Chapter 01. 오라클 아키텍처
01. 기본 아키텍처
▣ 오라클은 워드 프로세서와 마찬가지로 처리 속도 향상을 위해 메모리 캐시 영역을 두는 데, 해당 영역을 SGA 라고 한다.
▣ 많은 프로세스가 동시에 데이터를 액세스하므로, 사용자 데이터를 보호하는 Lock 은 물론 공유 메모리 영역인 SGA 상에
위치한 데이터 구조에 대한 액세스를 직렬화 하기 위한 LOCK 메커니즘(Latch) 도 필요하다.
▣ Database
- Datafiles
- Redo Log Files
- Control Files
▣ Instance
- Memory + Process
▣ 오라클 접속 과정
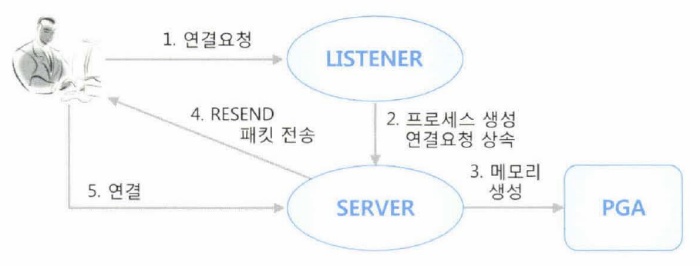
▣ PGA (Program Global Area) : 서버 프로세스만을 위한 독립적인 메모리 공간.
SGA( System Global Area) : 서버 프로세스와 백그라운드 프로세스가 공통으로 액세스하는 공간.
▣ RAC 환경에서는 글로벌 캐시(Global Cache) 개념을 사용하므로, 로컬 캐시에 없는 데이터 블록을 이웃 노드에서 전송받아
서비스(Cache Fusion) 할 수 있다.
또한, 커밋하지 않은 Active 상태의 블록까지도 디스크를 경유하지 않고 Dirty 버퍼 상태에서 네트워크를 통해 서로 주고받으며
갱신 할 수 있다.
RAC 이전 OPS 환경에서는 타 노드에 캐싱된 Dirty 버퍼를 읽고자 할 때 디스크로의 쓰기 작업이 선행되어야만 했고, 이처럼
디스크를 거치는 동기화 과정을 '핑(ping)' 이라 한다.
02. DB 버퍼 캐시
(1) 블록 단위 I/O
- 인덱스를 경유한 테이블 액세스 시에는 한 번에 한 블록씩 읽어들이지만, Full Scan 시에는 성능 향상을 위해 한 번에 여러 개
블록(db_file_multiblock_read_count)을 읽어 들인다.
- DBWR 프로세스도 버퍼 캐시로부터 변경된 블록(Dirty 버퍼)을 주기적으로 데이터파일에 기록하는 작업을 수행하는데, 이때도
성능향상을 위해 한 번에 여러 블록을 처리한다.
(2) 버퍼 캐시 구조
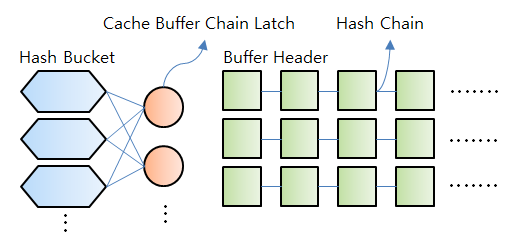
- DB 버퍼 캐시 내에서 데이터 블록을 해싱하기 위해 사용되는 키 값은 데이터 블록 주소(DBA, Data Block Address) 다.
- Hash Function에 DBA를 입력해 리턴받은 Hash value 이 같은 블록들을 같은 Hash Bucket에 Linked List 구조로 연결한다.
- 해당 Hash Bucket 에 존재하면 바로 읽고, 찾지 못하면 디스크에서 읽어 Hash Chain에 연결한 후 읽는다.
- Buffer Header 만 Hash Chain 에 연결되며, 실제의 데이터 값이 필요해지면 Buffer Header 에 있는 포인터를 이용해 다시
Buffer Block 을 찾아가는 구조이다.
※ 해싱 : 하나의 문자열을 원래의 것을 상징하는 더 짧은 길이의 값이나 키로 변환하는 것.
(3) 캐시 버퍼 체인
- 같은 Resource 에 대한 access 를 serialization 하기 위해, Lock 매커니즘인 Latch 를 사용한다.
- 하나의 cache buffers chains 래치가 여러 개 Hash Chain 을 동시에 관리한다.
