14장
< 데이터 증식 >
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 | fig=plt.figure(figsize=(16,8.5)) # 1열: 바운딩 박스로 자르기 ax=fig.add_subplot(2,5,1) img,attr=celeba_train_dataset[0] ax.set_title('Crop to a \nbounding-box',size=15) ax.imshow(img) ax=fig.add_subplot(2,5,6) img_cropped=transforms.functional.crop(img,50,20,128,128) ax.imshow(img_cropped) # 2열: (수평으로) 뒤집기 ax=fig.add_subplot(2,5,2) img,attr=celeba_train_dataset[1] ax.set_title('Flip (horizontal)',size=15) ax.imshow(img) ax=fig.add_subplot(2,5,7) img_flipped=transforms.functional.hflip(img) ax.imshow(img_flipped) # 3열: 대비 조정 ax=fig.add_subplot(2,5,3) img,attr=celeba_train_dataset[2] ax.set_title('Adjust constrast',size=15) ax.imshow(img) ax=fig.add_subplot(2,5,8) img_adj_contrast=transforms.functional.adjust_contrast( img,contrast_factor=2 ) ax.imshow(img_adj_contrast) # 4열: 명도 조정 ax=fig.add_subplot(2,5,4) img,attr=celeba_train_dataset[3] ax.set_title('Adjust brightness',size=15) ax.imshow(img) ax=fig.add_subplot(2,5,9) img_adj_brightness=transforms.functional.adjust_brightness( img,brightness_factor=1.3 ) ax.imshow(img_adj_brightness) # 5열: 이미지 중앙 자르기 center ax=fig.add_subplot(2,5,5) img,attr=celeba_train_dataset[4] ax.set_title('Center crop\nand resize',size=15) ax.imshow(img) ax=fig.add_subplot(2,5,10) img_center_crop=transforms.functional.center_crop( img,[0.7*218,0.7*178] ) img_resized=transforms.functional.resize( img_center_crop,size=(218,178) ) ax.imshow(img_resized) plt.show() | cs |
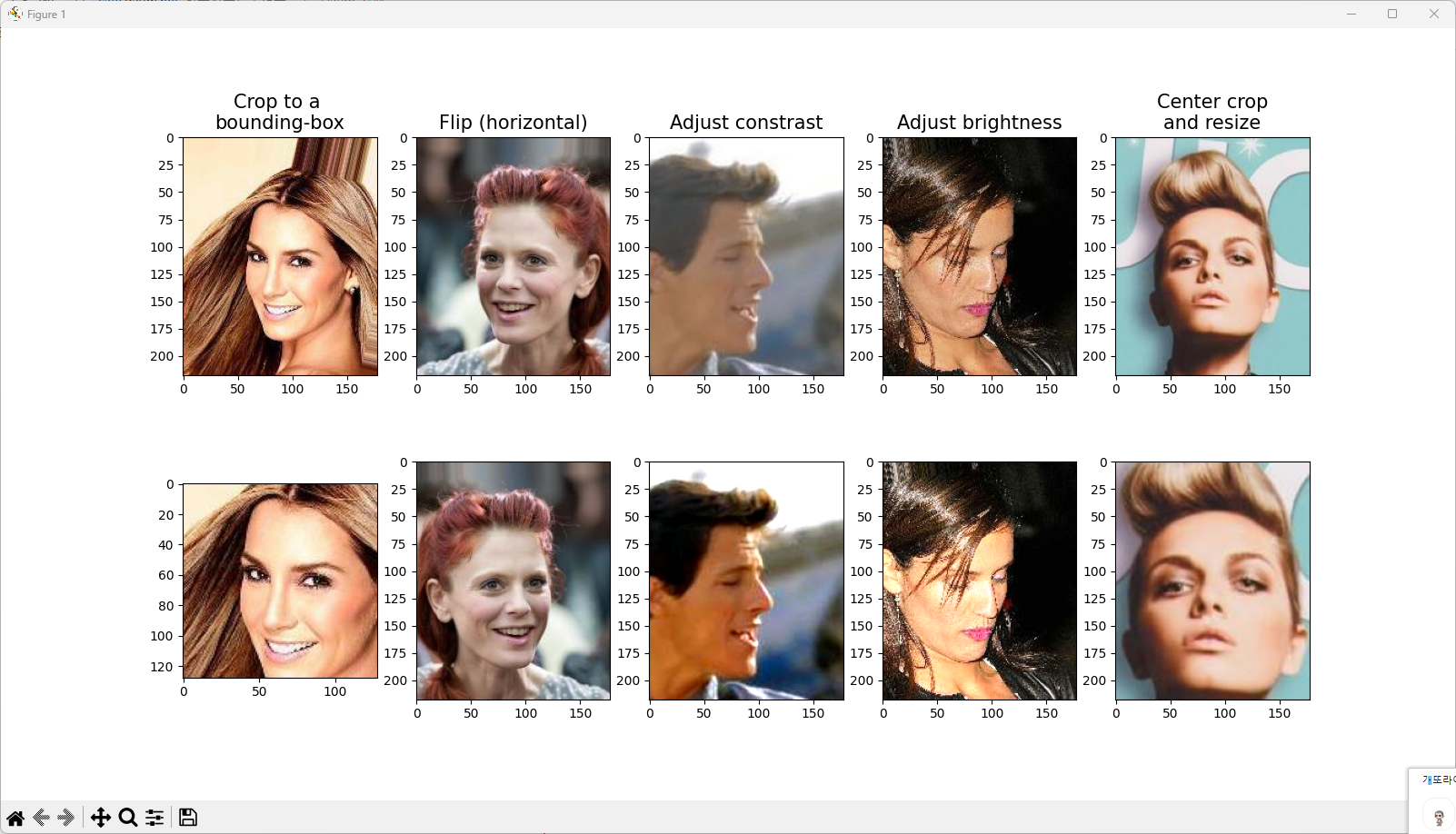
<랜덤>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 | torch.manual_seed(1) # 랜덤 시드 고정 fig=plt.figure(figsize=(14,12)) # 데이터 셋에서 이미지와 속성 반복 for i,(img,attr) in enumerate((celeba_train_dataset)): # 원본 이미지 출력 ax=fig.add_subplot(3,4,i*4+1) ax.imshow(img) if i==0: ax.set_title('Orig. ',size=15) # 랜덤 크롭(Random Crop) ax=fig.add_subplot(3,4,i*4+2) img_transform=transforms.Compose([ transforms.RandomCrop([178,178]) # 178x178 크기로 랜덤하게 