클라우드 컴퓨팅(Cloud Computing)
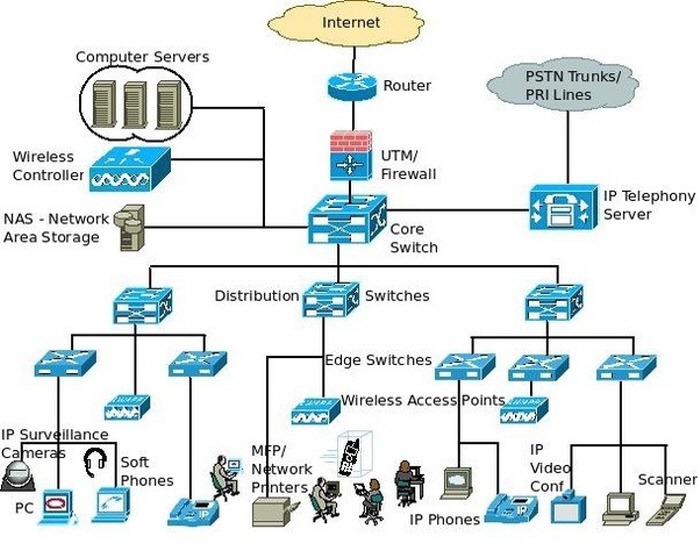
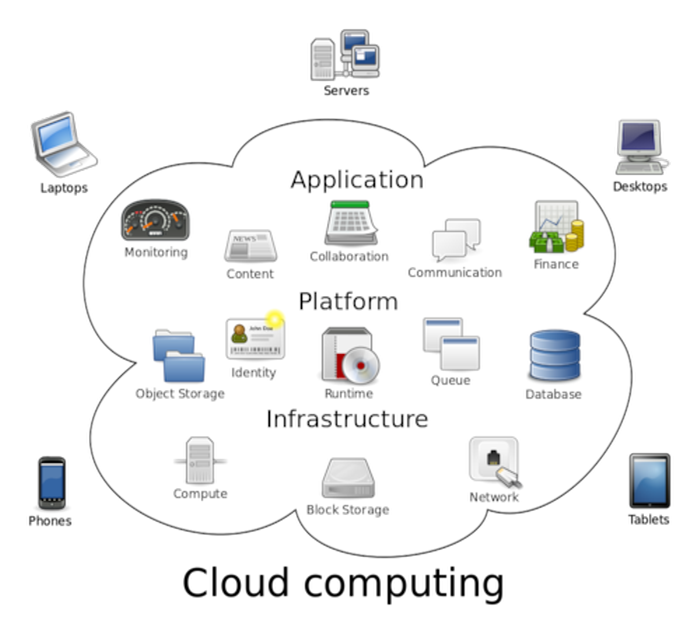
컴퓨터 통신망 관리 기법.
클라우드(Cloud)의 의미는 컴퓨터 통신망이 구름과 같은 것에 싸여 안이 보이지 않고, 일반 사용자는 이 복잡한 내부를 굳이 알 필요도 없이 어디에서나 구름 속으로 손을 집어넣어 자기가 원하는 작업을 할 수 있다는 것이다. 이른바 동일한 체험을, 인터넷이 연결된 어디에서나 보장해주는 것.
의외로 복고 열풍
정확한 개념이 의외로 복잡한데, 대부분의 작업을 온라인에 분산되어 존재하는 데이터 센터(Data Center, 이하 클라우드)에 맡겨 수행하고, 사용자의 컴퓨터는 클라우드에 접속하여 상호작용하는 단말기 역할만 하는 것이다. 이 때문에 모든 데이터와 연산 자원이 클라우드 안에만 존재하게 되며, 이 자원을 유연하게 관리하기 위해 가상화 기술 등이 투입되게 된다. 어떻게 보면 정보처리의 복고 열풍인 게, 사용자들이 단말기를 통해 메인 컴퓨터를 조작한다는 컨셉은 60~70년대의 호스트(Host)-터미널(Terminal) 구조와 정확히 일치하기 때문. 다만, 그때와는 달리 요즘은 단말기 성능도, 네트워크도 많이 좋아졌고, 아예 단말기 여러대를 연결해 슈퍼컴퓨터를 구성하는 것도 가능해졌다.
90년대 중반 인터넷이 본격적으로 세계로 퍼지기 시작했을 때 오라클이 주장한 NC의 개념과도 일치한다. 좀 범위를 넓히면 PC통신 시절 통신사들이 나눠준 단말기를 이용해 PC통신에 접속하던 것도 이것과 비슷하다 할 수 있다.
또한 인터넷 서비스 운영자의 입장에서는 직접 서버를 운영하는 대신에, Amazon Web Services, Microsoft Azure, 구글 클라우드 플랫폼 등의 대기업의 클라우드 자원을 빌려 서비스를 운영하는 편이 차후에 서비스의 규모가 커졌을 때 대처하기 편하다. 서버 세팅/확장 등은 신경쓰지 말고 서비스 운영 자체에만 집중할 수 있게 해 준다. 컴퓨팅 자원을 마치 전기 끌어다 쓰듯이 쓸 수 있도록 해 준다고 보면 된다.
