안녕하세요. 흥미로운 연구를 진행 중이시군요.
질문마다 답변 달았습니다.
1. 단순히 특정 단어의 hit 수 뿐만 아니라 각 자료 간의 활용 빈도를 분석하기 위해 객관적 비교 수치가 필요합니다.
그래서 tokens per 1,000 words의 수치를 알고 싶은데 어떻게 하면 될지요?
-> 여러 파일에서 등장하는 단어 수를 표준화한 수치로 비교하시려는군요. 코퍼스 툴 게시판 중 Antwordprofiler 사용법을 살펴보시면 도움이 될 것 같습니다.
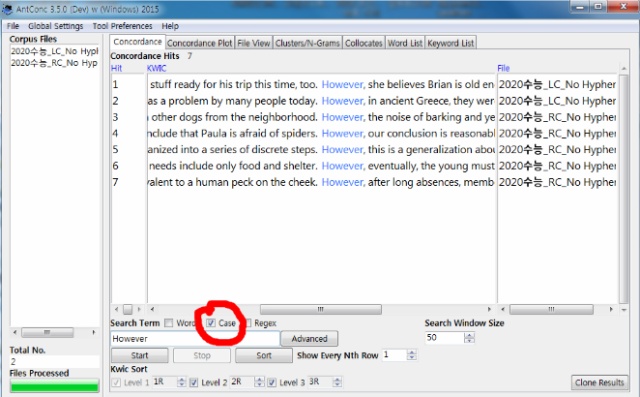
2. 혹시 각 단어가 문장의 어느 위치에 있는지 알 수 있는 방법이 있을까요?
예를 들어 sentence-initial position에 있는 however만 검색할 수 있을까요?
-> case 체크 후 검색하시면 문두에 나오는 대문자 However를 구분해서 볼 수 있습니다.
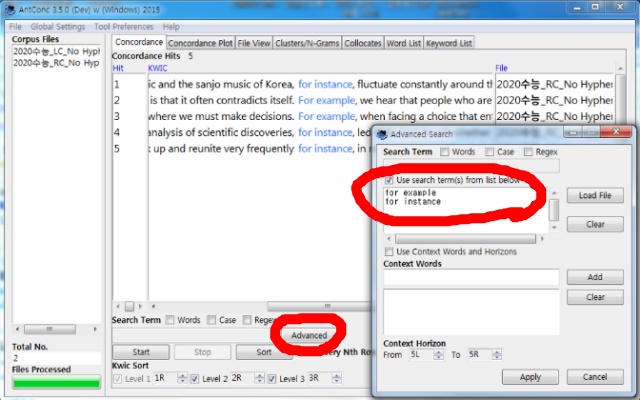
그리고 지난 글에서 문의 주셨던 검색방법도 함께 참고하시도록 올립니다.
Advanced 클릭 ->Use search terms from list below 체크 -> 하단 필드에 검색조건식 여러 개 입력 -> 적용
3. 각 코퍼스의 문장의 갯수를 알 수 있을까요?
단어 별 사용 빈도수 뿐 아니라 문장 갯수 당 사용 빈도를 구하고 싶은데 묘안이 잘 떠오르지 않아서요. '.'를 쳐서 개수를 파악하면 되려나요? 다른 방법을 혹시 알고 계신다면 알려주심 감사하겠습니다!!
-> 저는 주로 워드파일에서 물음표 느낌표 마침표를 일괄 찾기-바꾸기하여 엑셀로 옮긴 후 검토를 합니다.
간혹 Mr. Dr. U.S.A 등 문장이 아닌 경우도 있기 때문에 검수도 필요합니다.
방법은 링크 글 참고하세요. http://cafe.daum.net/eltcorpus/NKxr/58