잘라냄 ]) img_cropped=img_transform(img) ax.imshow(img_cropped) if i==0: ax.set_title('Step 1: Random crop',size=15) # 랜덤 수평 반전 ax=fig.add_subplot(3,4,i*4+3) img_transform=transforms.Compose([ transforms.RandomHorizontalFlip() # 50% 확률로 이미지를 좌우반전 ]) img_flip=img_transform(img_cropped) ax.imshow(img_flip) if i==0: ax.set_title('Step 2: Random flip',size=15) # 크기 조정 ax=fig.add_subplot(3,4,i*4+4) img_resized=transforms.functional.resize( img_flip,size=(128,128) # 최종 크기를 128x128로 변환 ) ax.imshow(img_resized) if i==0: ax.set_title('Step 3: Resize',size=15) if i==2: # 3번째 이미지까지만 출력 후 종료 break plt.show() | cs |

14장 정리문제
1) 합성곱 신경망에서 합성곱, 풀링, 완전연결레이어의 기능을 설명하라.
- 합성곱 (입력 이미지에서 특징 추출, 가중치를 공유하여 계산량 감소)
- 커널을 사용해 입력 이미지의 국소적 영역 스캔
- 커널을 stride하면서 합성곱 연산 수행
- 활성화 함수를 적용해 비선형성을 추가
- 풀링: 특성맵의 크기를 줄여 연산량 감소
- 최대 풀링: 국소 영역에서 가장 큰 값 선택(지역 불변성 만들음) --> 입력 데이터에 있는 잡음에 좀 더 안정적인 특성 생
- 평균 풀링: 국소 영역에서 평균 값 선택
- 완전연결 (추출된 특징을 이용하여 최종 예측 수행 , 뉴런이 모두 연결되어 있어 고차원 표현 학습 가능 )
- CNN의 마지막 합성곱 층 출력을 Flatten()을 사용해 1D 벡터로 변환
- 완전연결층을 통해 최종 분류 또는 회귀 연산 수행
2) 합성곱 신경망에서 특성맵, 커널, 패딩, 스트라이드의 의미를 설명하라.
- 특성맵 : 입력 데이터에서 각 채널별로 합성곱 연산을 수행하고 행렬 덧셈으로 결과를 합친 결과.
- 합성곱연산: 입력 이미지와 커널을 슬라이딩 윈도우 방식으로 연산하여 각각의 위치에서 특징 추출
- 활성화 함수: 합성곱 연산 후 활성화 함수를 통해 음의 값을 0으로 변환하여 비선형성 추가
- 특성맵 생성: 위에 과정을 통해 나온 결과들이 모여서 특성맵 형성
- 커널: 작은 크기의 행렬. 입력 이미지의 각 부분에 대해 합성곱 연산을 수행하여 특징 추출 --> 커널의 크기와 개수에 따라 특성 맵의 크기와 채널 수 결정됨.
- 패딩: 입력 이미지의 가장 자리에 0 값을 추가하여 입력 크기를 조정하는 방범 --> 패딩을 추가하면 합성곱 연산 후 출력 특성 맵의 크기를 조정할 수 있고 가장자리 정보를 더 잘 처리할 수 있음.
- 스트라이드
- 커널을 적용할 때 이동하는 양 --> 스트라이드는 입력벡터의 크기보다 작은 양수 값이여야 함
4) 601페이지 분류를 위한 손실함수의 종류를 설명하라.
- 이진 크로스 엔트로피: (하나의 출력 유닛을 가진) 이진 분류를 위한 손실함수
- BCELoss 함수(확률을 사용할 때)
- BCEWithLogitLoss(로짓을 사용할 때)
- 범주형 크로스 엔트로피: 다중 분류를 위한 손실 함수 --> torch.nn 모듈에서는 범주형 크로스 엔트로피 손실이 정수로 정답 레이블을 받음.
- NLLoss(확률을 사용할 때)
- CrossEntropyLoss(로짓을 사용할 때)
5) 604페이지의 단계별 객체의 차원의 유도과정을 설명하라.
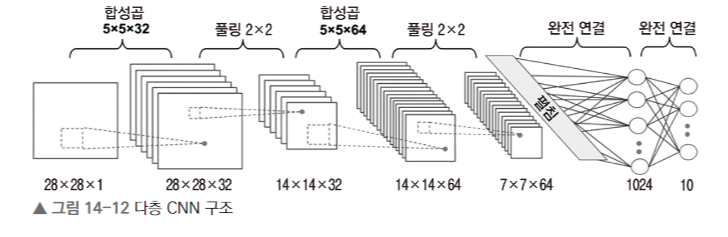
1. 입력 데이터
--> 입력 크기: 28x28x1(흑백이미지), 28x28 픽셀의 1채널이미지가 입력됨.