- 하나의 Hash Bucket 과 Hash Chain 은 1:1 관계이다.
- 해시 체인을 스캔하거나 블록을 추가, 제거할 때 래치가 요구된다.
- 9i 부터 Hash Chain 을 스캔할 때는 Share 모드로 래치를 획득했다가 체인 구조를 변경하거나 버퍼 헤더에 Pin을
설정할 때만 Exclusive 모드로 올리도록 커널 코드 변경된 것 같다.
(4) 캐시 버퍼 LRU 체인
- 버퍼 헤더는 Hash Chain 뿐 아니라 LRU 체인에 의해서도 연결돼 있는 데, 메모리는 유한한 자원이므로 LRU 알고리즘을
사용해 사용빈도가 높은 데이터 블록 위주로 구성될 수 있도록 관리된다.
▣ Dirty 리스트 : 캐시 내에서 변경됐지만, 아직 디스크에 기록되지 않은 Dirty 버퍼 블록들을 관리하며, LRUW(LRU Write)
라고 한다.
▣ LRU 리스트 : 아직 Dirty 리스트로 옮겨지지 않은 나머지 버퍼 블록들을 관리한다.
해당 LRU 리스트를 보호하기 위해 cache buffers lru chain 래치를 사용한다.
▣ 버퍼 상태
- Free 버퍼 : 인스턴스 기동 후 아직 데이터가 읽히지 않아 비어 있는 상태(Clean 버퍼)이거나, 데이터가 담겼지만
데이터 파일과 서로 동기화돼 있는 상태여서 언제든지 덮어 써도 무방한 버퍼 블록을 말한다.
- Dirty 버퍼 : 버퍼에 캐시된 이후 변경이 발생했지만, 아직 디스크에 기록되지 않아 데이터 파일 블록과 동기화가 필요한
버퍼 블록을 말한다.
해당 버퍼 블록들은 디스크에 기록되는 순간 Free 버퍼로 상태가 바뀐다.
- Pinned 버퍼 : 읽기 또는 쓰기 작업을 위해 현재 액세스되고 있는 버퍼 블록을 말한다.
03. 버퍼 Lock
(1) 버퍼 Lock이란?
- 두개 이상의 프로세스가 동시에 버퍼 내용을 읽고 쓸 때, 데이터 정합성을 유지하기 위해 해당 버퍼에 Lock 을 획득하는
것이다.
- 버퍼 Lock을 획득했다면 래치를 곧바로 해제하고, 읽기만 할 때는 Share 모드, 변경할 때는 Exclusive 모드로 Lock 을
설정한다.
select 문이더라도 블록 클린아웃이 필요할 때는 버퍼 내용을 변경하는 작업이므로 Exclusive 모드 Lock 을 요구한다.
- 이미 다른 프로세스가 버퍼 Lock 을 Exclusive 모드로 점유한 채 내용을 갱신 중이라면, 버퍼 헤더에 있는 버퍼 Lock
대기자 목록에 자신을 등록하고 일단 래치는 해제한다.
버퍼 Lock 대기자 목록에 등록돼 있는 동안 buffer busy waits 대기 이벤트가 발생한다.
- 버퍼 Lock 을 해제할 경우에도 다른 프로세스와 충돌이 생길 수 있으므로 해당 버퍼가 속한 체인 래치를 다시 한번 획득한다.
- 래치 획득에 관해서는 v$sysstat 뷰에서 consistent gets - examination 통계 항목으로 측정 가능하다.

(2) 버퍼 핸들
- 버퍼 Lock 설정 = 버퍼 헤더 Pin
- 버퍼 헤더에 Pin을 설정하려고 사용하는 오브젝트를 'Buffer Handle' 이라고 부르며, 버퍼 핸들을 얻어 버퍼 헤더에 있는
소유자 목록(Holder List)에 연결시키는 방식으로 Pin 을 설정한다.
- 버퍼 핸들도 공유된 리소스이므로 버퍼 핸들을 얻으려면 또 다른 래치가 필요해지는데, 바로 cache buffer handles 래치이다.
- 전체 버퍼 핸들 개수 = processes 파라미터 * _db_handles_cached 파라미터
(3) 버퍼 Lock의 필요성
- DML Lock을 통해 데이터 변경시 보호를 하는데, 블록 Lock 도 획득을 하는 이유는 오라클이 하나의 레코드를 갱신하더라도
블록 단위로 I/O를 수행하기 때문이다.
