1. 심층신경망(DNN, Deep neutral network)
은닉층을 여러개인 신경망, 일반적으로 수십개~수백개 이상
종류
1) CNN : 비전분야(영상분류, 객체검출, 영상분할)에 사용,
컨벌루션 레이어(convolution layer) + 완전연결 레이어(fully connected layer)
컨벌루션 레이어 : 특징 추출, 풀링, 완전연결 레이어 : 특징 분류
2) RNN : 시계열데이터 or 순차데이터를 다룰때 사용, 자연어처리, 오디오데이터 처리
3) GAN : 생성형 모델, 그림그리기, 소설작성, 음악작곡
4) Transformer, LLM : GPT에 사용, 자연어처리, 컴퓨터비전
모델의 기본 구성요소 -> 신체의 구조를 본떠서 이름을 붙임
신호의 흐름은 입력->백본->넥->헤드->출력으로 계산됨
(1) 백본(backbone) : 데이터의 특징을 추출하는 핵심부분
(2) 넥(neck) : 백본에서 추출한 특징을 목적에 맞게 변형 또는 가공하는 부분
(3) 헤드(head) : 최종 예측을 수행하는 부분(분류,검출,분할,생성 등)
2. 심층학습(Deep learning)
심층신경망을 훈련시키는 알고리즘
심층신경망은 기존의 역전파알고리즘만으로는 훈련이 잘 안됨
역전파알고리즘이 수렴할수 있도록 다양한 훈련기법이 추가됨
ReLU(렐루)활성화함수, 드랍아웃기법, 규제, 등
3. 영상분류(image classification)용 심층신경망
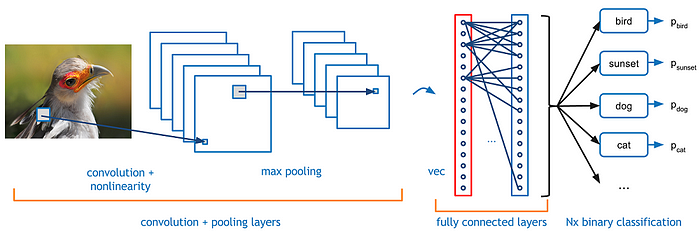
기본구조는 CNN과 같음
분류를 위한 특징을 추출하는 컨벌루션 레이어, 특징정보를 압축하는 풀링레이어, 추출된 특징을 이용하여 분류를 수행하는 완전연결레이어(fully connected layer, FC)
컨벌루션 레이어는 영상처리의 컨벌루션(필터링)연산을 신경망으로 구현한것
완전연결레이어는 일반적인 분류를 위한 다층퍼셉트론과 같음
CNN의 입력은 영상인데 영상은 2차원정보임, 기존의 다층퍼셉트론은 입력이 1차원벡터임, 따라서 CNN에서는 영상에 존재하는 이웃픽셀과 관련된 기하학적인 특징정보(에지, 외곽선, 등)를 그대로 훈련가능
영상분류를 위해 다층퍼셉트론은 이용한다면 2차원을 1차원으로 변환후에 모델에 입력해야하므로 2차원적인 특징이 사라짐, 따라서 기존의 다층퍼셉트론만으론 영상분류가 힘듦
Alexnet -> 영상분류에 최초로 딥러닝기법사용한 모델
Googlenet
VGG
Resnet
Mobilenet
4. 객체검출(object detection)용 심층신경망
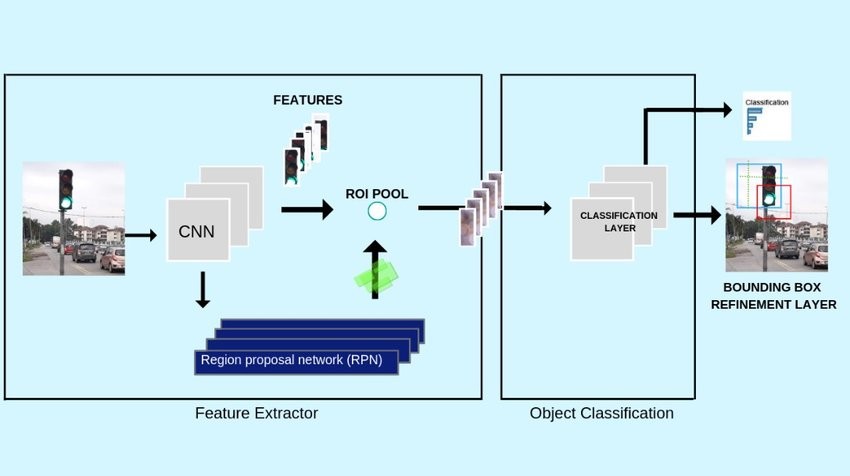
Backbone 모델(CNN) + 검출용 헤드 추가기능
Backbone : 머신 러닝 및 컴퓨터 비전 분야에서 주로 사용되는 용어로, 신경망의 핵심 구조를 의미한다. 보통 심층신경망 모델, 특히 컨볼루션 신경망(CNN)에서 이미지의 특징을 추출하기 위해 사용되는 기본 네트워크를 가리킨다. Backbone은 이미지에서 높은 수준의 추상화를 추출하여 더 복잡한 작업(예: 객체검출, 분할 등)을 수행하는 다른 네트워크 컴포넌트에 정보를 제공한다.
