1단계 - 데이터셋 폴더 구조 생성
작업 폴더(D:\Users\tjdwls\pytorch\dataset2) 아래에 다음 두 폴더를 생성한다.
2단계 - 이미지 촬영 및 배분
검출 대상 객체(big robot, small robot)를 포함한 사진을 스마트폰으로 직접 촬영한 영상을 사용했다.
촬영 시 촬영 각도, 거리, 영상 내 객체 수를 다양하게 변경하여 유사한 영상이 반복되지 않도록 한다.
- 촬영된 이미지를 8:2 비율로 분할
- trainimg/ : 160장 (IMG_7598.JPG ~ 등, 스마트폰 촬영 + 카카오톡 전송 이미지)
- valimg/ : 40장
- 총 200장 사용
3단계 - labelme 설치 및 실행
Anaconda Powershell Prompt를 열고 labelme 전용 가상환경을 활성화한 뒤 실행한다.
4단계 - trainimg, valimg 레이블링
1. labelme 상단 메뉴 → File → Open Dir → dataset2\trainimg 폴더 선택
2. 첫 번째 이미지가 열리면 상단 메뉴 → File → Save with Image Data 앞의 체크 해제
(체크하면 이미지 데이터가 json에 포함되어 파일 크기가 커짐)
3. 상단 메뉴 → Edit → Create Rectangle 선택
4. 객체를 감싸는 바운딩박스의 좌측 상단 클릭 → 우측 하단 클릭
5. 클래스 레이블 입력창에 레이블 입력 후 OK
- 큰 로봇 → big robot
- 작은 로봇 → small robot
6. 영상에 존재하는 모든 객체에 대해 위 과정 반복
7. File → Save로 저장 → 이미지와 동일한 이름의 .json 파일 생성됨
(예: IMG_7598.JPG → IMG_7598.json)
8. 툴바의 Next Image를 클릭하여 다음 이미지로 이동, 160장 전체 반복
결과적으로 trainimg 폴더에 아래와 같이 쌍으로 파일이 생성됨:
IMG_7598.JPG / IMG_7598.json
IMG_7599.JPG / IMG_7599.json
... (160쌍)
각 json에는 바운딩박스 좌표(좌상단/우하단)와 클래스 레이블이 저장됨
마지막으로 File → Open Dir → dataset2\valimg 선택 후 동일한 방법으로 40장 전체 레이블링.
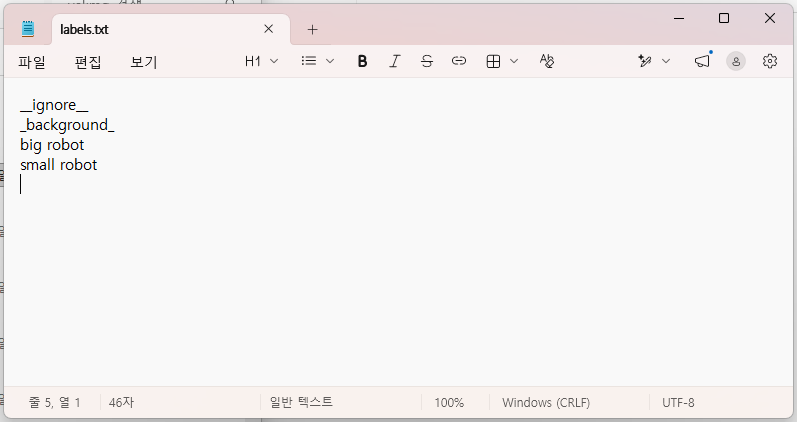
5단계 - labels.txt 작성
아래 내용으로 labels.txt 파일을 작성하고, trainimg와 valimg 폴더 각각에 저장한다.
(처음 두 항목은 labelme2coco 변환 시 반드시 필요한 고정값)
6단계 - COCO 형식으로 변환
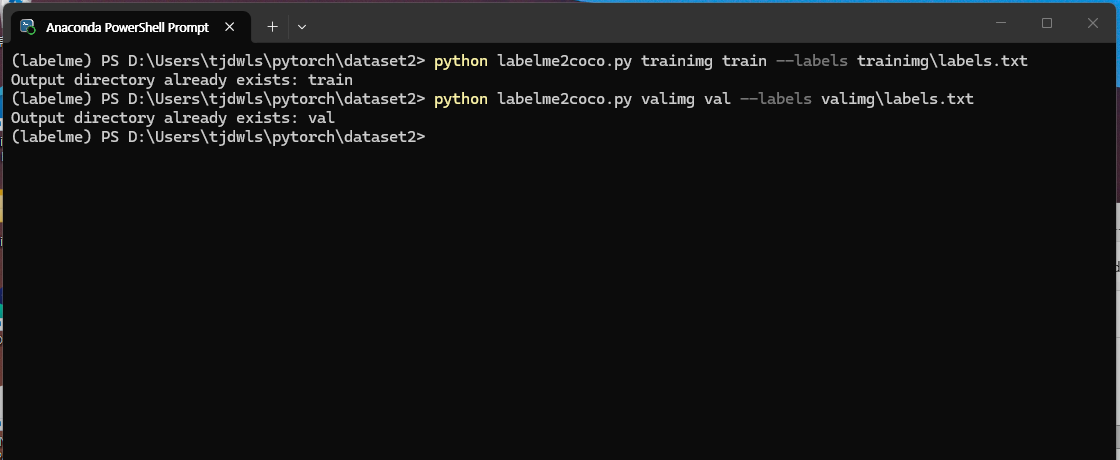
160개/40개의 개별 json 파일을 COCO 형식의 통합 json 1개로 변환하기 위해 labelme2coco.py를 사용했다.
