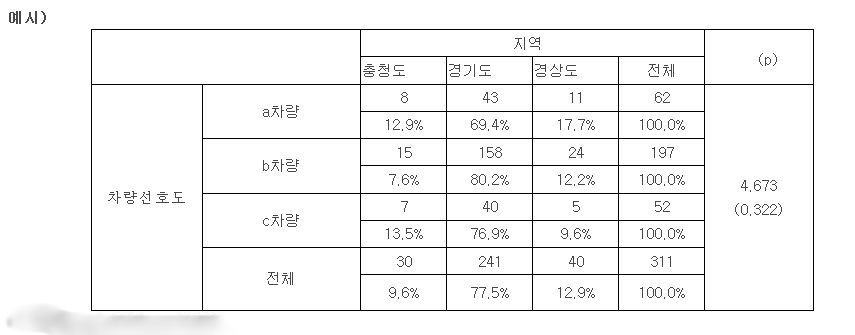
위와 같이 3개의 지역별로 선호하는 차량을 조사하여, 3X3의 교차표를 얻고 이에 따른 카이제곱통계량과 유의확률값을 구했습니다. 이때, 카이제곱값을 구하는 방법에 대하여 아래와 같이 설명하겠습니다.
===========================================================================================================
우선 카이제곱검정은 점수화데이터가 아닌, 명목형데이터로써 연구자의 문항에 응답한 관찰빈도와 기대빈도를 계산함으로써 서로가 독립이다 아니라를 판단하는 것입니다.
관찰빈도는 위 표가 관찰빈도입니다. 말그대로 자료입력한 데이터를 근거로 실질적인 빈도가 됩니다. 이를 통해 기대빈도를 산출해야합니다.
관찰빈도표를 아래와 같이 다시 그려보면,
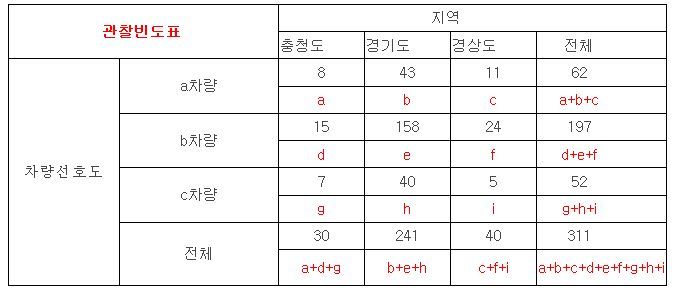
위 표처럼 각 셀을 알파벳으로 정의하겠습니다.
이를 통해 기대빈도를 산출하면 아래와 같습니다.
a=(a+b+c+d+e+f+g+h+i) X (a+b+c / a+b+c+d+e+f+g+h+i) X (a+d+g /a+b+c+d+e+f+g+h+i)
=311 X (62/311) X (30 / 311)
=5.980707
b=(a+b+c+d+e+f+g+h+i) X (a+b+c / a+b+c+d+e+f+g+h+i) X (b+e+h /a+b+c+d+e+f+g+h+i)
c=(a+b+c+d+e+f+g+h+i) X (a+b+c / a+b+c+d+e+f+g+h+i) X (c+f+i /a+b+c+d+e+f+g+h+i)
d=(a+b+c+d+e+f+g+h+i) X (d+e+f / a+b+c+d+e+f+g+h+i) X (a+d+g /a+b+c+d+e+f+g+h+i)
e=(a+b+c+d+e+f+g+h+i) X (d+e+f / a+b+c+d+e+f+g+h+i) X (b+e+h /a+b+c+d+e+f+g+h+i)
f=(a+b+c+d+e+f+g+h+i) X (d+e+f / a+b+c+d+e+f+g+h+i) X (c+f+i /a+b+c+d+e+f+g+h+i)
g=(a+b+c+d+e+f+g+h+i) X (g+h+i / a+b+c+d+e+f+g+h+i) X (a+d+g /a+b+c+d+e+f+g+h+i)
h=(a+b+c+d+e+f+g+h+i) X (g+h+i / a+b+c+d+e+f+g+h+i) X (b+e+h /a+b+c+d+e+f+g+h+i)
i=(a+b+c+d+e+f+g+h+i) X (g+h+i / a+b+c+d+e+f+g+h+i) X (c+f+i /a+b+c+d+e+f+g+h+i)
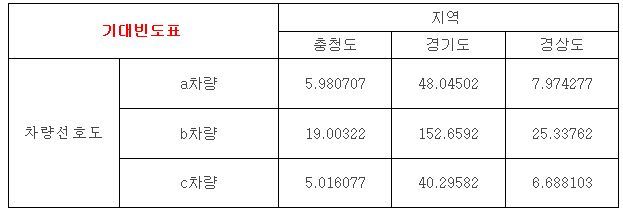
이와 같이 각각 셀의 기대빈도를 구합니다.
