Chapter 2
- 인공 뉴런
- 퍼셉트론 학습 알고리즘 구현
- 적응형 선형 뉴런과 학습의 수렴
인공 뉴런
인공 뉴런은 사람의 뇌를 컴퓨터에서 구현하기 위하여 설계된 모델로 어떠한 신호에 대하여 합쳐진 신호가 특정 임계값을 넘을 시 출력신호가 생성되고 출삭 돌기를 이용하여 전달되는 형식을 구현했다.
인공 뉴런이 하는 작업을 이진 분류 작업으로 이야기할 수 있다.
입력값 x와 이에 상응하는 가중치 벡터 x에 대한 선형 조합으로 결정 함수( decision function)를 정의한다. ( 수식 표현 : σ(z) )
최종 입력(net input)인 z는 각 입력 값x에 대응되는 가중치의 곱의 합으로 이루어져있다.
퍼셉트론 알고리즘에서 결정 함수는 단위 계단 함수(unit step function)를 변형한 것이다.
σ(z)에 대하여 임계값을 고려할 때 z값은 w^T * x + b로 변한다. 여기서 b는 -Θ값으로 임계값에 대해 음수로 변환시킨 값이다.
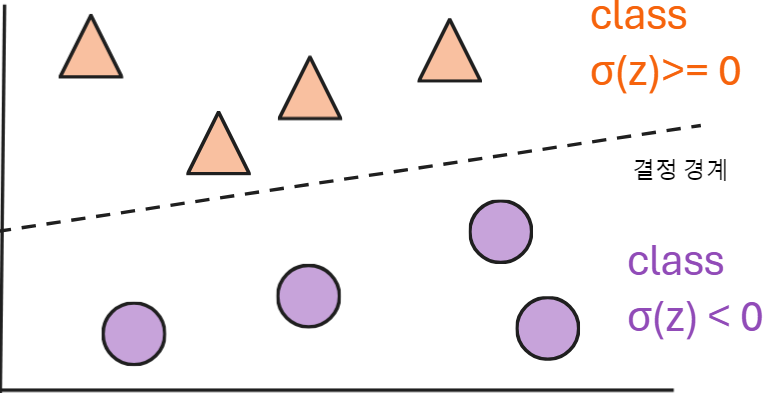
결정 임계값(decision threshold)은 결정 함수에 있어 기준점이 되는 값으로 이 값 이상이면 True를 미만이면 False를 출력하는 개념이다. 임계값이 높을수록 정밀도가 높아지고 낮을수록 낮아지나 과적합이나 재현율에 대한 문제로 너무 높게만 적용시키는 것은 지양해야 한다.
초기 퍼셉트론 학습 규칙
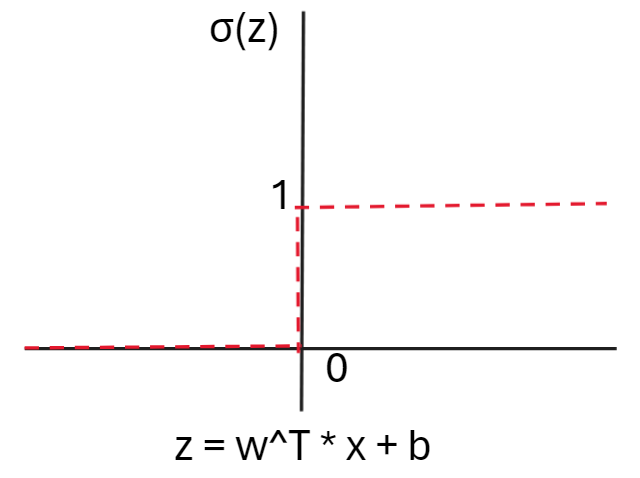 |  |
초기 퍼셉트론 학습 규칙은 True와 False로 출력을 내거나 내지 않는 두 가지 경우만 있다
퍼셉트론 알고리즘은 가중치를 0 또는 랜덤한 작은 값으로 초기화한다.
이후 각 훈련 샘플 x(i)에 대해서 출력 값 ŷ을 계산하고 이 ŷ에 대해서 가중치와 절편을 업데이트 하는 방식으로 진행된다.
