What
A Go program with no human provided knowledge. Using MCTS (but without Monte Carlo playouts) and a deep residual convolutional neural network stack.
This is a fairly faithful reimplementation of the system described in the Alpha Go Zero paper "Mastering the Game of Go without Human Knowledge". For all intents and purposes, it is an open source AlphaGo Zero.
Wait, what
If you are wondering what the catch is: you still need the network weights. No network weights are in this repository. If you manage to obtain the AlphaGo Zero weights, this program will be about as strong, provided you also obtain a few Tensor Processing Units. Lacking those TPUs, I'd recommend a top of the line GPU - it's not exactly the same, but the result would still be an engine that is far stronger than the top humans.
Gimme the weights
Recomputing the AlphaGo Zero weights will take about 1700 years on commodity hardware, see for example: http://computer-go.org/pipermail/computer-go/2017-October/010307.html
One reason for publishing this program is that we are setting up a public, distributed effort to repeat the work. Working together, and especially when starting on a smaller scale, it will take less than 1700 years to get a good network (which you can feed into this program, suddenly making it strong). Further details about this will be announced soon.
I just want to play right now
A small network with some very limited training from human games is available here: https://sjeng.org/zero/best.txt.zip.
It's not very strong right now (and it's trained from human games, boo!). It will clobber gnugo, but lose to any serious engine. Hey, you said you just wanted to play right now!
I plan to update this network with more or better training when available - just feeding it into this program will make it stronger. Unzip it and specify the weights.txt file on the command line with the -w option.
Compiling
Requirements
- GCC, Clang or MSVC, any C++14 compiler
- boost 1.58.x or later (libboost-all-dev on Debian/Ubuntu)
- BLAS Library: OpenBLAS (libopenblas-dev) or (optionally) Intel MKL
- Standard OpenCL C headers (opencl-headers on Debian/Ubuntu, or at https://github.com/KhronosGroup/OpenCL-Headers/tree/master/opencl22/)
- Standard OpenCL C++ headers (opencl-headers on Debian/Ubuntu, or at https://github.com/KhronosGroup/OpenCL-CLHPP, you can just copy input_cl.hpp into CL/cl2.hpp)
- OpenCL ICD loader (ocl-icd-libopencl1 on Debian/Ubuntu, or reference implementation at https://github.com/KhronosGroup/OpenCL-ICD-Loader)
- An OpenCL capable device, preferably a very, very fast GPU, with drivers (OpenCL 1.2 support should be enough, even OpenCL 1.1 might work)
- The program has been tested on Windows, Linux and MacOS.
Example of compiling and running - Ubuntu
# Test for OpenCL support & compatibility
sudo apt install clinfo && clinfo
# Clone github repo
git clone https://github.com/gcp/leela-zero
cd leela-zero/src
sudo apt install libboost-all-dev libopenblas-dev opencl-headers ocl-icd-libopencl1 ocl-icd-opencl-dev
make
cd ..
wget https://sjeng.org/zero/best.txt.zip
unzip https://sjeng.org/zero/best.txt.zip
src/leelaz --weights weights.txt
Usage
The engine supports the GTP protocol, version 2, specified at: https://www.lysator.liu.se/~gunnar/gtp/gtp2-spec-draft2/gtp2-spec.html
Add the --gtp commandline option to enable it. You will need a weights file, specify that with the -w option.
All required commands are supported, as well as the tournament subset, and "loadsgf". The full set can be seen with "list_commands". The time control can be specified over GTP via the time_settings command. The kgs-time_settings extension is also supported. These have to be supplied by the GTP 2 interface, not via the command line!
Sabaki (http://sabaki.yichuanshen.de/) is a very nice looking GUI with GTP 2 capability. It should work with this engine.
Weights format
The weights file is a text file with each line containing a row of coefficients. The layout of the network is as in the AlphaGo Zero paper, but the number of residual blocks is allowed to vary. The program will autodetect the amount on startup.
