12장 정리문제
1. 텐서란 무엇인가?
머신러닝에서 텐서(Tensor)는 데이터를 표현하는 핵심적인 자료구조이다. 숫자들의 배열을 일반화한 것으로 생각할 수 있다.
스칼라, 벡터, 행렬을 모두 포괄하는 개념이며, 더 높은 차원의 배열까지 다룰 수 있다.
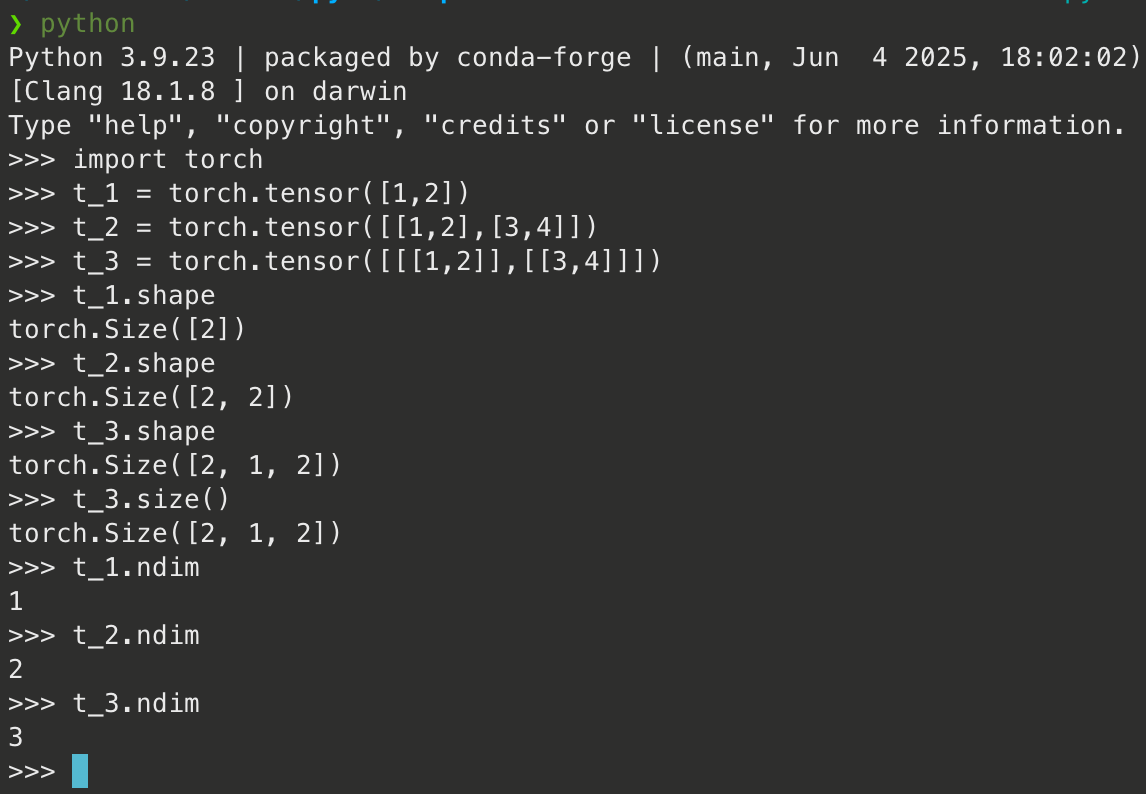
2. 텐서의 차원을 확인하는 방법은?
파이토치에서 텐서의 차원을 확인하려면 .shape, .ndim, .size() 를 사용할 수 있다.
3. torch.squeeze 함수의 기능은?
torch.squeeze() 함수는 파이토치에서 텐서의 차원을 줄이는 데 사용되는 함수로 크기가 1인 차원을 제거하여 텐서를 압축한다.
https://docs.pytorch.org/docs/stable/generated/torch.squeeze.html


4. torch.cat, torch.stack에서 매개변수 dim의 기능은?
torch.cat(), torch.stack()에서 매개변수 dim의 역할은 연산이 수행될 차원을 의미한다.
cat()에서는 텐서들이 이어붙을 차원을 나타내고, stack()에서는 새로운 차원이 생성될 위치를 나타낸다.


5. 파이토치에서 Dataset 클래스와 DataLoader 클래스의 기능을 설명하라. 실제로 Dataset, DataLoader객체안에 뭐가 저장되는지 자세히 설명하라.