2. 첫 번째 합성곱 층
--> 5x5 크기인 필터 32개

3. 첫 번째 폴링 층
--> 2x2 최대 풀링, 스트라이드(s)=2, 패딩 없음
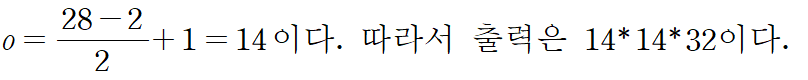
4. 두 번째 합성곱 층
--> 5x5 크기인 필터 64개
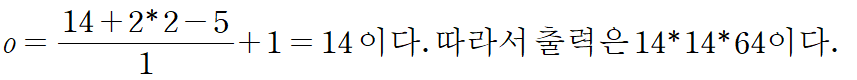
5. 두번 째 폴링 층
--> 2x2 최대 풀링, 스트라이드(s)=2, 패딩없음

6. 완전 연결 (Flatten)
--> 합성곱과 풀링 연산이 끝난 후 특성맵을 일렬로 펴서 완전 연결 층에 전달(1차원 벡터로 변환)
--> 7x7x64=3136 개의 뉴런이 연결됨
7. 완전연결
--> 1024개의 뉴런을 가지는 완전 연결 층을 통과. 각 뉴런은 입력값의 가중치와 편향을 사용해 계산을 함.
8. 출력층
--> 10개의 뉴런(10개의 클래스 예측)으로 연결되어 각 클래스에 대한 확률값 출력
6) 훈련 데이터 증식(augmentation)이란 무엇이고 왜 필요한지 설명하라.
- 훈련 데이터 증식은 기존의 훈련 데이터를 다양한 방식으로 변형하여 데이터의 양을 인위적으로 증가시키는 것.
--> 데이터 증식을 통해 데이터셋의 크기를 늘려 부족한 데이터를 보완함으로써 과대적합을 줄이고 모델의 성능을 높이기 위해서 필요하다.
7) 614페이지에서 파이토치 예제에서 이미지변환을 통하여 데이터를 증식하는 과정을 설명하라.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 | fig=plt.figure(figsize=(16,8.5)) # 1열: 바운딩 박스로 자르기 ax=fig.add_subplot(2,5,1) img,attr=celeba_train_dataset[0] ax.set_title('Crop to a \nbounding-box',size=15) ax.imshow(img) # 원본 이미지 ax=fig.add_subplot(2,5,6) # (y, x, height, width)로 자르기 img_cropped=transforms.functional.crop(img,50,20,128,128) ax.imshow(img_cropped) # 잘린 이미지 출력 # 2열: (수평으로) 뒤집기 ax=fig.add_subplot(2,5,2) img,attr=celeba_train_dataset[1] ax.set_title('Flip (horizontal)',size=15) ax.imshow(img) ax=fig.add_subplot(2,5,7) img_flipped=transforms.functional.hflip(img) # 수평 뒤집기 ax.imshow(img_flipped) # 3열: 대비 조정 ax=fig.add_subplot(2,5,3) img,attr=celeba_train_dataset[2] ax.set_title('Adjust constrast',size=15) ax.imshow(img) ax=fig.add_subplot(2,5,8) # 대비 2배 증가 img_adj_contrast=transforms.functional.adjust_contrast( img,contrast_factor=2 ) ax.imshow(img_adj_contrast) # 4열: 명도 조정 ax=fig.add_subplot(2,5,4) img,attr=celeba_train_dataset[3] ax.set_title('Adjust brightness',size=15) ax.imshow(img) ax=fig.add_subplot(2,5,9) # 명도 1.3배 증가 img_adj_brightness=transforms.functional.adjust_brightness( img,brightness_factor=1.3 ) ax.imshow(img_adj_brightness) # 5열: 이미지 중앙 자르기 center ax=fig.add_subplot(2,5,5) img,attr=celeba_train_dataset[4] ax.set_title('Center crop\nand resize',size=15) ax.imshow(img) ax=fig.add_subplot(2,5,10) # 이미지 중앙에서 70% 크기로 자르기 img_center_crop=transforms.functional.center_crop( img,[0.7*218,0.7*178] ) # 원본 크기로 다시 리사이징 img_resized=transforms.functional.resize( img_center_crop,size=(218,178) ) ax.imshow(img_resized) plt.show() | cs |
원본과 변환후의 영상을 출력하여 증식의 효과를 비교설명하라.