또한 이러한 서비스를 이용한 실상품으로는 구글에서 추진하고 있는 크롬북이 대표적이다. 크롬북은 컴퓨터 전원을 켜면 크롬 브라우저 하나만 덩그러니 실행된다. 다른 프로그램은 어떻게 쓰냐고? 클라우드에 접속하면 문서도구, 그래픽, 게임을 불문한 모든 작업이 가능하다. 컴퓨터에 아무것도 저장하지 않은 상태로 오직 클라우드 내에서만 구글 크롬 스토어에서 취급되는 앱들을 비롯한 다양한 클라우드 앱을 이용할 수 있으므로 굳이 프로그램을 깔아서 쓸 필요가 없다는 컨셉이다. 다만 크롬북은 모든 작업을 웹과 클라우드상에서 처리하다 보니 인터넷이 없으면 말 그대로 깡통이 된다는 치명적인 단점이 있다.
애플의 맥북 에어도 어떻게 보면 비슷한데, iCloud, 드롭박스 등의 여러 클라우드 서비스 등장으로 굳이 하드 탑재로 용량을 늘릴 필요가 없어졌기에 맥북 에어의 경우 두께를 위해 용량을 희생하고 그 두께의 거의 모든 부분이 배터리 확충에 치중되고 있다. 저장 용량이 중요하지 않고 되려 사용자의 편의성과 직결되어 있는 배터리 양이 더 중요하다는 것이다. 다만 크롬북과는 달리 인터넷에 연결되지 않아도 웬만한 건 다 할 수 있기 때문에 아래에 서술된 클라우드의 단점 역시 어느 정도 극복할 수 있는 형태라는 결정적 차이점을 가진다.
과거 펜티엄 I급 컴퓨터를 어떻게든 더 오래 써먹으려고 큰 서버 2-3대나 메인프레임 1대에 수십대를 연결해서 써먹은 만파식적이라는 프로그램이 있었는데, 대한민국 최초의 상용 클라우드 컴퓨팅 시스템으로 알려져 있다.
클라우드, 그리드, 유틸리티, 서버 기반, 네트워크 컴퓨팅의 차이
클라우드 컴퓨팅은 기존 그리드 컴퓨팅, 유틸리티 컴퓨팅, 서버 기반, 네트워크 컴퓨팅을 기술적으로 발전시켜 구현화한 것이다.
그리드 컴퓨팅이란 컴퓨터 자원을 가상화시켜 공유하는 기술이고, 유틸리티 컴퓨팅은 그리드 컴퓨팅에서 더 나아가 사용된 자원만큼 돈을 지불하는 그리드 컴퓨팅의 비즈니스 모델이다. 서버 기반 컴퓨팅이란 컴퓨터 자원 소모를 다른 곳으로 옮겨 컴퓨터 자체는 더 얇게 만들 수 있게 하는 기술로 그리드 컴퓨팅에 기반을 둔다. 마지막으로 네트워크 컴퓨팅은 OS까지 가상화시켜 PC에 들어가는 자원을 최소화시키는 것이다. 즉, 클라우드 컴퓨팅이란 이러한 기술들을 종합-발전시킨 기술/비즈니스 모델이다.
요즘 뜨는 떡밥, 하지만 뜨거운 감자
2000년대 들면서 급부상한 IT떡밥 중 하나이나, 정작 통신 보안쪽으로는 크게 골머리다. 클라우드 컴퓨팅 환경에서는 사용자의 개인 정보가 클라우드에 저장되면 사실상 사용자가 그 정보의 위치를 통제할 수 없기 때문. 이를 리처드 스톨먼이 딱 한 단어, 덫(Trap)으로 지적한 바 있다. 덧붙여 사실상의 처리를 사용자의 시스템에서 처리하지 않기 때문에, 통상 시스템에 비해 트래픽이 증가하게 된다. 인터넷 종량제라도 시행했다간...컴퓨터를 켜는 거 자체가 요금 그나마 대부분의 트래픽이 클라우드 내에서 처리될 수 있다는 점에선 그리드 컴퓨팅에 비해 약과. 그리드 컴퓨팅의 경우 처리되는 모든 트래픽을 떠안아야 한다.
여하튼 가벼움이 가장 큰 장점이고, 보안 전문가들이 공밀레가 되는 대신에 일반 사용자는 보안에 그다지 신경을 쓸 필요도 없기에 MS의 OneDrive를 필두로 여러 곳에서 적극 도입이 진행 중. 아파치 소프트웨어 재단의 분산처리 프로젝트인 Hadoop 및 관련 프로젝트들은 이걸 오픈소스로 구현한 것이다.
