1. SAFDNet
https://github.com/zhanggang001/HEDNet

목적: nuScenes 데이터셋으로 학습된 SAFDNet 모델을 그대로 활용해, Waymo 포인트클라우드에 대해 추론 및 시각화를 수행하고 모델의 일반화 성능을 평가
구성파일:safdnet_20e_nuscenes.yaml
- CLASS_NAMES: 10개
POINT_FEATURE_ENCODING: absolute_coordinates_encoding (x,y,z,intensity + dummy timestamp)
DATA_CONFIG: nuScenes dataset 설정
MODEL: TransFusion + SparseHEDNet2D + SparseTransFusionHead 등
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 | CLASS_NAMES: ['car','truck', 'construction_vehicle', 'bus', 'trailer', 'barrier', 'motorcycle', 'bicycle', 'pedestrian', 'traffic_cone'] DATA_CONFIG: _BASE_CONFIG_: cfgs/dataset_configs/nuscenes_dataset.yaml POINT_CLOUD_RANGE: [-54.0, -54.0, -5.0, 54.0, 54.0, 3.0] DATA_AUGMENTOR: DISABLE_AUG_LIST: ['placeholder'] AUG_CONFIG_LIST: - NAME: gt_sampling DB_INFO_PATH: - nuscenes_dbinfos_10sweeps_withvelo.pkl USE_SHARED_MEMORY: True DB_DATA_PATH: - nuscenes_10sweeps_withvelo_lidar.npy PREPARE: { filter_by_min_points: [ 'car:5','truck:5', 'construction_vehicle:5', 'bus:5', 'trailer:5', 'barrier:5', 'motorcycle:5', 'bicycle:5', 'pedestrian:5', 'traffic_cone:5' ], } SAMPLE_GROUPS: [ 'car:2','truck:3', 'construction_vehicle:7', 'bus:4', 'trailer:6', 'barrier:2', 'motorcycle:6', 'bicycle:6', 'pedestrian:2', 'traffic_cone:2' ] NUM_POINT_FEATURES: 5 DATABASE_WITH_FAKELIDAR: False REMOVE_EXTRA_WIDTH: [0.0, 0.0, 0.0] LIMIT_WHOLE_SCENE: True - NAME: random_world_flip ALONG_AXIS_LIST: ['x', 'y'] - NAME: random_world_rotation WORLD_ROT_ANGLE: [-0.78539816, 0.78539816] - NAME: random_world_scaling WORLD_SCALE_RANGE: [0.9, 1.1] - NAME: random_world_translation NOISE_TRANSLATE_STD: [0.5, 0.5, 0.5] DATA_PROCESSOR: - NAME: mask_points_and_boxes_outside_range REMOVE_OUTSIDE_BOXES: True - NAME: shuffle_points SHUFFLE_ENABLED: { 'train': True, 'test': True } - NAME: transform_points_to_voxels_placeholder VOXEL_SIZE: [0.3, 0.3, 8.0] MODEL: NAME: TransFusion VFE: NAME: DynPillarVFE WITH_DISTANCE: False USE_ABSLOTE_XYZ: True USE_NORM: True NUM_FILTERS: [128, 128] BACKBONE_3D: NAME: SparseHEDNet2D SED_FEATURE_DIM: 128 SED_NUM_LAYERS: 6 SED_NUM_SBB: [2, 1, 1] SED_DOWN_STRIDE: [1, 2, 2] SED_DOWN_KERNEL_SIZE: [3, 3, 3] AFD_FEATURE_DIM: 128 AFD_NUM_LAYERS: 1 AFD_NUM_SBB: [4, 4, 4] AFD_DOWN_STRIDE: [1, 2, 2] AFD_DOWN_KERNEL_SIZE: [3, 3, 3] AFD: True FEATMAP_STRIDE: 2 DETACH_FEATURE: True FG_THRESHOLD: 0.3 GREOUP_POOLING_KERNEL_SIZE: [9, 15, 7, 7] # NDS 70.7~71.1 GROUP_CLASS_NAMES: [ ['car', 'truck', 