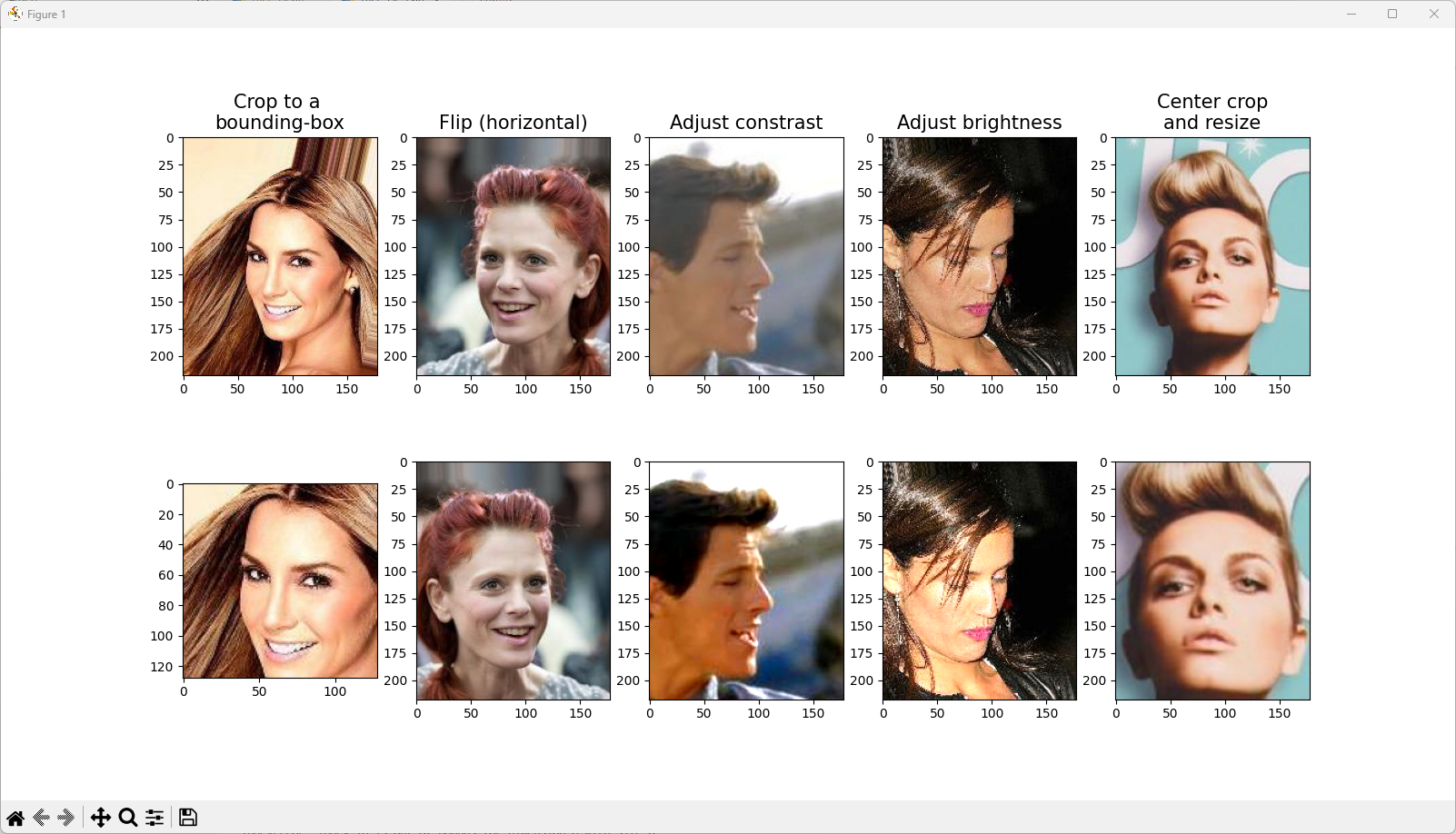
8) 데이터 증식을 위한 이미지변환을 적용할때 변환의 파라미터(회전량, 확대축소비율, 노이즈비율 등)를 랜덤하게 결정하는 이유를 설명하라.
- 모델의 일반화 성능 향상: 학습 데이터에 파라미터를 랜덤하게 결정하면 모델이 특정한 변형에 종속되지 않고 다양한 입력 데이터에서도 높은 성능을 나타내기 때문
- 과적합 방지: 모델이 학습 데이터에만 최적화 되는 것을 막기 위해, 변형된 데이터 샘플을 만들어 학습 데이터의 다양성을 증가시키기 때문
- 데이터 편향 문제 완화: 랜덤 변형을 통해 편향된 데이터 분포를 보완할 수 있기 때문
9) DataLoader 객체에서 훈련데이터를 하나씩 꺼낼때 이미지 변환이 적용되어 데이터 증식의 효과가 발생하는 원리를 설명하라. 원본과 변환후의 영상을 출력하여 증식의 효과를 비교설명하라.
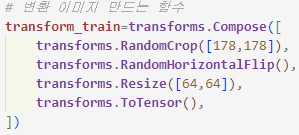
-transforms 모듈을 사용해서 이미지가 DataLoader에 의해 꺼내질 때마다 실시간으로 적용된다.
10) 621페이지 예제에서 실제 모델의 입력데이터, 출력값을 출력하시오. 또 텐서의 차원을 출력하고 설명하시오.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 | # cnn model=nn.Sequential() # 첫번째 합성곱 층 model.add_module( 'conv1', nn.Conv2d( in_channels=3, out_channels=32, kernel_size=3,padding=1 ) ) model.add_module('relu1',nn.ReLU()) # 활성화함수 model.add_module('poo1',nn.MaxPool2d(kernel_size=2)) # 최대 풀링 model.add_module('dropout1',nn.Dropout(p=0.5)) # 드롭아웃 # 두번째 합성곱 층 model.add_module( 'conv2', nn.Conv2d( in_channels=32,out_channels=64, kernel_size=3,padding=1 ) ) model.add_module('relu2',nn.ReLU()) # 활성화 함수 model.add_module('poo2',nn.MaxPool2d(kernel_size=2)) # 최대 풀링 model.add_module('dropout2',nn.Dropout(p=0.5)) # 드롭아웃 # 세번째 합성곱 층 model.add_module( 'conv3', nn.Conv2d( in_channels=64,out_channels=128, kernel_size=3,padding=1 ) ) model.add_module('relu3',nn.ReLU()) # 활성화 함수 model.add_module('poo3',nn.MaxPool2d(kernel_size=2)) # 최대 풀링 # 네번째 합성곱 층 model.add_module( 'conv4', nn.Conv2d( in_channels=128,out_channels=256, kernel_size=3,padding=1 ) ) model.add_module('relu4',nn.ReLU()) # 활성화 함수 model.add_module('pool4',nn.AvgPool2d(kernel_size=8)) # 전역 평균 폴링 model.add_module('flatten',nn.Flatten()) # 평탄화 model.add_module('fc',nn.Linear(256,1)) # 완전연결층 model.add_module('sigmoid',nn.Sigmoid()) # 활성화 함수 x=torch.ones((4,3,64,64)) # 4개의 3채널 64x64 이미지로 구성된 텐서 생성 | cs |
- 입력 데이터: 4개의 3채널 64x64 크기의 이미지를 입력으로 받음.