파이토치의 Dataset과 DataLoader는 딥러닝 모델 학습을 위한 데이터 처리 파이프라인의 핵심 구성요소로 다음과 같은 역할을 한다.
Dataset은 샘플과 정답을 저장하고 데이터 샘플에 대한 인덱스 기반 접근을 가능하게 하며 데이터의 전처리나 변환 등을 한다.
DataLoader는 Dataset을 샘플에 쉽게 접근할 수 있도록 순회 가능한 객체(iterable)로 감싸며 데이터를 효율적으로 배치 단위로 불러오는 등의 기능을 한다.
- Dataset
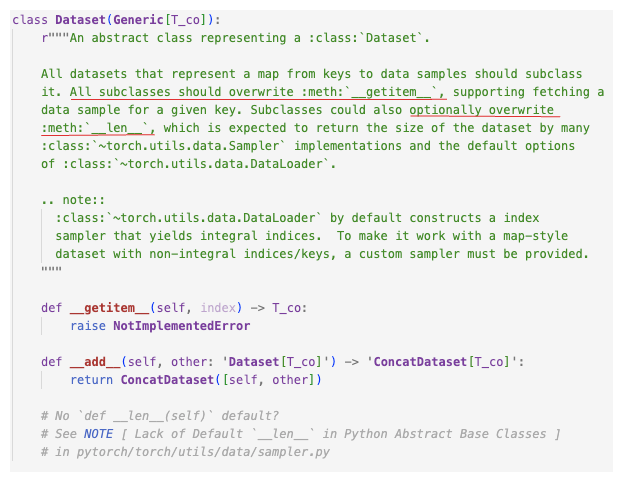
torch.utils.data.Dataset 클래스는 파이토치에서 데이터셋을 다루는 데 사용되는 핵심 추상 클래스이다.
이 클래스를 상속하여 사용자 정의 데이터셋을 만들 수 있으며, 이는 데이터 로딩 및 전처리 파이프라인의 기초가 된다.
인덱스에서 데이터 샘플로의 매핑을 나타내는 모든 데이터셋은 이 클래스를 상속해야하며 Dataset을 상속하는 모든 서브클래스는 __getitem__() 메서드를 오버라이드 해야 한다.
Dataset의 객체 안에는 데이터에 접근하기 위한 정보(인덱스-데이터 매핑 정보), 데이터 처리를 위한 정보, 데이터셋 크기(__len__) 등이 저장된다.
__getitem__ 은 필수, __len__ 은 선택적?
파이토치의 DataLoader는 데이터를 효율적으로 불러오기 위해 Sampler라는 객체를 사용한다.
Sampler를 특별히 지정하지 않으면, 즉 특정 커스텀 샘플러를 사용하지 않으면 기본 Sampler가 사용되고, 그러면 데이터셋의 전체 크기를 파악할 때 __len__ 메서드를 호출하게 된다. 따라서 기본 Sampler를 사용할 때 __len__ 을 구현하지 않으면 에러가 발생하게된다.
- DataLoader
torch.utils.data.DataLoader 클래스는 파이토치에서 딥러닝 모델을 학습시킬 때 데이터 로딩을 효율적으로 처리하기 위한 핵심 유틸리티 클래스이다.
DataLoader는 Dataset 클래스의 데이터에 쉽게 접근할 수 있게 해주는 반복자(iterable)이다.
• DataLoader는 크게 세 가지 중요한 기능을 한다.
1) 배치(Batch) 처리
데이터를 한 번에 하나씩 가져오는 것이 아니라, 여러 개의 데이터 샘플을 묶어 미니 배치 단위로 만들어 준다.
이는 GPU의 병렬 처리 능력을 최대한 활용하여 학습 속도를 크게 높여준다.
2) 데이터 셔플링
매 에포크마다 데이터 샘플의 순서를 무작위로 섞어준다. (전체 데이터셋을 학습할 때마다 순서를 바꾼다.)
이는 모델이 데이터의 순서에 편향되는 것을 방지하고, 일반화 성능을 높이는 데 도움을 준다.
3) 멀티 프로세싱
num_workers 매개변수를 통해 여러 개의 서브 프로세스를 사용하여 데이터를 병렬로 로드할 수 있다.
이는 데이터 로딩이 병목 현상이 될 수 있는 대규모 데이터셋 학습에서 중요하다.
• DataLoader를 생성할 때 주로 사용되는 핵심 매개변수는 다음과 같다.