출력 값 ŷ은 앞서 정의한 단위 계단 함수로 예측한 클래스 레이블이며 가중치 벡터 w와 절편 값에 대하여 동시에 업데이트 되는 식으로 계산된다
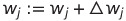
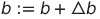
업데이트 값인 Δ는 다음과 같이 계산된다
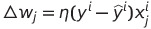
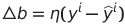
각 가중치는 데이터셋에 있는 특성 x_{j}에 대응됨에 유의.
퍼셉트론은 두 클래스가 선형적으로 구분될 때에만 수렴이 보장된다.
비 선형 경계에서는 수렴이 보장되지 않는다.
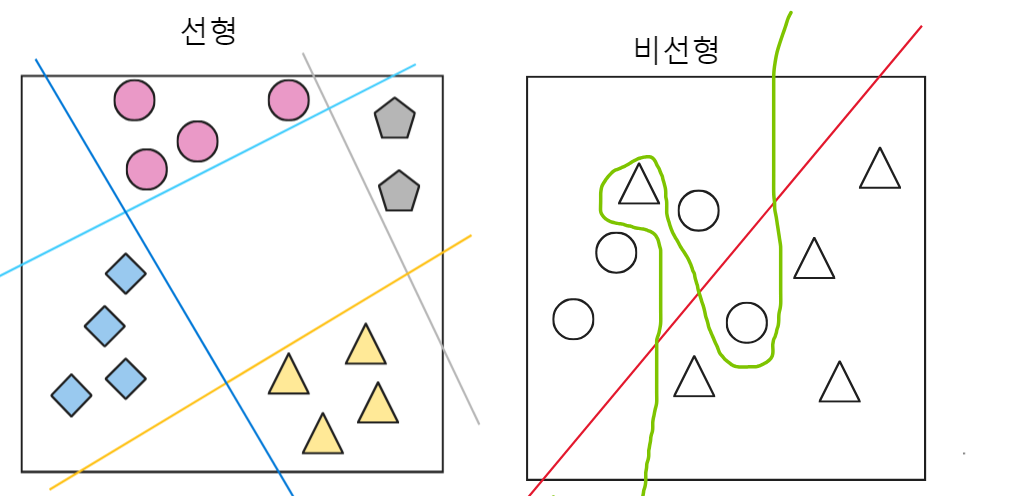
비 선형의 경우 훈련 데이터셋을 반복할 최대 횟수(에포크)를 지정하여 분류 허용 오차를 지정 가능하다.
이 값이 설정이 되어있지 않는다면 퍼셉트론은 가중치 없데이트를 계속 진행한다.
퍼셉트론 학습 알고리즘 구현
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 | import numpy as np class Perceptron: """ 퍼셉트론 분류기 매개변수 -> 일반적으로 생각하는 그 매개변수로 이해해도 OK ----------------- eta : float형 데이터 학습률 (0.0과 1.0 사이) n으로도 표시 n_iter : int형 데이터 훈련 데이터셋 반복 횟수 에포크 random_state : int형 데이터 가중치 무작위 초기화를 위한 난수 생성기 시드 속성 -> ----------------- w_ : 1d-array 학습된 가중치 b_ : 스칼라 학습된 절편 유닛 errors_ : list () 에포크마다 누적된 분류 오류 """ def __init__(self, eta=0.01, n_iter=50, random_state=1): self.eta = eta #학습률 self.n_iter = n_iter #에포크 self.random_state = random_state #난수 def fit(self, X, y): """훈련 데이터 학습 매개변수 ------------------ X : {array-like}, shape = [n_samples, n_features] n_samples개의 샘플과 n_features개의 특성으로 이루어진 훈련 데이터 - n-features(차원) Y : array-like, shape = [n_samples] 타깃 값 반환값 ------------------- self : object """ rgen = np.random.RandomState(self.random_state) #차원을 1차원으로 줄여서 가중치와 절편 유닛 초기화 self.w_ = rgen.normal(loc=0.0, scale=0.01, size=X.shape[1]) self.b_ = np.float_(0.) self.errors_ = [] for _ in range(self.n_iter): errors = 0 for xi, target in zip(X, y): #튜플로 X,y묶음 각각의 xi와 target에 대해서 값을 집어넣음. #실 결과값과 예측 결과를 뺀 차이에 대해서 학습률을 곱해 delta값을 구함. update = self.eta * (target - self.predict(xi)) self.w_ += update * xi #delta weight = eta*xj self.b_ += update #delta b(절편값) = (예측값만 맞으면 -, 실제값만 맞으면 +)eta errors += int(update !=0.0) self.errors_.append(errors) #잘못 분류된 샘플의 수를 추가 저장(분류 오류 추적) return self def net_input(self, X): """입력 계산""" #벡터 점곱(unit step function) == 결정함수 == 단위 계단 함수 계산. return np.dot(X, self.w_) + self.b_ def predict(self, X): """단위 계단 함수를 사용하여 클래스 레이블 반환""" return np.where(self.net_input(X) >= 0.0 , 1, 0) | cs |
위 퍼셉트론 학습 알고리즘을 실제로 구현한 코드이다.
