Dataset
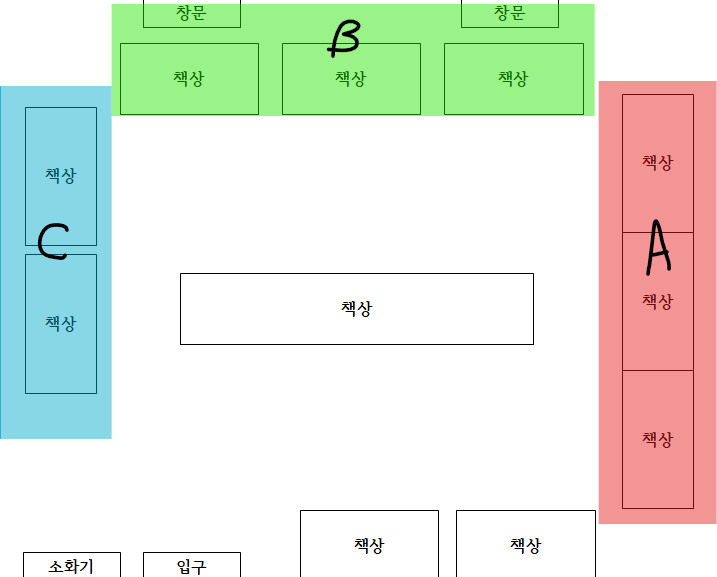
현재 연구실 구역을 A, B, C 구역으로 나누고 이를 다양한 각도와 조명으로 각각 20장씩 찍어서 FineTuning 진행함

FineTuning은 이전과 마찬가지로 LoRA를 사용했으며
질문과 답변은 아래와 같이 설정했음

학습 시간은 약 15분 걸렸음
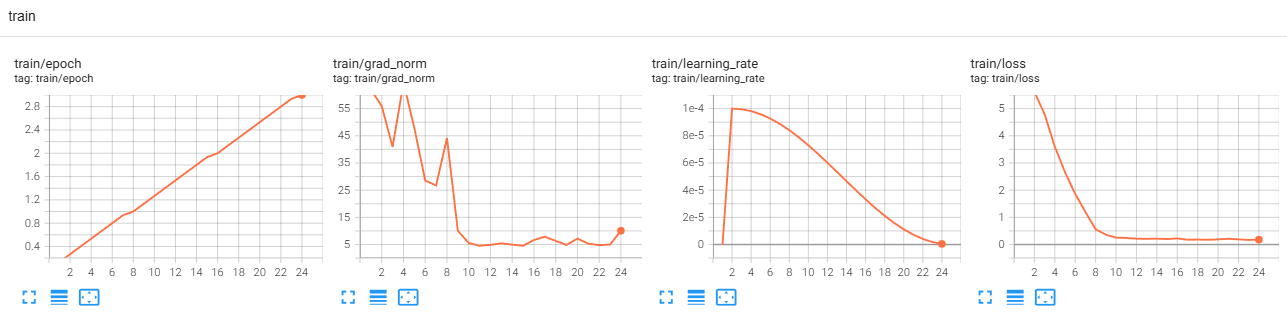
+ grad_norm : 학습 중 모델 파라미터를 얼마나 크게 업데이트하려는지를 나타내는 지표
grad_norm 갑자기 상승 + loss도 같이 튀었다: 학습이 불안정했다는 신호
grad_norm 상승했는데 loss는 계속 떨어졌다: 큰 업데이트가 오히려 효과적이었다는 뜻
Inference (1)
A(20) + B(20) + C(20) = 60
 |  |  |
위의 3가지의 이미지로 추론을 돌렸고 결과적으로 모두 B구역이라 답하거나,
정확도가 떨어지는 결과를 냄...
따라서 이번에도 세세한 특징을 구분하려면 데이터셋이 더 있어야 할 거 같다고 판단함
증강을 사용해서 원본을 크게 건드리지 않는 선에서 100장까지 늘리기로 결정하고 진행함
Data Augmentation