'construction_vehicle'], ['bus', 'trailer'], ['barrier', 'motorcycle', 'bicycle', 'pedestrian', 'traffic_cone'], ] DENSE_HEAD: NAME: SparseTransFusionHead CLASS_AGNOSTIC: False USE_BIAS_BEFORE_NORM: False USE_TENSOR_MASK: True INPUT_FEATURES: 128 NUM_PROPOSALS: 200 # set it to 300 when performing inference on the test set (inference only) HIDDEN_CHANNEL: 128 NUM_CLASSES: 10 NUM_HEADS: 8 NMS_KERNEL_SIZE: 3 FFN_CHANNEL: 256 DROPOUT: 0.1 BN_MOMENTUM: 0.1 ACTIVATION: relu NUM_HM_CONV: 2 SEPARATE_HEAD_CFG: HEAD_ORDER: ['center', 'height', 'dim', 'rot', 'vel'] HEAD_DICT: { 'center': {'out_channels': 2, 'num_conv': 2}, 'height': {'out_channels': 1, 'num_conv': 2}, 'dim': {'out_channels': 3, 'num_conv': 2}, 'rot': {'out_channels': 2, 'num_conv': 2}, 'vel': {'out_channels': 2, 'num_conv': 2}, } TARGET_ASSIGNER_CONFIG: DATASET: nuScenes FEATURE_MAP_STRIDE: 2 GAUSSIAN_OVERLAP: 0.1 MIN_RADIUS: 2 HUNGARIAN_ASSIGNER: cls_cost: {'gamma': 2.0, 'alpha': 0.25, 'weight': 0.15} reg_cost: {'weight': 0.25} iou_cost: {'weight': 0.25} LOSS_CONFIG: LOSS_WEIGHTS: { 'cls_weight': 1.0, 'bbox_weight': 0.25, 'hm_weight': 1.0, 'code_weights': [1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 0.2, 0.2] } LOSS_CLS: use_sigmoid: True gamma: 2.0 alpha: 0.25 LOSS_IOU: False LOSS_IOU_REG: False POST_PROCESSING: SCORE_THRESH: 0.0 POST_CENTER_RANGE: [-61.2, -61.2, -10.0, 61.2, 61.2, 10.0] USE_IOU_TO_RECTIFY_SCORE: False IOU_RECTIFIER: [0.5] NMS_CONFIG: NMS_TYPE: nms_gpu NMS_THRESH: 0.2 NMS_PRE_MAXSIZE: 1000 NMS_POST_MAXSIZE: 100 SCORE_THRES: 0. POST_PROCESSING: RECALL_THRESH_LIST: [0.3, 0.5, 0.7] SCORE_THRESH: 0.1 OUTPUT_RAW_SCORE: False EVAL_METRIC: kitti OPTIMIZATION: BATCH_SIZE_PER_GPU: 2 NUM_EPOCHS: 20 OPTIMIZER: adam_onecycle LR: 0.003 WEIGHT_DECAY: 0.05 MOMENTUM: 0.9 MOMS: [0.95, 0.85] PCT_START: 0.4 DIV_FACTOR: 10 DECAY_STEP_LIST: [35, 45] LR_DECAY: 0.1 LR_CLIP: 0.0000001 LR_WARMUP: False WARMUP_EPOCH: 1 GRAD_NORM_CLIP: 35 LOSS_SCALE_FP16: 4.0 HOOK: DisableAugmentationHook: DISABLE_AUG_LIST: ['gt_sampling'] NUM_LAST_EPOCHS: 4 # yield similar results if set it to 5 following mmdetection3d | cs |
추론: wsl에서 GUI를 못써서 추론결과를 .npy로 저장하여 window에서 시각화