Anaconda Powershell에서 dataset2 폴더로 이동 후 실행
# 훈련용 변환
python labelme2coco.py trainimg train --labels trainimg\labels.txt
# 검증용 변환
python labelme2coco.py valimg val --labels valimg\labels.txt
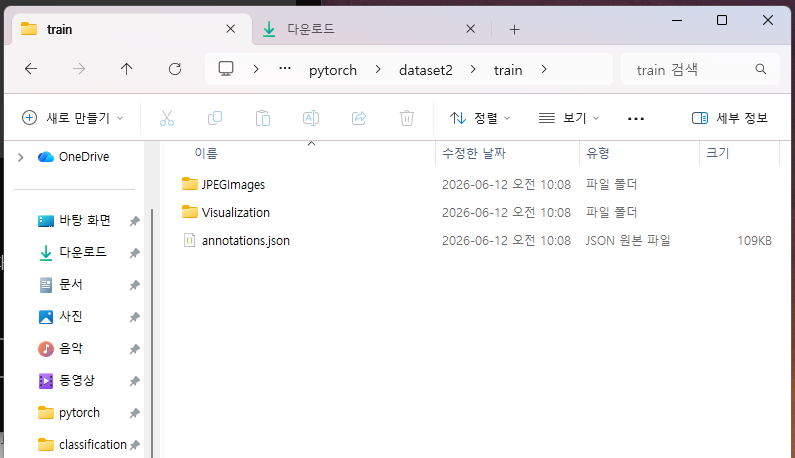
변환 결과로 train/, val/ 폴더가 생성되고 각각 아래 구조로 만들어진다.
train\
JPEGImages\ ← trainimg의 이미지 160장 복사
Visualization\ ← 레이블링 결과 확인용 이미지 (바운딩박스 시각화)
annotations.json ← 160개 json을 하나로 통합한 COCO 형식 파일
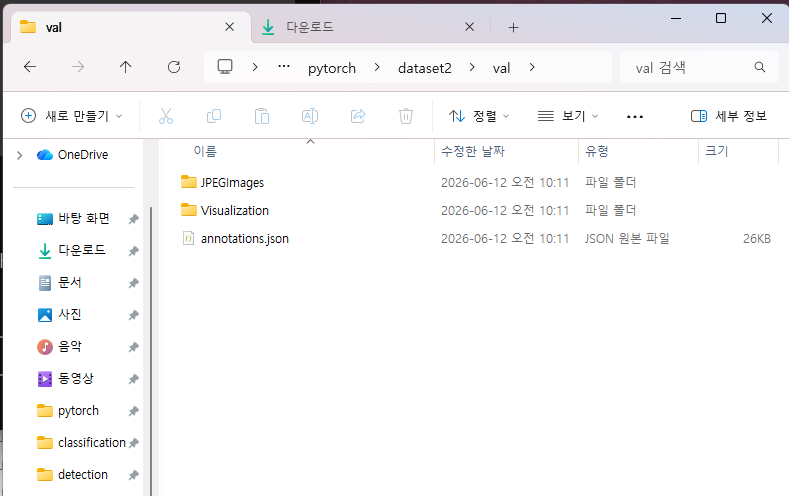
val\
JPEGImages\
Visualization\
annotations.json
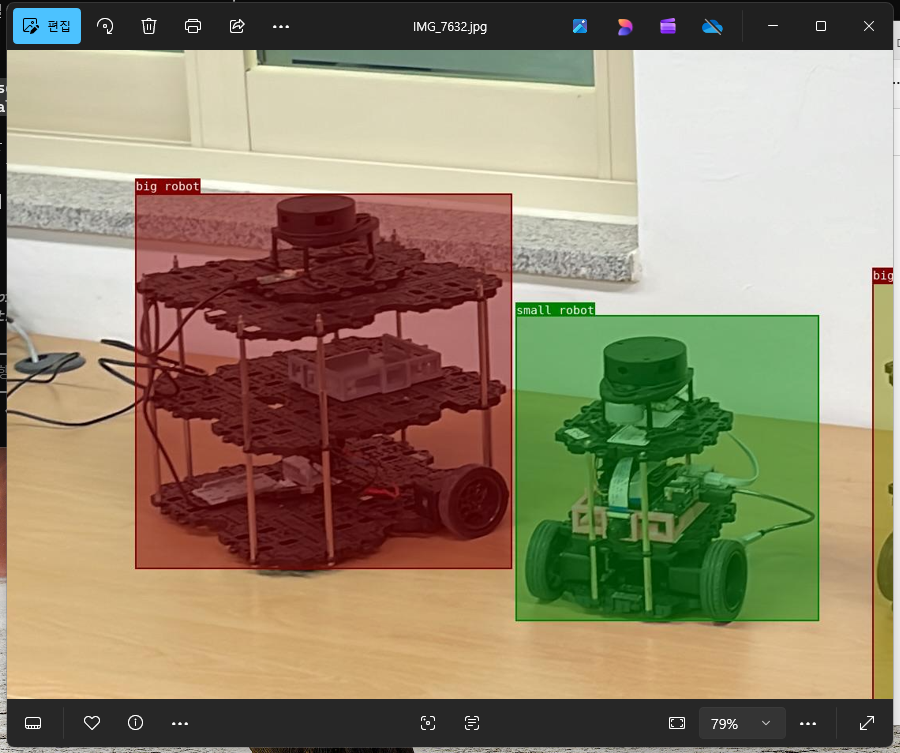
7단계 - 레이블링 결과 확인
train\Visualization\ 폴더의 이미지를 열어 바운딩박스 위치와 클래스 레이블이 올바르게 표시되는지 육안으로 확인한다.