- Convolutional layers have 2 weight rows:
- convolution weights
- channel biases
- Batchnorm layers have 2 weight rows:
- batchnorm means
- batchnorm variances
- Innerproduct (fully connected) layers have 2 weight rows:
- layer weights
- output biases
You might note there are 18 inputs instead of 17 as in the paper. The original AlphaGo Zero design has a slight imbalance in that it is easier for the white player to see the board edge (due to how padding works in neural networks). This has been fixed in Leela Zero. The inputs are:
1) Side to move stones at time T=0
2) Side to move stones at time T=-1 (0 if T=0)
...
8) Side to move stones at time T=-8 (0 if T<=7)
9) Other side stones at time T=0
10) Other side stones at time T=-1 (0 if T=0)
...
16) Other side stones at time T=-8 (0 if T<=7)
17) All 1 if black is to move, 0 otherwise
18) All 1 if white is to move, 0 otherwise
The zero.prototxt file contains a description of the full 40 residual layer design, in (NVIDIA)-Caffe protobuff format. It can be used to set up nv-caffe for training a suitable network. The zero_mini.prototxt file describes the 12 residual layer case that was used for the example supervised network listed in "I just want to play".
Training
Getting the data
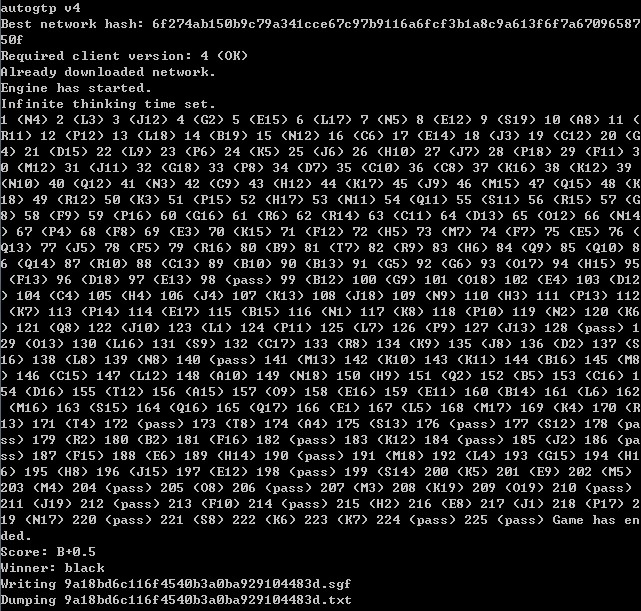
At the end of the game, you can send Leela Zero a "dump_training" command, followed by the winner of the game (either "white" or "black") and a filename, e.g:
dump_training white train.txt
This will save (append) the training data to disk, in the format described below. Training data is reset on a new game.
File format
The training data consists of a file with the following data, all in text format:
- 18 lines of 361 0's or 1's, corresponding to the inputs from the previous section
- 1 line with 362 floating point numbers, indicating the search probabilities (visit counts) at the end of the search for the move in question. The last number is the probability of passing.
- 1 line with either 1 or -1, corresponding to the outcome of the game for the player to move
Running the training
For training a new network, you can use an existing framework (Caffe, TensorFlow, PyTorch, Theano), with a set of training data as described above. You still need to contruct a model description (2 examples are provided for Caffe), parse the input file format, and outputs weights in the proper format.
Supervised learning
For experimenting with supervised learning, you'll need a tool that takes SGF, extracts the input features as described above, the move that was played and whether the side to move won, and runs the training. Leela Zero doesn't have this code yet, so your best bet is to modify Mugo (https://github.com/brilee/MuGo), which is fairly accessible Python code that is ready to interface to TensorFlow.
Todo
- List of package names for more distros
- A real build system like CMake would nice
- Provide or link to self-play tooling
- CPU support for Xeon Phi and for people without a GPU
- Faster GPU usage via batching
- Faster GPU usage via Winograd transforms
- CUDA specific version using cuDNN
- AMD specific version using MIOpen
- Faster GPU usage via supporting multiple GPU (not very urgent, we need to generate the data & network first and this can be done with multiple processes each bound to a GPU)
License
The code is released under the GPLv3 or later, except for ThreadPool.h, which has a specific license (zlib License - compatible with GPLv3) mentioned in that file.