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 | import argparse import glob from pathlib import Path import os try: import open3d from visual_utils import open3d_vis_utils as V OPEN3D_FLAG = True except: import mayavi.mlab as mlab from visual_utils import visualize_utils as V OPEN3D_FLAG = False import numpy as np import torch from pcdet.config import cfg, cfg_from_yaml_file from pcdet.datasets import DatasetTemplate from pcdet.models import build_network, load_data_to_gpu from pcdet.utils import common_utils class DemoDataset(DatasetTemplate): def __init__(self, dataset_cfg, class_names, training=True, root_path=None, logger=None, ext='.bin'): """ Args: root_path: dataset_cfg: class_names: training: logger: """ super().__init__( dataset_cfg=dataset_cfg, class_names=class_names, training=training, root_path=root_path, logger=logger ) self.root_path = root_path self.ext = ext data_file_list = glob.glob(str(root_path / f'*{self.ext}')) if self.root_path.is_dir() else [self.root_path] data_file_list.sort() self.sample_file_list = data_file_list def __len__(self): return len(self.sample_file_list) def __getitem__(self, index): if self.ext == '.bin': points = np.fromfile(self.sample_file_list[index], dtype=np.float32).reshape(-1, 4) elif self.ext == '.npy': points = np.load(self.sample_file_list[index]) else: raise NotImplementedError input_dict = { 'points': points, 'frame_id': index, } data_dict = self.prepare_data(data_dict=input_dict) return data_dict def parse_config(): parser = argparse.ArgumentParser(description='arg parser') parser.add_argument('--cfg_file', type=str, default='cfgs/kitti_models/second.yaml', help='specify the config for demo') parser.add_argument('--data_path', type=str, default='demo_data', help='specify the point cloud data file or directory') parser.add_argument('--ckpt', type=str, default=None, help='specify the pretrained model') parser.add_argument('--ext', type=str, default='.bin' , help='specify the extension of your point cloud data file') args = parser.parse_args() cfg_from_yaml_file(args.cfg_file, cfg) return args, cfg def main(): args, cfg = parse_config() logger = common_utils.create_logger() logger.info('-----------------Quick Demo of OpenPCDet-------------------------') demo_dataset = DemoDataset( dataset_cfg=cfg.DATA_CONFIG, class_names=cfg.CLASS_NAMES, training=False, root_path=Path(args.data_path), ext=args.ext, logger=logger ) logger.info(f'Total number of samples: \t{len(demo_dataset)}') model = build_network(model_cfg=cfg.MODEL, num_class=len(cfg.CLASS_NAMES) , dataset=demo_dataset) model.load_params_from_file(filename=args.ckpt, logger=logger, to_cpu=True) model.cuda() model.eval() os.makedirs('outputs', exist_ok=True) with torch.no_grad(): for idx, data_dict