fit 메서드는 가중치를 초기화하고 훈련 데이터셋을 순회하며 규칙에 따라 가중치를 업데이트한다.
label 결과는 predict 메서드에서 예측하고 에포크마다 잘못 분류된 데이터들을 self.errors_ 리스트에 저장한다.
np.dot는 z값을 계산한다. (결정 함수)
퍼셉트론 알고리즘 구현 테스트
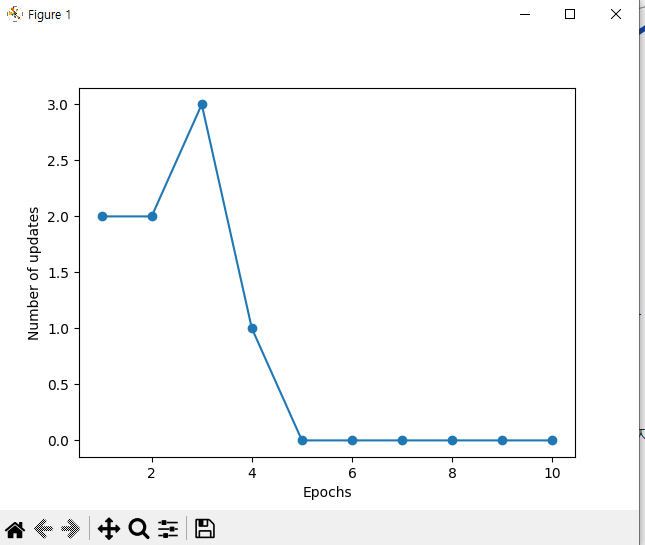
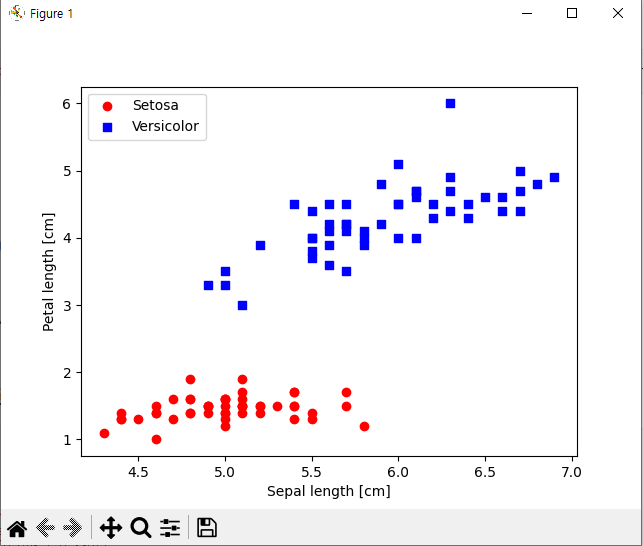
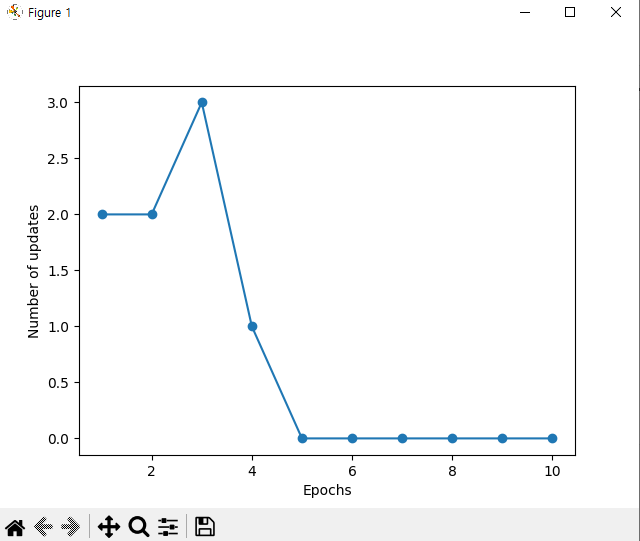
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | import matplotlib.pyplot as plt import numpy as np import pandas as pd import perceptron_test as pt #URL을 이용해서 csv파일 불러오기 df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data') y = df.iloc[0:100, 4].values y = np.where(y == 'Iris-setosa', 0, 1) #꽃받침 길이와 꽃잎 길이 추출 X = df.iloc[0:100, [0,2]].values #산점도 그림 plt.scatter(X[:50, 0], X[:50, 1], color='red', marker='o', label='Setosa') plt.scatter(X[50:100, 