- 출력값: (4,1) --> 배치 크기 4에 대해 각 입력 이미지에 대해 하나의 클래스에 대한 확률값을 출력하는 텐서
< 텐서의 차원 설명>
1. 입력데이터: (4,3,64,64)
--> 배치 크기 4, 3채널, 이미지 크기: 64x64
2. 풀링
--> 합성곱 3개 층 거쳐서 특성맵 256개
--> 풀링 3개 거쳐서 (4,256,8,8)을 전역 평균 폴링에 전달.
---> 전역 평균 풀링 후 (4,256,1,1)
3. 평탄화: (4,256)
4. 최종 출력: (4,1)
--> (4,1)은 4개의 샘플에 대해 하나의 출력값(확률 또는 클래스)을 예측한다는 말.
11) 621페이지 예제에서 신경망의 훈련에서 손실(훈련,검증)과 정확도(훈련,검증)를 matplotlib을 이용하여 그래프로 그리는 방법을 설명하라.
- 매 에퍽마다 실시간으로 그래프를 업데이트하도록 할것, 교재처럼 훈련종료후 한번에 그리는게 아니고 훈련도중에 실시간으로 업데이트할것 -> 훈련동안 시간의 흐름에 따라 loss의 변화를 확인가능하도록 할것
- 그래프 업데이트 과정을 동영상으로 저장하라.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 | import torchvision import torch from torchvision import transforms from torch.utils.data import DataLoader, Subset import torch.nn as nn import matplotlib.pyplot as plt import numpy as np image_path='./' get_smile=lambda attr:attr[31] # 변환 이미지 만드는 함수 transform_train=transforms.Compose([ transforms.RandomCrop([178,178]), transforms.RandomHorizontalFlip(), transforms.Resize([64,64]), transforms.ToTensor(), ]) # 데이터 증식은 훈련 샘플에만 적용하고 검증 샘플과 테스트 샘플에는 적용하지 않음 # 검증세트와 테스트 세트를 위한 transform 함수 transform=transforms.Compose([ transforms.CenterCrop([178,178]), transforms.Resize([64,64]), transforms.ToTensor(), ]) celeba_train_dataset=torchvision.datasets.CelebA( image_path,split='train', target_type='attr',download=False, # download=False --> 이미 데이터셋이 image_path에 존재한다고 가정하고 다운로드 시도하지 않음 transform=transform_train,target_transform=get_smile ) torch.manual_seed(1) data_loader=DataLoader(celeba_train_dataset,batch_size=2) # transform 함수를 검증 데이터셋과 테스트 데이터셋에 적용 celeba_valid_dataset=torchvision.datasets.CelebA( image_path,split='valid', target_type='attr',download=False, transform=transform,target_transform=get_smile ) celeba_test_dataset=torchvision.datasets.CelebA( image_path,split='test', target_type='attr',download=False, transform=transform,target_transform=get_smile ) celeba_train_dataset=Subset(celeba_train_dataset, torch.arange(16000)) #16000개의 훈련 샘플 celeba_valid_dataset=Subset(celeba_valid_dataset, torch.arange(1000)) #1000개의 훈련 샘플 batch_size=32 torch.manual_seed(1) # 훈련, 검증, 테스트 데이터셋에 대한 데이터 로더 생성성 train_dl=DataLoader(celeba_train_dataset, batch_size,shuffle=True) valid_dl=DataLoader(celeba_valid_dataset, batch_size,shuffle=True) test_dl=DataLoader(celeba_test_dataset, batch_size,shuffle=True) # cnn model=nn.Sequential() # 첫번째 합성곱 층 model.add_module( 'conv1', nn.Conv2d( in_channels=3, out_channels=32, kernel_size=3,padding=1 ) ) model.add_module('relu1',nn.ReLU()) # 활성화함수 model.add_module('poo1',nn.MaxPool2d(kernel_size=2)) # 최대 풀링 model.add_module('dropout1',nn.Dropout(p=0.5)) # 드롭아웃 # 두번째 합성곱 층 model.add_module( 'conv2', nn.Conv2d( in_channels=32,out_channels=64, kernel_size=3,padding=1 ) ) model.add_module('relu2',nn.ReLU()) # 활성화 함수 model.add_module('poo2',nn.MaxPool2d(kernel_size=2)) # 최대 풀링 model.add_module('dropout2',nn.Dropout(p=0.5)) # 드롭아웃 # 세번째 합성곱 층 model.add_module( 'conv3', nn.Conv2d( in_channels=64,out_channels=128, kernel_size=3,padding=1 ) ) model.add_module('relu3',nn.ReLU()) # 활성화 함수 model.add_module('poo3',nn.MaxPool2d(kernel_size=2)) # 최대 풀링 # 네번째 합성곱 층 model.add_module( 'conv4', nn.Conv2d( in_channels=128,out_channels=256, kernel_size=3,padding=1 ) ) model.add_module('relu4',nn.ReLU()) # 활성화 함수 model.add_module('pool4',nn.AvgPool2d(kernel_size=8)) # 전역 평균 폴링 model.add_module('flatten',nn.Flatten()) # 평탄화 model.add_module('fc',nn.Linear(256,1)) # 완전연결층 model.add_module('sigmoid',nn.Sigmoid()) # 활성화 함수 x=torch.ones((4,3,64,64)) # 4개의 3채널 64x64 이미지로 구성된 텐서 생성 loss_fn=nn.BCELoss() optimizer=torch.optim.Adam(model.parameters(),lr=0.001) def train(model,num_epochs,train_dl,valid_dl): loss_hist_train=[0]*num_epochs accuracy_hist_train=[0]*num_epochs loss_hist_valid=[0]*num_epochs accuracy_hist_valid=[0]*num_epochs # 훈련 시작 print("Start train") plt.ion() fig,(ax1,ax2)=plt.subplots(1,2,figsize=(16,4)) for epoch in range(num_epochs): model.train() for x_batch,y_batch in train_dl: pred=model(x_batch)[:,0] loss=loss_fn(pred,y_batch.float()) loss.backward() optimizer.step() optimizer.zero_grad() loss_hist_train[epoch]+=loss.item()*y_batch.size(0) is_correct=((pred>=0.5).float()==y_batch).float() accuracy_hist_train[epoch]+=is_correct.sum() loss_hist_train[epoch]/=len(train_dl.dataset) accuracy_hist_train[epoch]/=len(train_dl.dataset) model.eval() with torch.no_grad(): for x_batch,y_batch in valid_dl: pred=model(x_batch)[:,0] loss=loss_fn(pred,y_batch.float()) loss_hist_valid[epoch]+=loss.item()*y_batch.size(0) is_correct=((pred>=0.5).float()==y_batch).float() accuracy_hist_valid[epoch]+=is_correct.sum() loss_hist_valid[epoch]/=len(valid_dl.dataset) accuracy_hist_valid[epoch]/=len(valid_dl.dataset) print(f'에포크 {epoch+1} 정확도: ' f'{accuracy_hist_train[epoch]:.4f} 검증 정확도: ' f'{accuracy_hist_valid[epoch]:.4f}') x_arr=np.arange(1,epoch+2) ax1.clear() ax1.plot(x_arr, loss_hist_train[:epoch + 1], '-o', label='Train Loss') ax1.plot(x_arr, loss_hist_valid[:epoch + 1], '--<', label='Validation Loss') ax1.legend(fontsize=15) ax1.set_xlabel('Epoch', size=15) ax1.set_ylabel('Loss', size=15) ax2.clear() ax2.plot(x_arr, accuracy_hist_train[:epoch + 1], '-o', label='Train Accuracy') ax2.plot(x_arr, accuracy_hist_valid[:epoch + 1], '--<', label='Validation Accuracy') ax2.legend(fontsize=15) ax2.set_xlabel('Epoch', size=15) ax2.set_ylabel('Accuracy', size=15) # 그래프 갱신 plt.draw() # 그래프 업데이트 plt.pause(0.1) # 잠시 대기 후 다시 그림림 plt.ioff() # 인터랙티브 모드 종료 plt.show() # 그래프 표시 return loss_hist_train,loss_hist_valid,accuracy_hist_train,accuracy_hist_valid def main(): torch.manual_seed(1) num_epochs=30 hist=train(model,num_epochs,train_dl,valid_dl) accuracy_test=0 model.eval() with torch.no_grad(): for x_batch,y_batch in test_dl: pred=model(x_batch)[:,0] is_correct=((pred>=0.5).float()==y_batch).float() accuracy_test+=is_correct.sum() accuracy_test/=len(test_dl.dataset) print(f'테스트 정확도: {accuracy_test:.4f}') pred=model(x_batch)[:,0]*100 fig=plt.figure(figsize=(15,7)) for j in range(10,20): ax=fig.add_subplot(2,5,j-10+1) ax.set_xticks([]); ax.set_yticks([]) ax.imshow(x_batch[j].permute(1,2,0)) if y_batch[j]==1: label='Smile' else: label='Not Smile' ax.text( 0.5,-0.15, f'GT: {label:s}\nPr(Smile)={pred[j]:.0f}%', size=16, horizontalalignment='center', verticalalignment='center', transform=ax.transAxes ) plt.show() if __name__ == "__main__": main() | cs |
12) 621페이지 예제에서 손실(훈련,검증)과 정확도(훈련,검증)를 텐서보드를 이용하여 그래프로 그려보라.