in enumerate(demo_dataset): logger.info(f'Visualized sample index: \t{idx + 1}') data_dict = demo_dataset.collate_batch([data_dict]) load_data_to_gpu(data_dict) pred_dicts, _ = model.forward(data_dict) pred_labels = pred_dicts[0]['pred_labels'].cpu().numpy() pred_labels = np.clip(pred_labels, 0, 9) # 저장코드 window에서 시각화 하기위해 np.save(f'outputs/{idx:04d}_points.npy', data_dict['points'][:, 1:].cpu().numpy()) np.save(f'outputs/{idx:04d}_pred_boxes.npy', pred_dicts[0]['pred_boxes'].cpu().numpy()) np.save(f'outputs/{idx:04d}_pred_scores.npy', pred_dicts[0]['pred_scores'].cpu().numpy()) np.save(f'outputs/{idx:04d}_pred_labels.npy', pred_labels) print(f"Saved frame {idx:04d} to outputs/") # 시각화 (window에서 ) # V.draw_scenes( # points=data_dict['points'][0, :, 1:], # batch dim 제거 # ref_boxes=pred_dicts[0]['pred_boxes'].cpu(), # ref_scores=pred_dicts[0]['pred_scores'].cpu(), # ref_labels=torch.from_numpy(pred_labels) # 다시 텐서로 # ) # if not OPEN3D_FLAG: # mlab.show(stop=True) logger.info('Demo done.') if __name__ == '__main__': main() | cs |
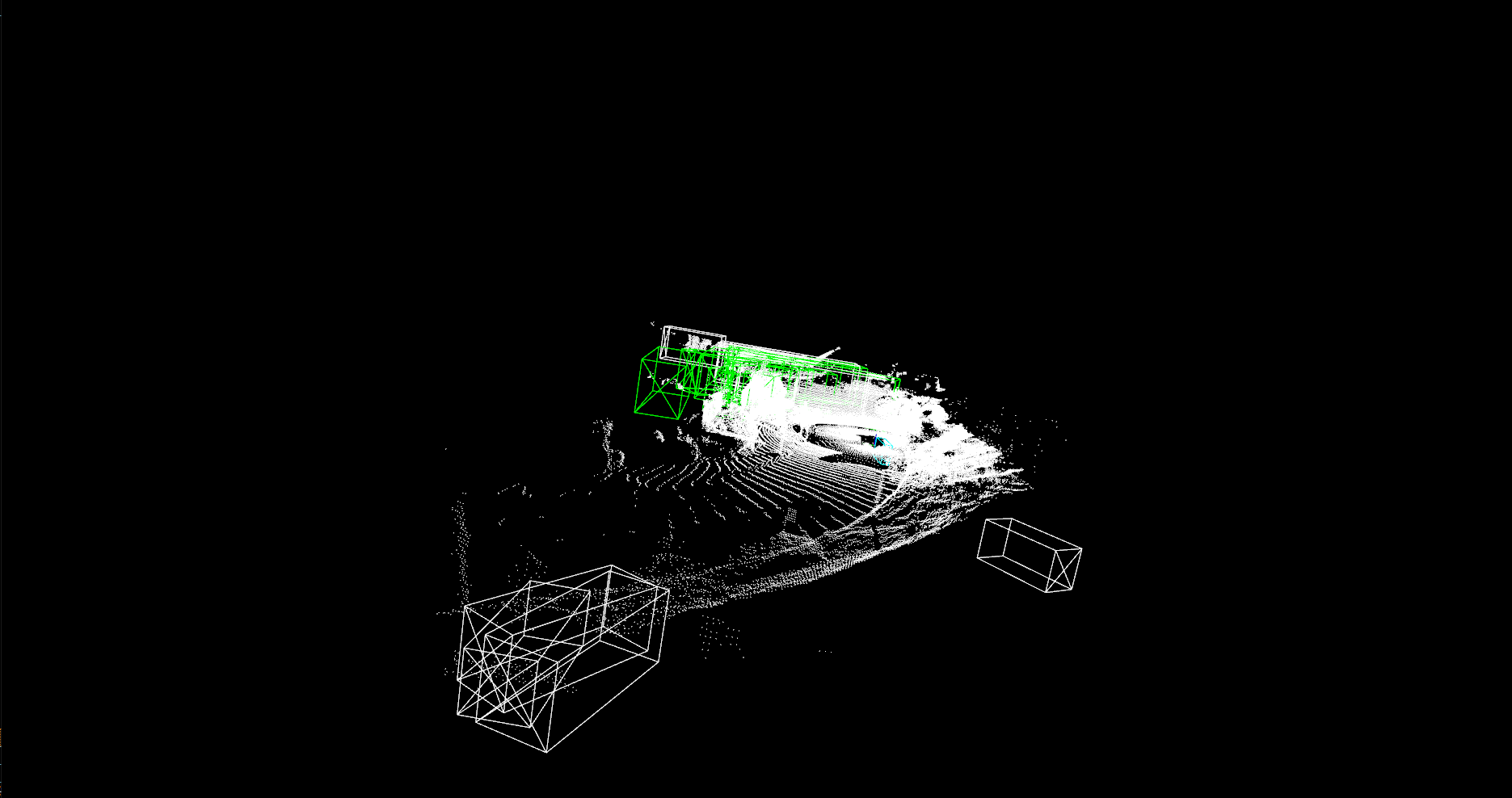
시각화: SAFD모델
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 | import numpy as np from pathlib import Path from tools.visual_utils import open3d_vis_utils as V # nuScenes → Waymo 클래스 매핑 nuscenes_to_waymo_map = { 0: 0, # car → Vehicle 1: 0, # truck → Vehicle 2: 0, # bus → Vehicle 3: 0, # trailer → Vehicle 4: 0, # construction_vehicle → Vehicle 5: 1, # pedestrian → Pedestrian 6: 2, # motorcycle → Cyclist 7: 2, # bicycle → Cyclist 8: None, # traffic cone → skip 9: None, # barrier → skip } frame_id = "0008" # 경로 설정 BASE_DIR = Path("C:/Users/C/outputs") points_path = BASE_DIR / f"{frame_id}_points.npy" boxes_path = BASE_DIR / f"{frame_id}_pred_boxes.npy" scores_path = BASE_DIR / f"{frame_id}_pred_scores.npy" labels_path = BASE_DIR / f"{frame_id}_pred_labels.npy" # 파일 불러오기 points = np.load(points_path) # (N, 3) → 이미 nuScenes 좌표계 pred_boxes = np.load(boxes_path) pred_scores = np.load(scores_path) pred_labels = np.load(labels_path) print(f"[INFO] 로드된 points shape: {points.shape}") # 라벨 매핑 mapped_boxes, mapped_scores, mapped_labels = [], [], [] for i, cls in enumerate(pred_labels): mapped_cls = nuscenes_to_waymo_map.get(int(cls), None) if mapped_cls is not None: mapped_boxes.append(pred_boxes[i]) mapped_scores.append(pred_scores[i]) mapped_labels.append(mapped_cls) if len(mapped_boxes) > 0: mapped_boxes = np.stack(mapped_boxes) mapped_scores = np.array(mapped_scores) mapped_labels = np.array(mapped_labels) print(f"[INFO] 시각화 대상 박스 수: {len(mapped_boxes)}") # 시각화 V.draw_scenes( points=points, # nuScenes 좌표계 (N, 3) ref_boxes=mapped_boxes, ref_scores=mapped_scores, ref_labels=mapped_labels ) else: print("시각화할 박스가 없습니다.") | cs |