0], X[50:100, 1], color='blue', marker='s', label='Versicolor') plt.xlabel('Sepal length [cm]') plt.ylabel('Petal length [cm]') plt.legend(loc='upper left') plt.show() #에포크 대비 잘못 분류된 오차의 그래프 구현. ppn = pt.Perceptron(eta=0.1, n_iter=10) ppn.fit(X, y) plt.plot(range(1, len(ppn.errors_) + 1), ppn.errors_, marker='o') plt.xlabel('Epochs') plt.ylabel('Number of updates') plt.show() | cs |
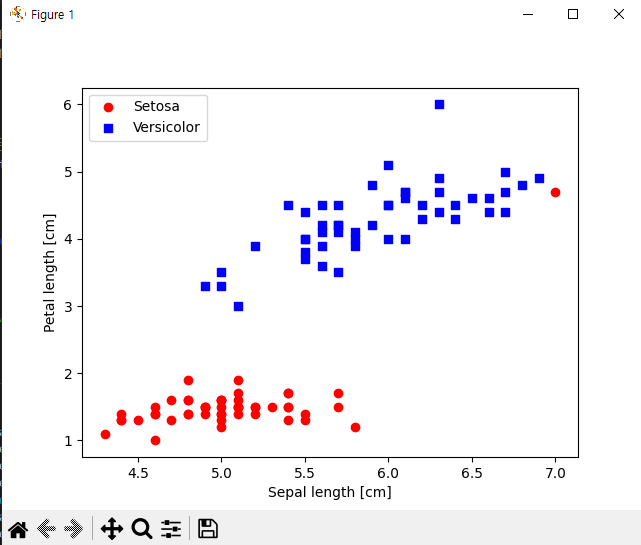 |  |
내부 데이터에서 변화가 있었는지 Versicolor영역에 Setosa 값이 하나 들어있는 모습.
따라서 에포크가 책에서는 6번째 이후 에포크 이후로 0에 수렴하나 이번 데이터 셋에서는 5번째 이후 에포크 이후로 0에 수렴하는 모습을 보임.
에포크가 0에 수렴하는 것을 보아 아슬아슬하게 선형으로 데이터가 그어지는것으로 보인다.
Versicolor의 영역을 1 줄이는 것으로 우선적으로 군집영역에 대해 분리시킴
에포크에 변화가 없는 것으로 보아 실질적으로 이 데이터가 미친 영향은 미미하던 것으로 보임.