(4) 버퍼 Pinning
- 버퍼를 읽고 나서 버퍼 Pin을 즉각 해제하지 않고 데이터베이스 Call이 진행되는 동안 유지하는 기능으로써, 같은 블록을
반복적으로 읽을 때 버퍼 Pinning 을 통해 래치 획득과정을 생략해서 Logical Reads 횟수를 줄일 수 있다.
모든 버퍼 블록을 이 방식으로 읽는 것은 아니며, 같은 블록을 재방문할 가능성이 큰 몇몇 오퍼레이션을 수행할 때만 사용한다.
- 버퍼 Pinning 이 적용되는 지점은 인덱스를 스캔하면서 테이블을 액세스할때의 인덱스 리프 블록이다.
Index Range Scan 하면서 인덱스와 테이블 블록을 교차 방문할 때 블록 I/O를 체크해 보면, 테이블 블록에 대한 I/O 만
계속 증가하는 이유가 이것이다.
- 8i 부터 인덱스로부터 액세스되는 하나의 테이블 블록을 Pinning 하기 시작했다.
- 9i 부터는 NL 조인 시 Inner 테이블을 Lookup하기 위해 사용되는 인덱스 루트 블록을 Pinning 하기 시작했다.
Index Skip Scan 에서 브랜치 블록을 거쳐 리프 블록을 액세스하는 동안에도 브랜치 블록을 계속 Pinning 하고 있다가
그 다음 방문할 리프 블록을 찾으려 할 때 추가적인 래치 획득과정 없이 브랜치 블록을 곧바로 읽는다.
- 11g 부터는 NL 조인 시 Inner 테이블의 인덱스 루트 블록 뿐 아니라 다른 인덱스 블록에 대해서도 Pinning을 함으로써
Logical Reads를 획기적으로 감소시키고 있다.
▣ 래치 획득을 통한 블록 액세스

▣ 버퍼 Pinning 을 통한 블록 액세스

04. Redo
▣ Online Redo Log : Redo 로그 버퍼에 버퍼링된 로그 엔트리를 기록하는 파일로서, 최소 두 개 이상의 파일로 구성된다.
▣ Archived Redo Log : Online Redo Log가 재사용되기 전에 다른 위치로 백업해 둔 파일을 말한다.
▣ Redo 로그의 목적
① Database Recovery
② Cache Recovery (Instance Recovery 시 roll forward 단계)
- Instance Crash 발생 후 시스템 재기동 -> 마지막 체크포인트 이후부터 사고 발생 직전까지 수행되었던 트랜잭션들을 재현
(roll forward) -> Undo 데이터를 이용해 아직 커밋되지 않았던 트랜잭션들을 모두 롤백(rollback)
③ Fast Commit
▣ LGWR 활동 시기
① 3초마다
② 1/3 이 차거나 1MB 가 넘을 때
③ 커밋 또는 롤백 수행 시
- 버퍼 캐시에 있는 블록 버퍼를 갱신하기 전에 먼저 Redo 엔트리를 로그 버퍼에 기록해야 하며, DBWR 가 버퍼 캐시로부터
Dirty 블록들을 디스크에 기록하기 전에 먼저 LGWR가 해당 Redo 엔트리를 모두 Redo 로그 파일에 기록했음이 보장되어야 함.
▣ Fast Commit 매커니즘
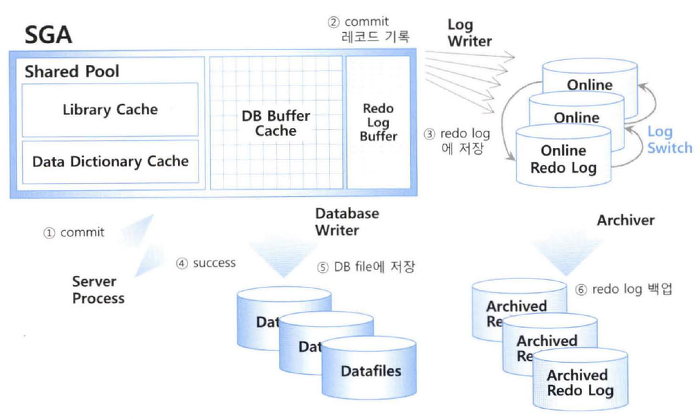
※ 사용자가 커밋 또는 롤백할 때마다 log file sync 대기 이벤트가 발생한다.
05. Undo
- 각 트랜잭션 별로 Undo 세그먼트를 할당해 주고 그 트랜잭션이 발생시킨 테이블과 인덱스에 대한 변경사항들을 Undo 레코드
단위로 Undo 세그먼트 블록에 기록한다.