- dataset (필수 매개변수)
DataLoader 객체 생성을 위한 필수 매개변수로 torch.utils.data.Dataset을 상속받은 객체이다.
DataLoader가 데이터를 가져올 소스를 지정한다.
- batch_size (선택 매개변수, 기본값 1)
한 번에 로드할 데이터 샘플의 개수를 지정한다.
- shuffle (선택 매개변수, 기본값 False)
True로 설정하면 각 에포크가 시작될 때마다 데이터셋의 순서를 무작위로 섞는다.
- num_workers (선택 매개변수, 기본값 0)
데이터를 로드하는 데 사용할 서브 프로세스의 개수이다. 0은 메인 프로세스에서 데이터를 로드함을 의미한다.
- drop_last (선택 매개변수, 기본값 False)
True로 설정하면, 데이터셋의 마지막 배치가 batch_size보다 작을 경우 이 마지막 배치를 버린다.
이는 모든 배치의 크기를 동일하게 유지하여 모델 학습을 안정적으로 만든다.
6. Dataset 클래스에서 __getitem__ 멤버함수의 기능은?
Dataset 클래스의 __getitem__() 함수는 데이터셋의 데이터를 인덱스를 통해 접근할 수 있게 해주는 메서드이다.
__getitem__(self, index) 와 같은 형식으로 작성하며 매개변수 index에 해당하는 샘플과 레이블을 반환해주는 기능을 한다.
예를 들어, 사용자 정의 데이터셋인 my_dataset에 대하여 my_dataset[5]는 인덱스 5에 해당하는 샘플과 레이블을 반환한다.
7. 훈련데이터가 100개이고 배치사이즈가 20개일때 1에퍽동안 가중치는 몇번 업데이트 되는가?
1에퍽이란 전체 데이터셋을 한 번 반복하는 것을 의미하고, 배치 사이즈가 정해졌을 때는 배치 크기만큼의 학습이 끝날 때마다 가중치가 업데이트되므로 훈련데이터가 100개일 때 1에퍽 동안 배치 사이즈 20인 경우 가중치 업데이트가 5번 일어난다.
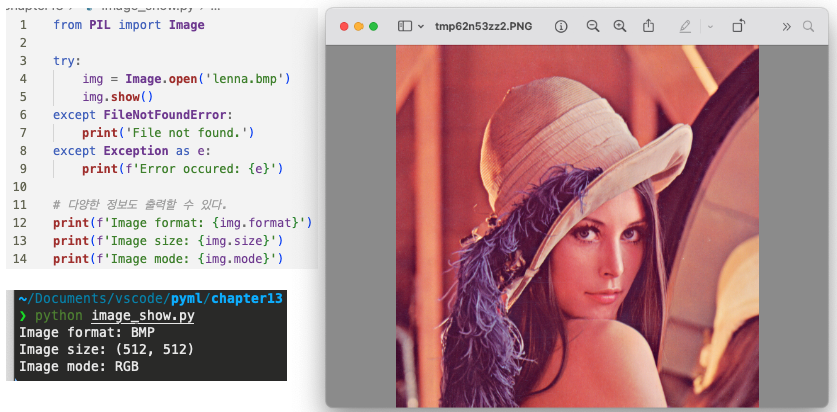
8. PIL, matplotlib 패키지를 이용하여 영상파일을 읽어서 화면에 출력하는 방법
- PIL
PIL이란 Python Image Library의 약자로 파이썬에서 이미지를 다루는 데 사용되는 라이브러리이다.
2009년 이후로 개발이 중단되었지만 이후에 Pillow가 이를 계승하여 개발되었고, PIL은 Pillow를 지칭하게 되었다.
• PIL을 이용해 이미지를 출력하는 방법
1) Pillow 라이브러리 설치
pip install pillow
2) show() 메서드를 사용해 이미지 출력
show() 메서드는 운영체제에 설정된 기본 이미지 뷰어를 통해 이미지를 보여준다.