구한 기대빈도의 표는 아래와 같습니다.
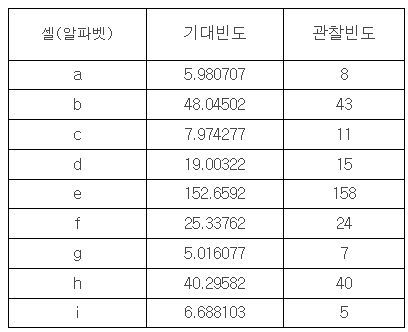
즉, 관찰빈도와 기대빈도를 위에서 설명한 알파벳 순서로의 셀로 정의하면 아래와 같습니다.
이제 기대빈도를 구했으면 카이제곱 통계량을 산출합니다.
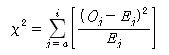
= [(8-5.980707)^2 / 5.980707] + [(43-48.04502)^2 / 48.04502] + .... +[(5-6.688103)^2 / 6.688103]
= 0.681783+0.529757+1.148067+0.843317+0.186851+0.070616+0.784667+0.002172+0.426084
= 4.673312 , where, O : 관찰빈도(Observed Count), E : 기대빈도(Expected Count), ^2 : 제곱
즉, 카이제곱 통계량은 4.673(4.673312)이 됩니다.
통계량값을 구했으면 이젠 자유도를 구해야 하는데, 이는
자유도=(행범주의수-1)*(열범수의수-1)=2*2=4
가 됩니다.
이제 95%신뢰구간에 들어가는지를 보아야 하는데, 이에 대하여 계산을 다 해놓은 표가 인터넷이나 통계관련서적의 부록에 모두 실려 있습니다. 인터넷검색을 원하고자 하시면 카이제곱분포표라고 검색해보시면 됩니다.
아래 표는 카이제곱분포표로써 카이제곱통계량이 4.673312 이면서 자유도가 4일때 검증하고자 하는 가설에 대하여 차이가 있는지 없는지를 판단해 보겠습니다.
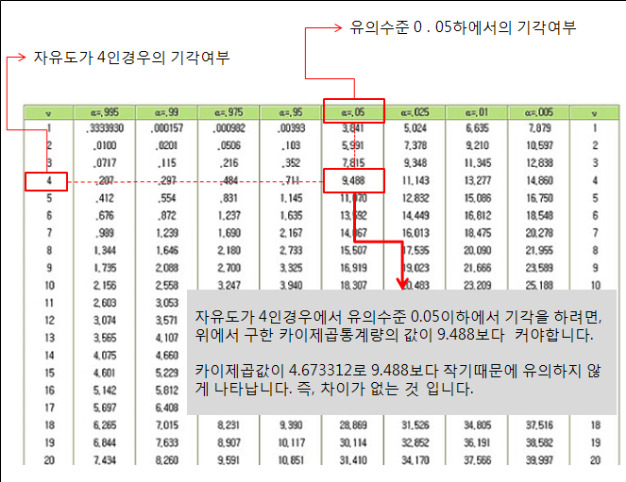
이처럼 각 셀에서 차지하는 관찰빈도와 기대빈도에 의하여, 상호간에 차이가 있는지 없는지를 보는 분석법이 카이제곱분석입니다.
위 자료에 대한 무단 도용은 삼가해주시기 바랍니다.

댓글
댓글 리스트-
작성자어레이 작성시간 11.06.13 관찰빈도셀을 이용하여 예상되는 기대빈도를 구하고 이들에 대한 통계량으로 비교집단들이 독립인지 아닌지를 본다는 거군요. spss로 형식적으로 돌리는 방법은 알지만 개념을 몰라서 실무적용이 안되고 있었는데 유용한 자료네요.
-
작성자윌링니스 작성시간 11.06.21 유용한 자료네요~ 감사합니다 :)
-
작성자명랑소녀 작성시간 14.05.20 정말 유용한 자료네요^^ 기본 개념을 이해하는데 도움이 됩니다.^^ 감사합니다.~~
-
작성자바다사랑 작성시간 15.06.12 좋은 정보 감사합니다.