 |  |
결정 경계 실험.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 | import matplotlib.pyplot as plt import numpy as np import pandas as pd import perceptron_test as pt from matplotlib.colors import ListedColormap def plot_decision_regions(X, y, classifier, resolution=0.02): # 마커와 컬러맵을 설정합니다 markers = ('o', 's', '^', 'v', '<') colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan') cmap = ListedColormap(colors[:len(np.unique(y))]) # plot the decision surface x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1 x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1 xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution), np.arange(x2_min, x2_max, resolution)) lab = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T) lab = lab.reshape(xx1.shape) plt.contourf(xx1, xx2, lab, alpha=0.3, cmap=cmap) plt.xlim(xx1.min(), xx1.max()) plt.ylim(xx2.min(), xx2.max()) # 샘플의 산점도를 그립니다 for idx, cl in enumerate(np.unique(y)): plt.scatter(x=X[y == cl, 0], y=X[y == cl, 1], alpha=0.8, c=colors[idx], marker=markers[idx], label=f'Class {cl}', edgecolor='black') #URL을 이용해서 csv파일 불러오기 df = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data') y = df.iloc[0:100, 4].values y = np.where(y == 'Iris-setosa', 0, 1) #꽃받침 길이와 꽃잎 길이 추출 X = df.iloc[0:100, [0,2]].values #에포크 대비 잘못 분류된 오차의 그래프 구현. ppn = pt.Perceptron(eta=0.1, n_iter=10) ppn.fit(X, y) plot_decision_regions(X, y, classifier=ppn) plt.xlabel('Sepal length [cm]') plt.ylabel('Petal length [cm]') plt.legend(loc='upper left') #plt.savefig('images/02_08.png', dpi=300) plt.show() | cs |
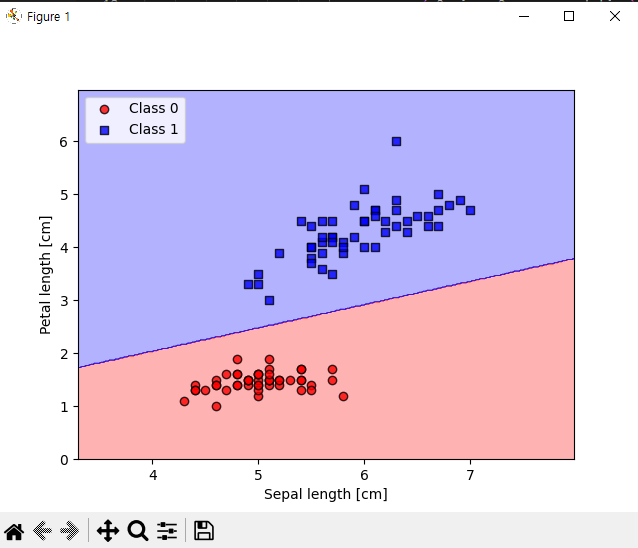
데이터 셋이 정상적으로 출력된것을 확인
학습률에 대한 오차 그래프
머신러닝 알고리즘을 돌리기에 최적화된 학습률을 우리는 설정해야 한다.
너무 값이 낮다면 최적의 값을 찾아가기에 너무 많은 연산을 수행해야 하고
너무 값이 높다면 최적의 값을 넘어가 이상한 weight값과 절편 유닛을 가지고 연산하게 될 수도 있다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(10, 4)) ada1 = AdG.AdalineGD(n_iter=15, eta=0.1).fit(X, y) ax[0].plot(range(1, len(ada1.losses_) + 1), np.log10(ada1.losses_), marker='o') ax[0].set_xlabel('Epochs') ax[0].set_ylabel('log(Mean squared error)') ax[0].set_title('Adaline - Learning rate 0.1') ada2 = AdG.AdalineGD(n_iter=15, eta=0.0001).fit(X, y) ax[1].plot(range(1, len(ada2.losses_) + 1), ada2.losses_, marker='o') ax[1].set_xlabel('Epochs') ax[1].set_ylabel('Mean squared error') ax[1].set_title('Adaline - Learning rate 0.0001') plt.show() | cs |
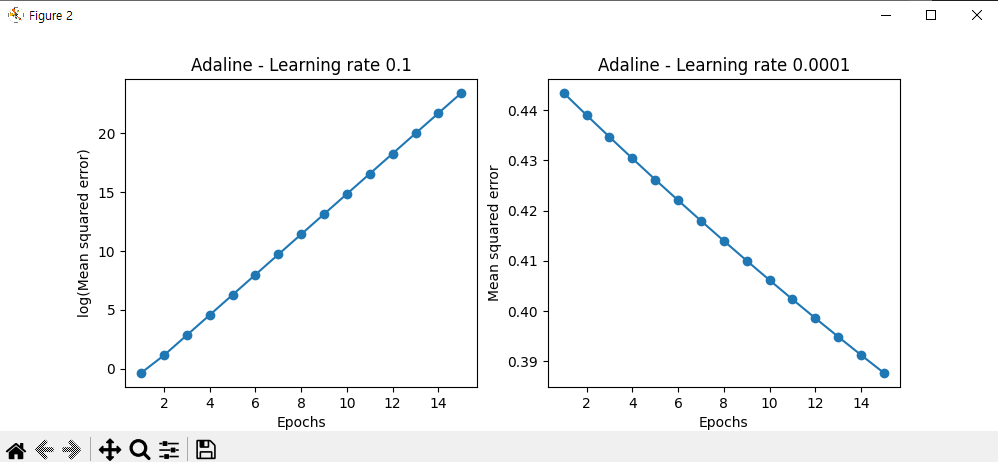
왼쪽의 데이터는 에포크가 늘어면서 손실함수를 최소화하지 못하고 있고 MSE(mean Squared Error)가 더 커지고 있다.