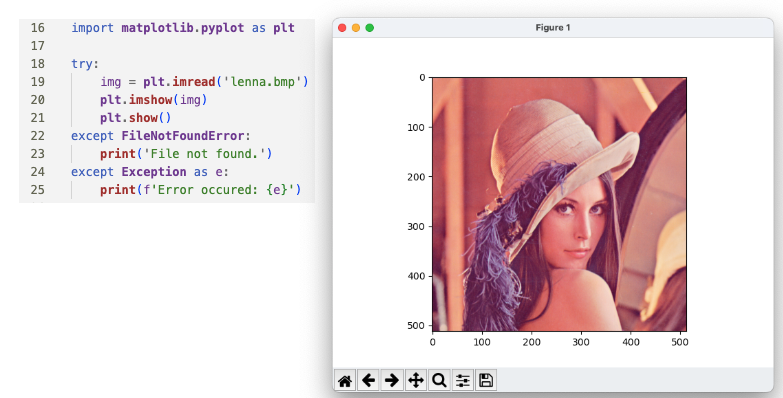
- matplotlib
• matplotlib 을 이용해 이미지를 출력하는 방법
pyplot 모듈의 imread()와 imshow() 메서드를 이용해 넘파이 배열 형태의 이미지 데이터를 출력할 수 있다.
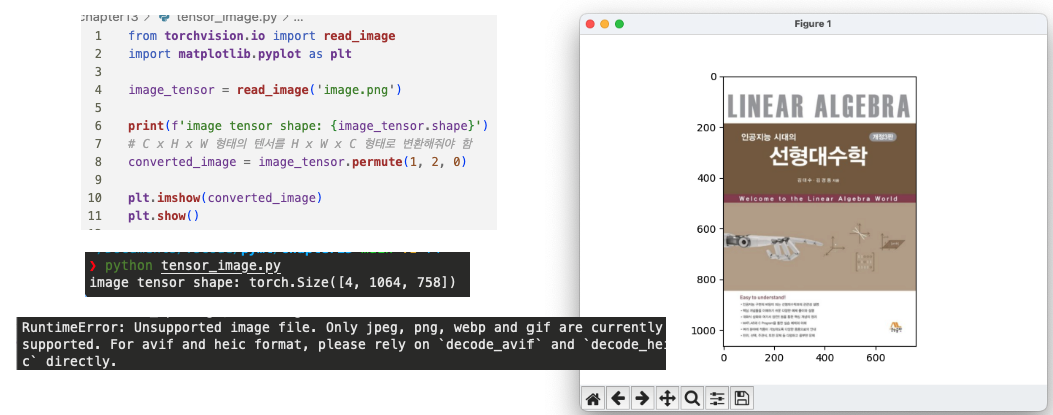
9. 영상 파일을 읽어서 텐서 형태로 변환하여 출력하기
torchvision 라이브러리의 io.read_image 메서드를 이용해 영상을 읽어 텐서로 변환할 수 있다. (jpeg, png, webp, gif 유형의 파일만 가능)
10. Dataset 클래스에서 데이터 증식을 위한 영상 변환(transforms)을 추가하는 방법
Dataset 클래스에서 데이터 증식을 하는 방법은 다음과 같다.
1) torchvision.transforms를 사용해서 학습 데이터에 적용할 변환을 정의한다.
2) Dataset 클래스의 __init__ 메서드에 transform 인자를 추가한다.
3) Dataset 클래스의 __getitem__ 메서드에서 이미지를 로드한 후 정의된 변환을 적용한다.
11. Dataset, DataLoader 객체안에 저장된 영상을 로드할때 영상변환이 적용되는 원리
- Dataset 객체의 역할
Dataset의 __init__에 정의된 변환을 저장하고, 필수 메서드 __getitem__에서 변환이 적용된다.

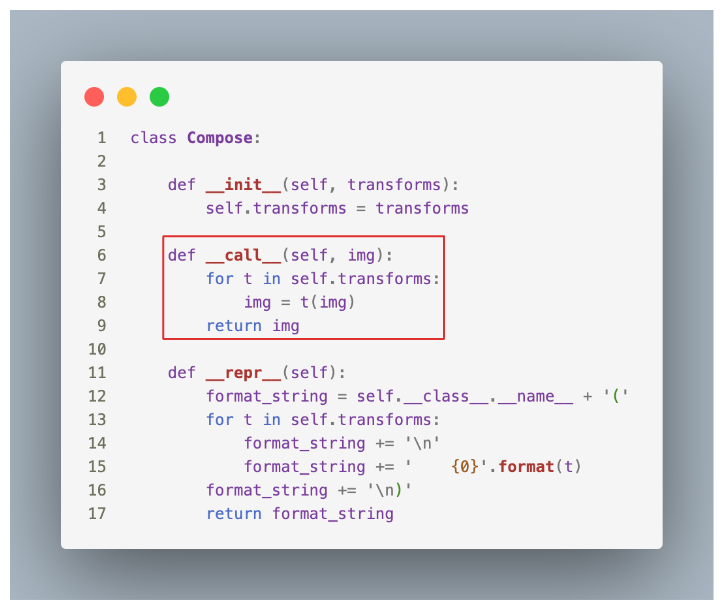
1) torchvision.transforms의 Compose 클래스를 통해 객체를 만들어 어떤 변환을 적용할 지를 정의한다.
