[쉬움주의] 앙상블 적용 타이타닉 (XGboost)
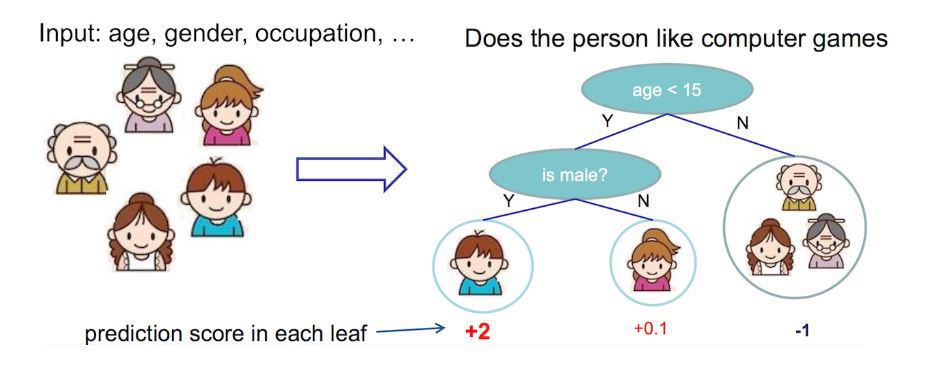
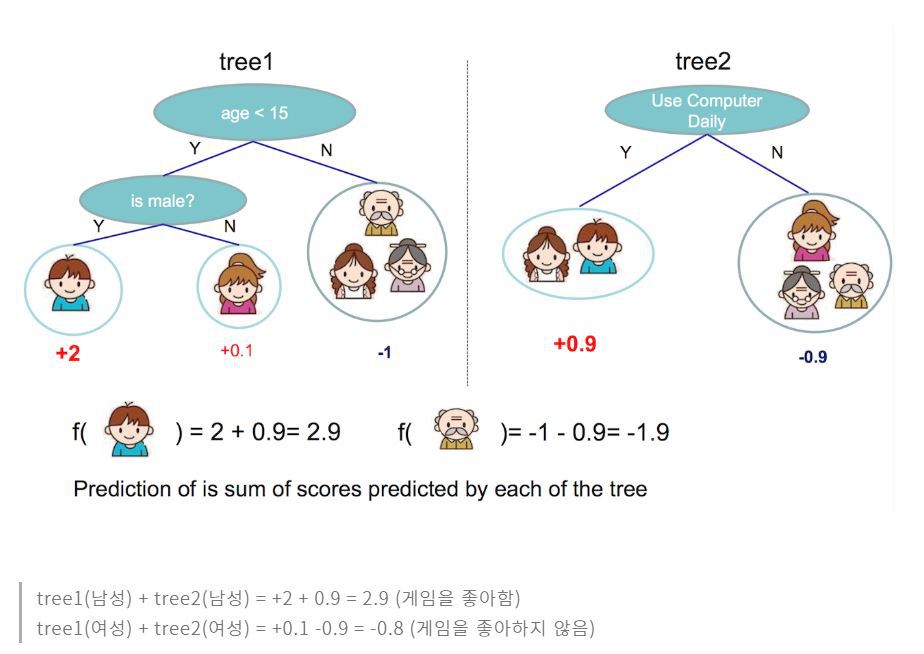
# -*- coding: utf-8 -*-
### 기본 라이브러리 불러오기
import pandas as pd
import seaborn as sns
'''
[Step 1] 데이터 준비/ 기본 설정
'''
# load_dataset 함수를 사용하여 데이터프레임으로 변환
df = sns.load_dataset('titanic')
# IPython 디스플레이 설정 - 출력할 열의 개수 한도 늘리기
pd.set_option('display.max_columns', 15)
'''
[Step 2] 데이터 탐색/ 전처리
'''
# NaN값이 많은 deck 열을 삭제, embarked와 내용이 겹치는 embark_town 열을 삭제
rdf = df.drop(['deck', 'embark_town'], axis=1)
# age 열에 나이 데이터가 없는 모든 행을 삭제 - age 열(891개 중 177개의 NaN 값)
rdf = rdf.dropna(subset=['age'], how='any', axis=0)
# embarked 열의 NaN값을 승선도시 중에서 가장 많이 출현한 값으로 치환하기
most_freq = rdf['embarked'].value_counts(dropna=True).idxmax()
rdf['embarked'].fillna(most_freq, inplace=True)
'''
[Step 3] 분석에 사용할 속성을 선택
'''
# 분석에 활용할 열(속성)을 선택
ndf = rdf[['survived', 'pclass', 'sex', 'age', 'sibsp', 'parch', 'embarked']]
# 원핫인코딩 - 범주형 데이터를 모형이 인식할 수 있도록 숫자형으로 변환
onehot_sex = pd.get_dummies(ndf['sex'])
ndf = pd.concat([ndf, onehot_sex], axis=1)
onehot_embarked = pd.get_dummies(ndf['embarked'], prefix='town')
ndf = pd.concat([ndf, onehot_embarked], axis=1)
ndf.drop(['sex', 'embarked'], axis=1, inplace=True)
'''
[Step 4] 데이터셋 구분 - 훈련용(train data)/ 검증용(test data)
'''
# 속성(변수) 선택
X=ndf[['pclass', 'age', 'sibsp', 'parch', 'female', 'male',
'town_C', 'town_Q', 'town_S']] #독립 변수 X
y=ndf['survived'] #종속 변수 Y
# 설명 변수 데이터를 정규화(normalization)
from sklearn import preprocessing
X = preprocessing.StandardScaler().fit(X).transform(X)
# train data 와 test data로 구분(7:3 비율)
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=10)
print('train data 개수: ', X_train.shape)
print('test data 개수: ', X_test.shape)
print('\n')
'''
[Step 5] SVM 분류 모형 - sklearn 사용
'''
from xgboost import XGBClassifier
xgb_model = XGBClassifier()
xgb_model.fit( X_train, y_train)
y_hat = xgb_model.predict( X_test )
print ( y_hat )
print(y_hat[0:10])
print(y_test.values[0:10])
print('\n')
# 모형 성능 평가 - Confusion Matrix 계산
from sklearn import metrics
svm_matrix = metrics.confusion_matrix(y_test, y_hat)
print(svm_matrix)
print('\n')
# 모형 성능 평가 - 평가지표 계산
svm_report = metrics.classification_report(y_test, y_hat)
print(svm_report)
from sklearn.metrics import cohen_kappa_score
result = cohen_kappa_score( y_test, y_hat )
print ( result )