우측은 손실이 감소하지만 알고리즘이 전역 최솟값에 수렴하기까지 더욱 많은 에포크가 필요한것이 보인다.
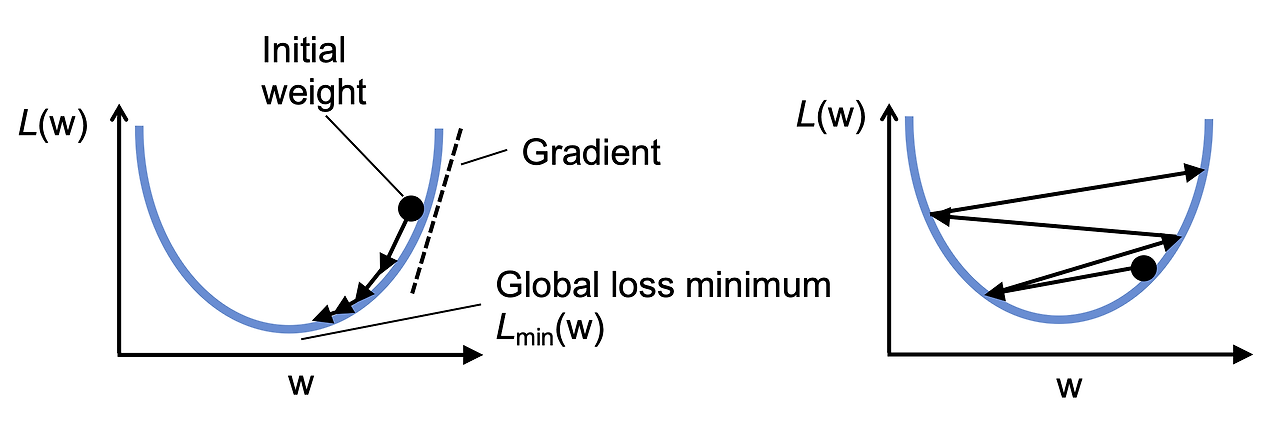
좌측의 그림이 위 코드 결과에서 우측에 대응하는 그래프이고 우측의 화살표가 위로 올라가는 그래프는 코드 결과에서 좌측에 해당하는 그래프이다.
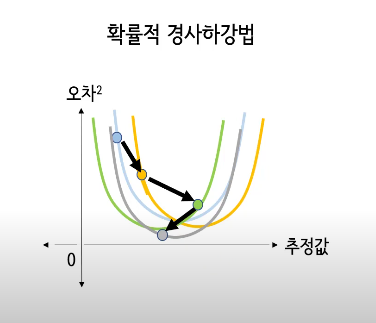
위 문제를 해결하기 위해서 확률적 경사 하강법을 수행하게 되는데 기본적인 경사 하강법에 대한 차이점은 각 훈련 샘플에 대해 점진적으로 파라미터를 업데이트한다는 것이다. 가중치가 더 많이 자주 업데이트되므로 수렴 속도가 빠르고 비선형 손실 함수에서 얕은 지역 최솟값(최적의 값은 아니나 그 구역에서의 값이 최적인 값)을 쉽게 해결할 수 있다는 장점이 있다.
에포크마다 훈련 데이터를 추가시키는 것을 추천한다.