부스팅 ( Boosting )
◈ 부스팅이란?
약한 학습기들의 성능을 올려서 강한 학습기의 성능을 얻는 방법.
◈ 배깅과 차이점?
부스팅은 순차적 방법.
배깅은 분산이 큰 모형에 적합 ( 예측 모형의 변동성이 큰 경우 )
배깅의 경우 각각의 분류기들이 학습 시에 서로 상호 영항을 주지 않고 그 결과를
종합하는 반면, 부스팅은 이전 분류기의 학습 결과를 토대로 다음 분류기의 학습
데이터의 샘플 가중치를 조정하여 학습을 진행함.
< 비교 >
기존 앙상블 : 하나의 전체 데이터를 활용하여 서로 다른 학습 분류기를 통합하는 방법
배깅 : 전체 데이터에서 여러 샘플링 데이터를 추출하여 서로 다른 학습 분류기를 통합하는 방법
부스팅 : 전체 데이터에서 여러 샘플링 데이터를 추출하여 순차적으로 이전 학습 분류기의 결과를 토대로 다음 학습 데이터의 샘플 가중치를 조정하면서 학습을 진행
◈ 부스팅 알고리즘
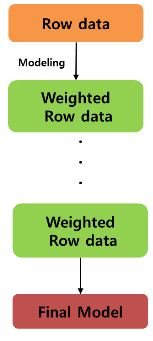
1. 가중치가 없는 상태에서 첫 번째 분류기 모델화
2. 분류기가 바르게 예측한 예제는 다음 분류기에서 훈련데이터로 덜 나타낸다. 반대로 분류하기 어려운 예제는 더 자주 나타난다.
3. 추가적으로 약한 학습기를 더해 분류가 어려웠던 객체들을
데이터로 훈련한다.
4. 원하는 전체적인 오차 비율에 도달할 때까지 계속 하거나
성능이 더 이상 향상되지 않을 때까지 실행한다.
◈ 부스팅 분류기 실행 방법
install.packages("adabag")
library(adabag)
set.seed(300)
model_ada <- boosting(default~. , data=credit )
predict_ada <- predict(model_ada, credit )
##: class 서브객체에 저장됨
##예측 결과 확인
predict_ada$confusion