- 매 에퍽마다 실시간으로 그래프를 업데이트하도록 할것, 교재처럼 훈련종료후 한번에 그리는게 아니고 훈련도중에 실시간으로 업데이트할것 -> 훈련동안 시간의 흐름에 따라 loss의 변화를 확인가능하도록 할것
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 | import torchvision import torch from torchvision import transforms from torch.utils.data import DataLoader, Subset from torch.utils.tensorboard import SummaryWriter import torch.nn as nn import matplotlib.pyplot as plt image_path='./' get_smile=lambda attr:attr[31] # 변환 이미지 만드는 함수 transform_train=transforms.Compose([ transforms.RandomCrop([178,178]), transforms.RandomHorizontalFlip(), transforms.Resize([64,64]), transforms.ToTensor(), ]) # 데이터 증식은 훈련 샘플에만 적용하고 검증 샘플과 테스트 샘플에는 적용하지 않음 # 검증세트와 테스트 세트를 위한 transform 함수 transform=transforms.Compose([ transforms.CenterCrop([178,178]), transforms.Resize([64,64]), transforms.ToTensor(), ]) celeba_train_dataset=torchvision.datasets.CelebA( image_path,split='train', target_type='attr',download=False, # download=False --> 이미 데이터셋이 image_path에 존재한다고 가정하고 다운로드 시도하지 않음 transform=transform_train,target_transform=get_smile ) torch.manual_seed(1) data_loader=DataLoader(celeba_train_dataset,batch_size=2) # transform 함수를 검증 데이터셋과 테스트 데이터셋에 적용 celeba_valid_dataset=torchvision.datasets.CelebA( image_path,split='valid', target_type='attr',download=False, transform=transform,target_transform=get_smile ) celeba_test_dataset=torchvision.datasets.CelebA( image_path,split='test', target_type='attr',download=False, transform=transform,target_transform=get_smile ) celeba_train_dataset=Subset(celeba_train_dataset, torch.arange(16000)) #16000개의 훈련 샘플 celeba_valid_dataset=Subset(celeba_valid_dataset, torch.arange(1000)) #1000개의 훈련 샘플 batch_size=32 torch.manual_seed(1) # 훈련, 검증, 테스트 데이터셋에 대한 데이터 로더 생성성 train_dl=DataLoader(celeba_train_dataset, batch_size,shuffle=True) valid_dl=DataLoader(celeba_valid_dataset, batch_size,shuffle=True) test_dl=DataLoader(celeba_test_dataset, batch_size,shuffle=True) # cnn model=nn.Sequential() # 첫번째 합성곱 층 model.add_module( 'conv1', nn.Conv2d( in_channels=3, out_channels=32, kernel_size=3,padding=1 ) ) model.add_module('relu1',nn.ReLU()) # 활성화함수 model.add_module('poo1',nn.MaxPool2d(kernel_size=2)) # 최대 풀링 model.add_module('dropout1',nn.Dropout(p=0.5)) # 드롭아웃 # 두번째 합성곱 층 model.add_module( 'conv2', nn.Conv2d( in_channels=32,out_channels=64, kernel_size=3,padding=1 ) ) model.add_module('relu2',nn.ReLU()) # 활성화 함수 model.add_module('poo2',nn.MaxPool2d(kernel_size=2)) # 최대 풀링 model.add_module('dropout2',nn.Dropout(p=0.5)) # 드롭아웃 # 세번째 합성곱 층 model.add_module( 'conv3', nn.Conv2d( in_channels=64,out_channels=128, kernel_size=3,padding=1 ) ) model.add_module('relu3',nn.ReLU()) # 활성화 함수 model.add_module('poo3',nn.MaxPool2d(kernel_size=2)) # 최대 풀링 # 네번째 합성곱 층 model.add_module( 'conv4', nn.Conv2d( in_channels=128,out_channels=256, kernel_size=3,padding=1 ) ) model.add_module('relu4',nn.ReLU()) # 활성화 함수 model.add_module('pool4',nn.AvgPool2d(kernel_size=8)) # 전역 평균 폴링 model.add_module('flatten',nn.Flatten()) # 평탄화 model.add_module('fc',nn.Linear(256,1)) # 완전연결층 model.add_module('sigmoid',nn.Sigmoid()) # 활성화 함수 x=torch.ones((4,3,64,64)) # 4개의 3채널 64x64 이미지로 구성된 텐서 생성 loss_fn=nn.BCELoss() optimizer=torch.optim.Adam(model.parameters(),lr=0.001) def