클라우드 컴퓨팅에는 개인목적으로 저장해둔 데이터들이 사용자 본인이 아무리 관리를 철저하게 한다 해도 하루아침에 사라지거나, 전혀 상관없는 제3자에게 공개될 수 있는 매우 치명적인 단점이 존재한다. 이러한 문제가 발생하는 원인은 전적으로 당신의 데이터를 관리하는 회사에게 있다. 즉 클라우드를 관리하는 회사가 망하거나, 변심하거나, 관리를 소홀히 한다면, 이 단점이 곧바로 현실이 된다.
관리소홀로 인해 데이터가 통째로 증발한 사례는 이미 현실에서 실현되었다. 일본 퍼스트서버 사고가 그것이다. 클라우드 서비스 업체가 5698개 기업의 데이터를 몽땅 날려먹은 초대형 사고가 발생하였다.
사용자의 모든 정보는 클라우딩 서비스를 지원하는 해당 회사의 서버에 모든 데이터를 저장해둔다. 심지어 그 데이터가 어느지역 어느서버에 있는지도 알 수 없다. 그런데 이 서버를 관리하던 회사가 부도가 나버릴 경우, 대규모의 회사는 어디론가 팔려가서 데이터가 유지될지도 모르지만, 대부분은 그대로 공중분해되어 하루아침에 모든 데이터가 사라지는 비극이 벌어질 수 있다. 거기다가 막말로 그 데이터 담아둔 서버가 전부 본사가 직접 갖고 있는 서버여야만 한다는 법도 없는 현실에, 어느 클라우드 회사의 하청을 맡아서 서버 일부를 관리하고 있던 회사에서 데이터를 빼돌린다던지... 아니면 어디선가 망한 회사의 클라우드 서버를 사들여서 저장돼있는 데이터를 개인목적으로 사용한다면... 더 이상의 자세한 설명은 생략한다
차라리 망하면 다행인데 더 끔찍한 비극은 클라우드를 관리하는 회사가 임의로 사용자의 정보를 제3자에게 제공하는 경우다. 회사의 마케팅 차원에서 정보분석용으로 몰래 사용할 수도 있고, 특정국가의 수사 협조를 명목으로 공공기관에 임의로 데이터를 공개할 수도 있고, 회사의 임의가 아닌 해킹으로 인해 자신의 데이터가 제3자에게 공개되거나, 단순한 운영진의 실수로도 공개될 수 있다. 물론 애초부터 개인전용 스토리지로 사용되는 경우가 훨씬 많기 때문에 이런 가능성은 매우 드물다.
어쨌든 이는 클라우드 회의론의 주요 떡밥이며, 이 부분은 전적으로 회사의 이미지와 직결되기 때문에 회사 규모가 크고 좋은 이미지가 쌓인 회사일수록 서버 관리에 철저해질 수밖에 없다. 자의든 타의든 유출되는 순간 그 회사의 이미지는 나락으로 떨어진다.
그렇기 때문에 클라우드의 선택기준은 빵빵한 무료용량보다는 회사의 신용도가 더 중요한 선택 기준이 된다. 그리고 어떤 보안이든 부주의와 내부 침입에는 취약하니 진짜 중요한 데이터는 클라우드 이외의 매체에도 따로 보관해야 한다.
6. 국내에서의 연구
국내에서는 네이버나 Daum, SKT, KT 등 일부 대기업에서 적극적인 개발에 뛰어들고 있었지만 교육계선 그다지 호의적이지 않았어서 2011년만 해도 극히 일부 대학교가 가르치는 형편이었으나 2012년부터는 한국에서도 도입하는 업체 및 연구기관이 많아졌다. 특히 빅 데이터(Big Data) 분석에 대한 요구가 크게 증가하여 각종 학회가 난립(…)하기 시작했다. 관련 도서의 수도 크게 증가하여 Hadoop뿐만 아니라 Mahout, HBase 등 Hadoop 관련 프로젝트들에 대한 도서가 많이 발간되었다. 직접 쓰고 싶다면 Hadoop 사이트에서 직접 다운로드해 VirtualBox 등을 통해 써도 되고 KT MapReduce를 빌려서 써도 된다.
구름이란 의미답게 정의도 뜬구름 잡는 듯한 것이 많다. 용어 자체가 굉장히 넓은 범위를 포함하고 있으며, 사람마다 정의하는 의미가 전부 다르다. 실제로 관련 서적을 봐도, 기본적인 내용은 다 같을지라도 세부적인 정의가 전부 다 다르다.
K모 대학에서 관련된 강의를 했었던 기업에서 실무를 담당하고 있는 누군가의 말을 빌리자면, "누군가와 클라우드 컴퓨팅에 대해 토의할 일이 있으면 시간의 80%를 그 사람이 생각하는 클라우드와, 내가 생각하는 클라우드를 비교하는데 쓴다."라고 했을 정도로 사람마다, 기업마다, 부서마다 생각하는 게 다르다.