객체검출은 기본적으로 CNN을 이용하여 2번의 영상분류를 수행함
첫번째 분류기는 객체가 존재할 가능성이 큰 영역(region proposal)과 배경영역(background)을 분류한다. 2개 클래스로 분류하는 이진 분류문제와 같음 -> 객체검출용 레이블링에서 배경도 하나의 클래스로 정의해야하는 이유임
따라서, 객체검출시는 배경도 하나의 클래스로 취급해야함을 주의해야한다.
두번째 분류기는 region proposal(객체가 존재하는 사각형영역)을 찾으면 그 영역안에서 어떤 객체가 존재하는지 다시 CNN을 이용하여 영상분류를 수행한다.
결과적으로 객체의 종류와 함께 객체의 위치(객체를 포함하는 바운딩박스정보)도 구해주는 모델임
Faster RCNN -> 객체가 존재할 가능성이 높은 영역(region proposal)을 먼저 찾고 그 영역에 대하여 영상분류를 수행(2 step 방식) , 속도는 느리나 정확도 높음
Yolo -> 객체가 존재할 가능성이 높은 영역과 영상분류를 동시에 수행(1 step 방식), 속도는 빠르지만 정확도 낮음
5. 영상분할(image segmentation)용 심층신경망
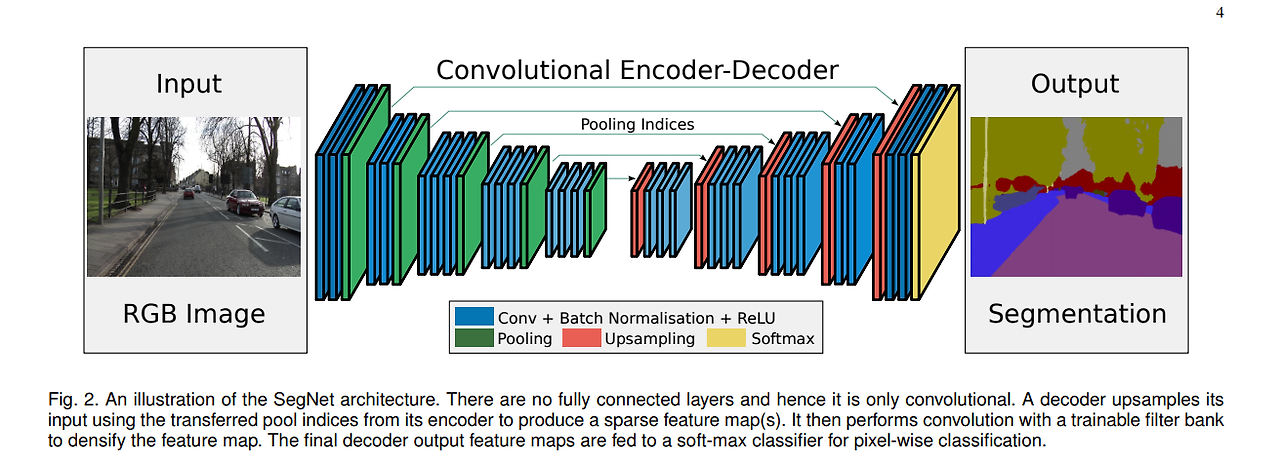
Backbone 모델(CNN) + 분할용 추가기능 -> 기본구조는 인코더+디코더 구조임 인코더에서 영상으로부터 추상화된 정보를 추출하고 디코더에서 객체영역이 픽셀단위로 분류된 영상을 생성함, 처리과정이 입력영상을 특징정보로 암호화(압축)시키고 다시 반대로 암호를 해석하여 원래 입력신호를 복원하는 과정(디코더)을 거침
영상분할도 기본적으로는 영상분류의 원리와 같다.
단지 영상분할은 픽셀단위로(각각의 픽셀별로) 어느 클래스에 속하는지 분류를 해준다. 따라서 객체의 영역을 픽셀단위로 정확하게 알수 있다. 따라서 모델의 출력도 입력과 같은 크기를 갖는 영상이고 객체영역별로 같은 픽셀값을 가지는 마스크영상임
마스크영상 : 객체의 영역을 하나의 색상으로 표시하여 픽셀단위로 객체의 영역을 서로 다른 색상으로 분류해놓은 영상을 말함
영상분류가 전체영상을 하나의 클래스로 분류하고 객체검출은 객체를 포함하는 바운딩박스를 구하고 그안에 뭐가 있는지까지 분류해주는 기술이고 영상분할은 픽셀별로 어느 클래스에 속하는지 알려주는 기술임 -> 점점 더 정밀한 정보를 알려주는 기술로 발전했음

FCN
Mask RCNN
Unet
Deeplab v3+
6. 실습과제
1) 퍼셉트론, 다층퍼셉트론(MLP), 심층신경망(DNN)의 차이점을 설명하라.
2) 기존의 역전파알고리즘의 문제점이 무엇인지 조사하고 심층학습에서는 이를 어떻게 해결하였는지 조사해보라
3) 영상분류, 객체검출, 영상분할 기술의 차이를 설명하라.
4) 영상분류 모델의 입력과 출력신호가 무엇인지 설명하라.
5) 객체검출 모델의 입력과 출력신호가 무엇인지 설명하라.
6) 영상분할 모델의 입력과 출력신호가 무엇인지 설명하라.
7) 영상분류모델 중에 Resnet의 기본구조, 종류, 기능을 설명하라
8) 객체검출 모델중에 Faster RCNN의 기본구조와 기능을 설명하라
9) 영상분할 모델중에 Deeplab v3+의 기본구조와 기능을 설명하라