▣ Undo 의 목적
① Transaction Rollback
② Transaction Recovery
③ Read Consistency
(1) Undo 세그먼트 트랜잭션 테이블 슬롯
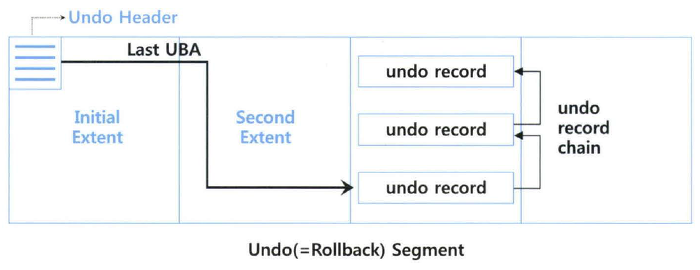
- Undo 세그먼트 중 첫 번째 익스텐트, 그중에서도 첫 번째 블록에 Undo 세그먼트 헤더 정보가 담긴다.
▣ 언두 세그먼터 헤더 정보
① 트랜잭션 ID [USN# + Slot# + Wrap#]
② 트랜잭션 상태정보
③ 커밋 SCN
④ Last UBA
⑤ 기타
※ 트랜잭션 슬롯을 곧바로 언지 못해 이용 가능한 슬롯이 생기기를 기다릴 때 발생하는 대기 이벤트는 undo segment tx slot.
▣ 각 DML 별 기록 내용
- Insert : 추가된 레코드의 rowid
- Update : 변경되는 컬럼에 대한 before image
- Delete : 지워지는 로우의 모든 컬럼에 대한 before image
- Active 상태의 트랜잭션이 사용하는 Undo 블록과 트랜잭션 테이블 슬롯은 절대 다른 트랜잭션에 의해 재사용되지 않는다.
커밋한 후에는 트랜잭션 상태정보를 'committed' 로 변경하고 그 시점의 커밋 SCN 을 트랜잭션 슬롯에 저장해 둔다.
이 작업이 완료되면 해당 트랜잭션 슬롯과 Undo 블록들은 다른 트랜잭션에 의해 재사용될 수 있다.
(2) 블록 헤더 ITL 슬롯
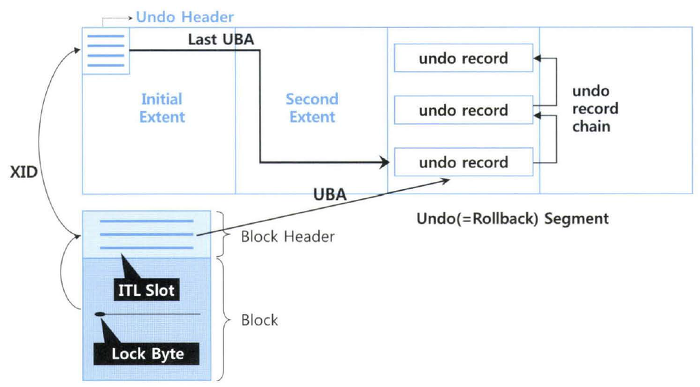
▣ ITL(Interested Transaction List) 슬롯에 기록되는 내용
① ITL 슬롯 번호
② 트랜잭션 ID
③ UBA (Undo Byte Address)
④ 커밋 Flag
⑤ Locking 정보
⑥ 커밋 SCN
※ 특정 블록에 속한 레코드를 갱신하려면 먼저 블록 헤더로부터 ITL 슬롯을 확보해야 하고, ITL 슬롯에 트랜잭션 ID 를 기록한
후, 해당 트랜잭션이 Active 상태임을 표시해야 블록 갱신이 가능하다.
※ ITL 슬롯이 부족할 때 enq: TX - allocate ITL entry 대기 이벤트가 발생한다.
(3) Lock Byte
- 레코드가 저장되는 로우마다 그 헤더에 Lock Byte를 할당해 해당 로우를 갱신 중인 트랜잭션의 ITL 슬롯 번호를 기록한다.
- 대상 레코드의 Lock Byte가 활성화 돼 있으면 ITL 슬롯을 찾아가고, 다시 그 ITL 슬롯이 가리키는 트랜잭션 테이블 슬롯을
찾아가 그 트랜잭션이 아직 active 상태면 트랜잭션이 완료될 때까지 대기한다.
- UBA(Undo Block Address) 는 트랜잭션에 의해 발생한 변경 이전 데이터(before image)가 저장된 Undo 블록 주소를
가리키는 포인터 정보이다.