2) Dataset 클래스의 __init__ 메서드에 transform 인자를 추가한다.
3) Dataset 클래스의 __getitem__ 메서드에서 이미지를 로드한 후 정의된 변환 적용한다.
Compose 클래스 내부의 __call__ 메소드 때문에 객체를 함수처럼 호출할 수 있다.
__call__ 함수를 실행하면 transforms 안의 변환을 img에 적용하여 img를 return한다.
- DataLoader 객체의 역할
DataLoader 객체는 Dataset 객체로부터 데이터를 가져와 배치 단위로 묶어주는 역할을 하는데, 여기서 Dataset의 __getitem__ 메서드를 통해 데이터를 로드한다. __getitem__ 메서드 내부에서 transform이 호출되어 데이터에 변환이 적용된다.
12. iter, next, enumerate 함수의 기능
- iter() 함수
iter() 함수는 반복 가능한(iterable) 객체를 반복자(iterator) 객체로 만들어 반환한다.
- next() 함수
next() 함수는 반복자 객체를 받아 다음 요소를 반환한다. 더 이상 반환할 요소가 없을 경우 StopIteration 예외를 발생시킨다.
- enumerate() 함수
enumerate() 함수는 반복 가능한 객체를 받아 인덱스와 값을 묶어서 반환하는 반복자를 생성한다. (인덱스, 값) 튜플 형식
인덱스와 값을 모두 사용해야 하는 상황에서 유용하다.
13. 손실함수를 최적화한다는 것의 의미
손실함수를 최적화한다는 것은 모델의 예측값과 실제값 사이의 오차를 최소화하는 과정을 의미한다.
최적화 = 손실함수 값이 가장 낮아지는 가중치와 편향을 찾는 것
14. 손실함수의 종류
손실함수의 종류로는 다음과 같은 함수들이 있다.
- MSE(Mean Squared Error) 평균제곱오차
예측값과 실제값의 차이를 제곱하여 평균을 낸 값
- Cross-Entropy 교차 엔트로피
이진 분류 → 이진 교차 엔트로피(BCE)
다중 분류 → 범주형 교차 엔트로피
15. 최적화 방법의 종류
손실함수를 최적화하는 방법에는 다음과 같은 방법들이 있다.
- 경사 하강법 → 손실함수의 기울기를 이용하여 최소값을 찾아가는 방식
• 배치 경사 하강법: 전체 학습 데이터를 사용하여 손실함수의 기울기를 계산하고 한 번의 업데이트를 수행
• 확률적 경사 하강법: 무작위로 선택한 하나의 데이터 샘플을 사용하여 손실함수의 기울기를 계산하고 파라미터를 업데이트
• 미니 배치 경사 하강법: 전체 데이터를 일정 크기의 미니 배치로 나누어, 각 미니 배치에 대해 기울기를 계산하고 업데이트를 수행
- 경사 하강법의 개선
• 모멘텀: 관성의 개념을 도입한 방법으로, 이전 단계의 이동 방향을 일정 비율로 반영하여 업데이트를 수행
• AdaGrad: 각 파라미터마다 다른 학습률을 적용하는 방법
• RMSProp: AdaGrad의 문제점을 개선한 방법. 최근 기울기 기반으로 학습률을 조정
• Adam: 모멘텀과 RMSProp의 장점을 결합한 방법
16. 소프트맥스 활성화 함수의 기능
소프트맥스 활성화 함수는 다중 클래스 분류에서 사용되는 함수로 신경망의 출력값을 확률 분포로 변환하여 해석하기 쉽게 만든다.
이 함수는 입력 값을 받아 각 요소를 0과 1 사이의 값으로 변환하며, 이 출력값의 총합은 항상 1이 된다.
17. torch.argmax함수를 설명하라.
torch.argmax 함수는 매개변수로 입력 받은 텐서의 최대값에 해당하는 인덱스를 반환하는 함수이다. 모델의 예측 결과를 해석할 때 유용하게 사용된다.