2. HEDNET
목적: nuScenes 데이터셋으로 학습된 HEDNET 모델을 그대로 활용해, Waymo 포인트클라우드에 대해 추론 및 시각화를 수행하고 모델의 일반화 성능을 평가
구성파일: hednet_20e_nusences.yaml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 | CLASS_NAMES: ['car','truck', 'construction_vehicle', 'bus', 'trailer', 'barrier', 'motorcycle', 'bicycle', 'pedestrian', 'traffic_cone'] DATA_CONFIG: _BASE_CONFIG_: cfgs/dataset_configs/nuscenes_dataset.yaml POINT_CLOUD_RANGE: [-54.0, -54.0, -5.0, 54.0, 54.0, 3.0] DATA_AUGMENTOR: DISABLE_AUG_LIST: ['placeholder'] AUG_CONFIG_LIST: - NAME: gt_sampling DB_INFO_PATH: - nuscenes_dbinfos_10sweeps_withvelo.pkl USE_SHARED_MEMORY: True DB_DATA_PATH: - nuscenes_10sweeps_withvelo_lidar.npy PREPARE: { filter_by_min_points: [ 'car:5','truck:5', 'construction_vehicle:5', 'bus:5', 'trailer:5', 'barrier:5', 'motorcycle:5', 'bicycle:5', 'pedestrian:5', 'traffic_cone:5' ], } SAMPLE_GROUPS: [ 'car:2','truck:3', 'construction_vehicle:7', 'bus:4', 'trailer:6', 'barrier:2', 'motorcycle:6', 'bicycle:6', 'pedestrian:2', 'traffic_cone:2' ] NUM_POINT_FEATURES: 5 DATABASE_WITH_FAKELIDAR: False REMOVE_EXTRA_WIDTH: [0.0, 0.0, 0.0] LIMIT_WHOLE_SCENE: True - NAME: random_world_flip ALONG_AXIS_LIST: ['x', 'y'] - NAME: random_world_rotation WORLD_ROT_ANGLE: [-0.78539816, 0.78539816] - NAME: random_world_scaling WORLD_SCALE_RANGE: [0.9, 1.1] - NAME: random_world_translation NOISE_TRANSLATE_STD: [0.5, 0.5, 0.5] DATA_PROCESSOR: - NAME: mask_points_and_boxes_outside_range REMOVE_OUTSIDE_BOXES: True - NAME: shuffle_points SHUFFLE_ENABLED: { 'train': True, 'test': True } - NAME: transform_points_to_voxels_placeholder VOXEL_SIZE: [0.3, 0.3, 8.0] MODEL: NAME: TransFusion VFE: NAME: DynPillarVFE WITH_DISTANCE: False USE_ABSLOTE_XYZ: True USE_NORM: True NUM_FILTERS: [128, 128] BACKBONE_3D: NAME: HEDNet2D SED_FEATURE_DIM: 128 SED_NUM_LAYERS: 6 SED_NUM_SBB: [2, 1, 1] SED_DOWN_STRIDE: [1, 2, 2] SED_DOWN_KERNEL_SIZE: [3, 3, 3] DED_FEATURE_DIM: 128 DED_NUM_LAYERS: 2 DED_NUM_SBB: [2, 1, 1] DED_DOWN_STRIDE: [1, 2, 2] DENSE_HEAD: NAME: TransFusionHead CLASS_AGNOSTIC: False USE_BIAS_BEFORE_NORM: False INPUT_FEATURES: 128 NUM_PROPOSALS: 200 # set it to 300 when performing inference on the