train(model,num_epochs,train_dl,valid_dl): # TensorBoard writer 초기화 writer = SummaryWriter(log_dir='logs/celeba') loss_hist_train=[0]*num_epochs accuracy_hist_train=[0]*num_epochs loss_hist_valid=[0]*num_epochs accuracy_hist_valid=[0]*num_epochs # 훈련 시작 print("Start train") plt.ion() fig,(ax1,ax2)=plt.subplots(1,2,figsize=(16,4)) for epoch in range(num_epochs): model.train() for x_batch,y_batch in train_dl: pred=model(x_batch)[:,0] loss=loss_fn(pred,y_batch.float()) loss.backward() optimizer.step() optimizer.zero_grad() loss_hist_train[epoch]+=loss.item()*y_batch.size(0) is_correct=((pred>=0.5).float()==y_batch).float() accuracy_hist_train[epoch]+=is_correct.sum() loss_hist_train[epoch]/=len(train_dl.dataset) accuracy_hist_train[epoch]/=len(train_dl.dataset) model.eval() with torch.no_grad(): for x_batch,y_batch in valid_dl: pred=model(x_batch)[:,0] loss=loss_fn(pred,y_batch.float()) loss_hist_valid[epoch]+=loss.item()*y_batch.size(0) is_correct=((pred>=0.5).float()==y_batch).float() accuracy_hist_valid[epoch]+=is_correct.sum() loss_hist_valid[epoch]/=len(valid_dl.dataset) accuracy_hist_valid[epoch]/=len(valid_dl.dataset) print(f'에포크 {epoch+1} 정확도: ' f'{accuracy_hist_train[epoch]:.4f} 검증 정확도: ' f'{accuracy_hist_valid[epoch]:.4f}') # TensorBoard에 기록 writer.add_scalar("Loss/Train", loss_hist_train[epoch], epoch) writer.add_scalar("Loss/Valid", loss_hist_valid[epoch], epoch) writer.add_scalar("Accuracy/Train", accuracy_hist_train[epoch], epoch) writer.add_scalar("Accuracy/Valid", accuracy_hist_valid[epoch], epoch) writer.close() # 훈련이 끝난 후 writer 종료 return loss_hist_train,loss_hist_valid,accuracy_hist_train,accuracy_hist_valid def main(): torch.manual_seed(1) num_epochs=30 hist=train(model,num_epochs,train_dl,valid_dl) accuracy_test=0 model.eval() with torch.no_grad(): for x_batch,y_batch in test_dl: pred=model(x_batch)[:,0] is_correct=((pred>=0.5).float()==y_batch).float() accuracy_test+=is_correct.sum() accuracy_test/=len(test_dl.dataset) print(f'테스트 정확도: {accuracy_test:.4f}') pred=model(x_batch)[:,0]*100 fig=plt.figure(figsize=(15,7)) for j in range(10,20): ax=fig.add_subplot(2,5,j-10+1) ax.set_xticks([]); ax.set_yticks([]) ax.imshow(x_batch[j].permute(1,2,0)) if y_batch[j]==1: label='Smile' else: label='Not Smile' ax.text( 0.5,-0.15, f'GT: {label:s}\nPr(Smile)={pred[j]:.0f}%', size=16, horizontalalignment='center', verticalalignment='center', transform=ax.transAxes ) plt.show() if __name__ == "__main__": main() | cs |
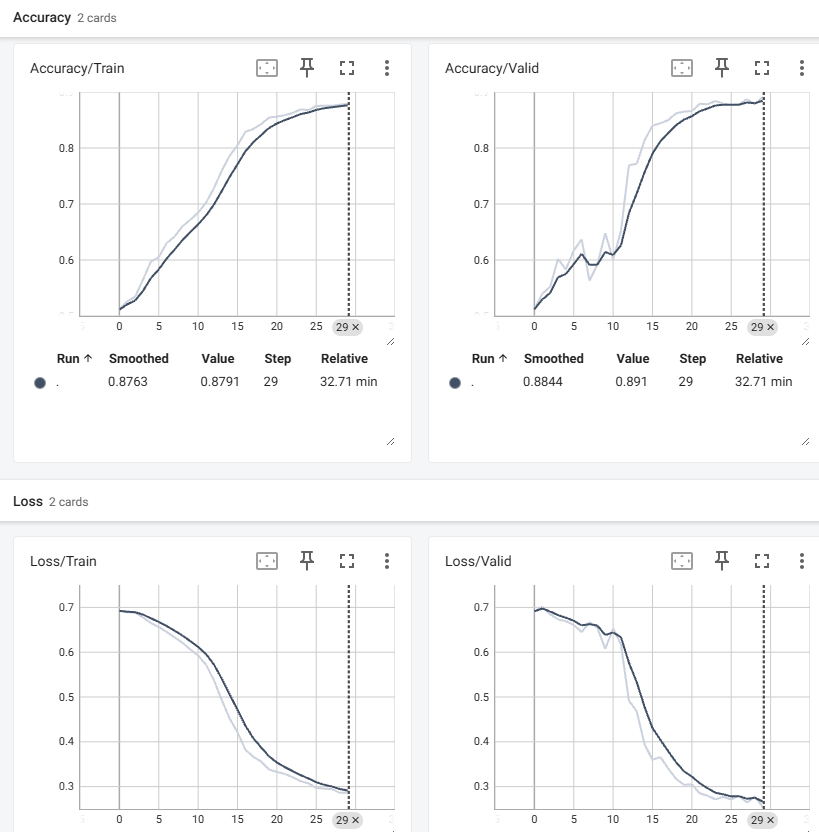
13) 11~13장 mnist예제의 MLP를 이용한 영상분류와 14장의 CNN을 이용한 영상분류의 차이점을 설명하라.
- MLP
- 입력이미지를 1차원 벡터로 변환 처리하고 여러 개의 은닉층을 거쳐 최종 분류를 수행한다.
- CNN
- 합성곱 연산을 사용하여 이미지의 특성을 추출하고 풀링 연산을 사용해 차원을 축소하고 불필요한 정보를 제거한 다음 완전 연결 층을 사용하여 최종 분류를 수행한다.
==> MLP는 입력데이터를 1차원 벡터로 변환한다음 사용하지만 CNN은 2D 이미지를 그대로 사용한다.
==> MLP는 각 픽셀을 개별적으로 학습하지만 CNN은 합성곱을 사용하여 국소적 특징을 학습한다.
==> MLP는 이미지의 픽셀을 단순한 숫자로 인식하기 때문에 공간적인 구조를 무시하는 단점이 있고 CNN은 합성곱과 풀링 연산을 활용하여 이미지의 공간적 특성을 보존하며 학습하므로 영상분류에 MLP보다 더 적합하다
14) 손실 또는 정확도 그래프를 이용하여 과적합 여부를 판단하는 방법을 설명하라.
- 과접합은 모델이 훈련 데이터에 과하게 맞춰져 검증 성능이 떨어지는 현상이다. 손실 그래프에서 훈련 손실을 계속 감소하지만 검증 손실이 일정 에포크 이후부터 증가하는 패턴을 보이면 과적합으로 판단할 수 있다. 또 정확도 그래프에서는 훈련 정확도는 계속 증가하지만 검증 정확도가 일정 수준 이후 정체되거나 감소하는 패턴을 보이면 과적합으로 판단할 수 있다.