이를 가지고 Train Arguments는 그대로 유지하고 다시 학습 시작
Inference (2)
A(100) + B(100) + C(100) = 300
여전히 B구역이라고만 인지함
문제점인게 학습 데이터로 이용했던 사진을 추론에 사용해도 B구역이라는 똑같은 답변만 나옴
Inference(3)
lora_rank를 더 키우는 방향으로 다시 학습 (32 -> 64)
이번에는 사진에 대해 A, B, C 구역을 인지하기 시작함
근데 문제점은 데이터셋이 적어서
특징적인 (예를 들면 C구역의 칠판, 냉장고, 시계) 요소들이 한 번에 안 들어오면 정확도가 많이 낮음
데이터셋을 더 많이 수집해서 약 150장 정도로 맞춰놓고 학습해야 할 것 같음
 |  |
모델 전체구조 파악 & 파인튜닝 시 어떤 부분을 튜닝하는지?
1. 모델 구조 파악
① Vision Encoder (비전 인코더) — 이미지를 받아서 작은 패치들로 쪼개고, 각 패치를 벡터(임베딩)로 바꿔주는 부분
Qwen2.5-VL은 ViT 기반에 2D-RoPE까지 적용된 구조라 패치의 공간적 위치 정보까지 담음.
+ Window 기법
https://beausty23.tistory.com/285
② Merger(Projector) — Vision Encoder가 뱉은 벡터의 차원이랑 LLM이 받아들이는 차원이 서로 안 맞아서, 이 둘을 연결해주는 작은 변환 모듈임. 보통 MLP 한두 층 정도로 단순하게 구성됨. 비전 쪽이랑 언어 쪽을 합쳐주는(merge) 역할임.
③ LLM (언어모델 본체) — Qwen2.5-VL == Qwen2.5 LLM이 백본임. 생각하고 답을 생성하는 부분임.
2. 파인튜닝 시 정확히 어디가 튜닝되는지
세 모듈을 각각 따로 컨트롤하는 옵션이 있음.
freeze_vision_tower, freeze_llm, freeze_merger

freeze_llm=True + lora_enable=True
처음엔 직관적으로 freeze_llm=True면 LLM이 학습 안 되는 거 아닌가? 라고 생각했었는데
그게 아니라 lora_enable도 True라고 줬었기 때문에 옆에 작은 LoRA 행렬만 새로 학습하는 형태
== LLM 내부 특정 Linear layer마다 LoRA라는 작은 보조 행렬을 병렬로 붙여서 그 보조 행렬만 학습시키는 거임.
수식으로 보면
출력 = W·x (동결) + B·(A·x) (학습됨)
lora_rank가 A,B 행렬의 크기(r)를 결정하고, 실제 적용 비율은 alpha/r로 스케일됨.
(x = input)
추론할 때는 원본 가중치 + LoRA 보조 행렬을 같이 써서 결과를 냄
따라서 모델 출력은 LoRA를 통해 학습됨.
Vision
freeze_vision_tower=False로 두면 Vision Encoder를 통째로 풀파인튜닝하는 거고,
대신 vision_lora=True로 켜면 Vision Encoder 내부 Linear layer에도 LLM이랑 똑같은 방식으로
LoRA만 살짝 붙여서 가볍게 적응시키는 선택지도 있음. 풀파인튜닝보다 가볍고 빠름.
Merger
Merger는 원래 작은 모듈(MLP 한두 층)이라 LoRA 쪼개서 학습할 필요가 별로 없음.
그래서 freeze_merger=False로 두고 그냥 전체를 다 학습시키는 경우가 많음.
STT / Omni 비교
https://kind-slip-86b.notion.site/Jetson-AGX-Orin-37d8a2c2bfdb80ada442cae959ecd565?source=copy_link