test set (inference only) HIDDEN_CHANNEL: 128 NUM_CLASSES: 10 NUM_HEADS: 8 NMS_KERNEL_SIZE: 3 FFN_CHANNEL: 256 DROPOUT: 0.1 BN_MOMENTUM: 0.1 ACTIVATION: relu NUM_HM_CONV: 2 SEPARATE_HEAD_CFG: HEAD_ORDER: ['center', 'height', 'dim', 'rot', 'vel', 'iou'] HEAD_DICT: { 'center': {'out_channels': 2, 'num_conv': 2}, 'height': {'out_channels': 1, 'num_conv': 2}, 'dim': {'out_channels': 3, 'num_conv': 2}, 'rot': {'out_channels': 2, 'num_conv': 2}, 'vel': {'out_channels': 2, 'num_conv': 2}, 'iou': {'out_channels': 1, 'num_conv': 2}, } TARGET_ASSIGNER_CONFIG: DATASET: nuScenes FEATURE_MAP_STRIDE: 2 GAUSSIAN_OVERLAP: 0.1 MIN_RADIUS: 2 HUNGARIAN_ASSIGNER: cls_cost: {'gamma': 2.0, 'alpha': 0.25, 'weight': 0.15} reg_cost: {'weight': 0.25} iou_cost: {'weight': 0.25} LOSS_CONFIG: LOSS_WEIGHTS: { 'cls_weight': 1.0, 'bbox_weight': 0.25, 'hm_weight': 1.0, 'iou_weight': 0.5, 'iou_reg_weight': 0.5, 'code_weights': [1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 0.2, 0.2] } LOSS_CLS: use_sigmoid: True gamma: 2.0 alpha: 0.25 LOSS_IOU: True LOSS_IOU_REG: True POST_PROCESSING: SCORE_THRESH: 0.0 POST_CENTER_RANGE: [-61.2, -61.2, -10.0, 61.2, 61.2, 10.0] USE_IOU_TO_RECTIFY_SCORE: True IOU_RECTIFIER: [0.5] NMS_CONFIG: NMS_TYPE: nms_gpu NMS_THRESH: 0.2 NMS_PRE_MAXSIZE: 1000 NMS_POST_MAXSIZE: 100 SCORE_THRES: 0. POST_PROCESSING: RECALL_THRESH_LIST: [0.3, 0.5, 0.7] SCORE_THRESH: 0.1 OUTPUT_RAW_SCORE: False EVAL_METRIC: kitti OPTIMIZATION: BATCH_SIZE_PER_GPU: 2 NUM_EPOCHS: 20 OPTIMIZER: adam_onecycle LR: 0.003 WEIGHT_DECAY: 0.05 MOMENTUM: 0.9 MOMS: [0.95, 0.85] PCT_START: 0.4 DIV_FACTOR: 10 DECAY_STEP_LIST: [35, 45] LR_DECAY: 0.1 LR_CLIP: 0.0000001 LR_WARMUP: False WARMUP_EPOCH: 1 GRAD_NORM_CLIP: 35 LOSS_SCALE_FP16: 4.0 HOOK: DisableAugmentationHook: DISABLE_AUG_LIST: ['gt_sampling'] NUM_LAST_EPOCHS: 4 # yield similar results if set it to 5 following mmdetection3d | cs |
시각화 결과


3. Cross‐Dataset 결과
| 문제 | 원인 분석 |
| 일부 박스 위치 불일치 | nuScenes 학습 시 사용된 sensor 위치·자세 정보 미반영 |
| 포인트 피처 차원 불일치 | timestamp (추가 채널) → dummy데이터 0으로 처리 |
| 클래스 분류 성능 저하 | 학습된 클래스 분포와 Waymo 분포 차이 |
1)라이다 스캔 ,해상도 차이
nuScenes: 32-beam, 360° , 1Hz -> 포인트수 적음
Waymo: 64-beam, 최대 10Hz, 더 치밀한 스캔
→ 포인트 분포(density)·높낮이 분포(elevation)가 완전히 달라서, 같은 VFE(DynPillarVFE) 입장에선 “nuScenes 스타일의 포인트”만 보도록 학습돼 있습니다
2)좌표계·전처리 차이
- nuScenes 모델의 cfgs/nuscenes_dataset.yaml 은 (x: 오른쪽, y: 앞, z: 위) 기준으로 학습
- Waymo는 (x: 앞, y: 왼쪽, z: 위)
정확한 캘리 브레이션 정보없이 좌표계를 맞춰서 성능 저하가 발생한것 으로 추정
domain gap이 심함