원인에 의해 사망한 것이라면 환자4는 사망이어도 censored 처리가 된다.
연구를 시작하기 전에 censored에 대한 여부를 명확히 알아야 하므로 아래의 사항들이 확실히 정의될 수 있어야 한다.
1) 생존시간의 시작점을 확실히 정의할 수 있어야 한다.
2) 정확한 생존시간을 측정할 수 있는 기준이 있어야 한다.
3) 사건의 발생여부를 확실히 구별할 수 있어야 한다.
생존함수(survivor function, survivor curve)의 추정
생존함수(또는 곡선)란 관찰이 완료되지 않은 경우(censored case)까지 포함하여 한 집단의 생존기간의 분포를 표현하는 방법으로서 관찰이 중단된 사례들은 그 결과에 있어서 관찰이 완료된 사례들과 같을 것이라는 가정이 필요하며, 생존분석의 결과는 표(table)보다는 생존곡선으로 표현하는데 추정방법에는 크게 생명표법 (life table method)와 Kaplan-Meier법이 있다.
1. 생존함수 (Survival Function)
1) 생존함수의 정의 : t 시점에서의 생존함수 값은 t 시점까지 사망하지 않고 생존할 확률로서 정의된다. 즉 환자가 t 시간이상 생존할 확률이다.
S(t) = P (an individual survives longer than t)
간단히 S(t) = P(T>t)
만일 중도절단된 자료가 없는 경우라면 t 시점에서의 생존함수 값은 다음의 경험함수로 추정할 수 있다.
S(t) = (t이상생존한대상수) / (연구에참여한총대상수)
생존함수를 추정하는 방법은 크게 parametric model과 non-parametric model이 있으나 임상에서 흔히 사용하는 방법은 non-parametric model이다. non-parametric model의 대표적인 방법으로 1) life table method, 2) Kaplan-Meier method (product limit method), 3) Cox proportional hazard model이 있다.
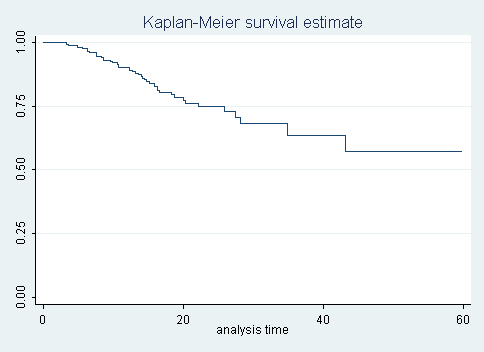
일반적으로 가장 많이 사용되는 Kaplan-Meier 곡선은 생존확률을 아래와 같이 그래프로 표현한 것이며, 이를 Kaplan-Meier 곡선 이라 한다. 이 곡선에서 median survival과 5year surival rate 등을 쉽게 구할 수 있다.
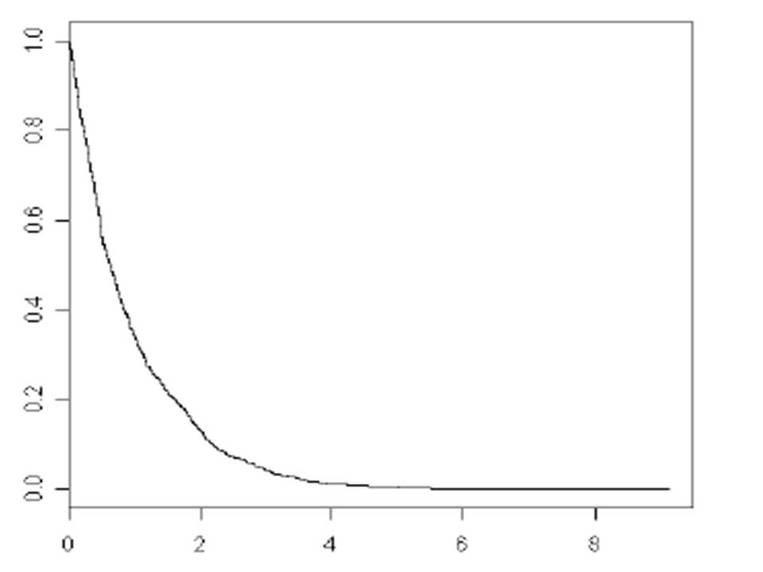
원래 생존함수의 이론적인 형태는 아래와 같이 그려져야 한다. S(0)=1, S(무한대)=0 이며 exponential하게 그려지게 된다. (이런 이유로 Cox proportional hazard model에서 exponential을 이용하여 hazard를 구하게 된다)
2. 위험함수 (Hazard Function)
1) 정의 : t 시점에서의 위험함수는 t 시점까지 생존한 사람이 t 시점 바로 직후 순간적으로 사망할 조건부 확률로서 정의된다. (매우 중요한 개념) 즉 Time t까지 살아온 개체가 time t에 단위시간당 사망할 확률(순간사망율)을 의미한다.


위험함수와 생존함수는 함수관계에 있지만, 어떤 시점에서 생존함수 값이 크다고 해서 위험함수 값이 반드시 작은 것은 아니다. 물론 위험함수의 값이 커질수록 생존시간은 대체로 작아지는 경향이 있다. (혼동하지 말 것) 위험함수 (Hazard Function)은 역학에서 말하는 순간사망률의 정의와 동일하다.
위험함수와 생존함수와의 관계

Ref>
송경일 안재억 저, 생존분석, SPSS 아카데미
김호교수님 강의록 http://plaza.snu.ac.kr/~hokim/
Spotswood L. Spruance et al. Hazard Ratio in Clinical Trials ANTIMICROBIAL AGENTS AND CHEMOTHERAPY, Aug. 2004, p. 2787?2792