beyond reason
잠시 빅데이터에 대해 몰입하기

AI 빅데이터 전문가는 복잡한 대량의 데이터를 구조화하고 분석하는 일을 한다. 현대사회에서는 무한히 많은 데이터들이 홍수처럼 쏟아지고 있다. 우리가 매일 사용하는 문자 메시지, 뉴스, 댓글, 상품후기, SNS피드들이 모두 하나하나의 데이터가 될 수 있다.
AI 빅데이터 활용사례
1) 맞춤형 추천
영국의 아비바 생명은 운전자의 운전패턴에 기반을 둔 맞춤형 보험상품을 제공하고 있는데 이를 위해 '차량내 운행기록 장치를 통해 실제 운전형태를 수집, 분석'하고 있으며 주로 운전하는 시간과 지역 등을 감안해 보험료를 산정하고 있는 '운전한 만큼 지불하는 pay as you drive상품인 레이트마이드라이브(rate my drive)를 내놓아 고객들로부터 호평을 얻었다.
저가 항공사의 대명사인 사우스웨스트 항공으 비행기 좌석 스크린에 승객별로 다른 광고를 제공하고 있는데 미국인의 96%를 비롯해 전 세계적으로 5억명에 달하는 고객정보를 갖고 있는 액시엄의 DB에 저장되어 있는 항공기 탑승객의 쇼핑습관과 구매패턴 등을 분석한 후 승객별로 최적화된 광고를 제공하고 있다.
2) 기업내부 프로세스 효율적 개선
SPA기업의 대표적인 주자 중 하나인 자라는 빅데이터를 분석을 활용해 전세계 매장의 판매현형을 실시간으로 분석한 뒤 고객 수요가 높은 의류를 실시간으로 공급할 수 있는 물류망을 구축함으로써 재고부담을 줄이고 매출은 극대화하는 성과를 거두고 있다.
3) 재해 예측 및 예방
AI빅데이터는 재난이나 재해를 예측하고 예방하는데에도 도움을 줄 수 있다. 구글의 'flu trend'는 일반적으로 사람들이 감기에 걸리면 병원을 가기 전에 관련 단어를 검색하는데 착안해 검색정보와 위치기반해 감기바이르스 확산 상황을 알려주는 서비스를 제공하고 있다.
4) 의료 및 헬스케어 서비스 활용
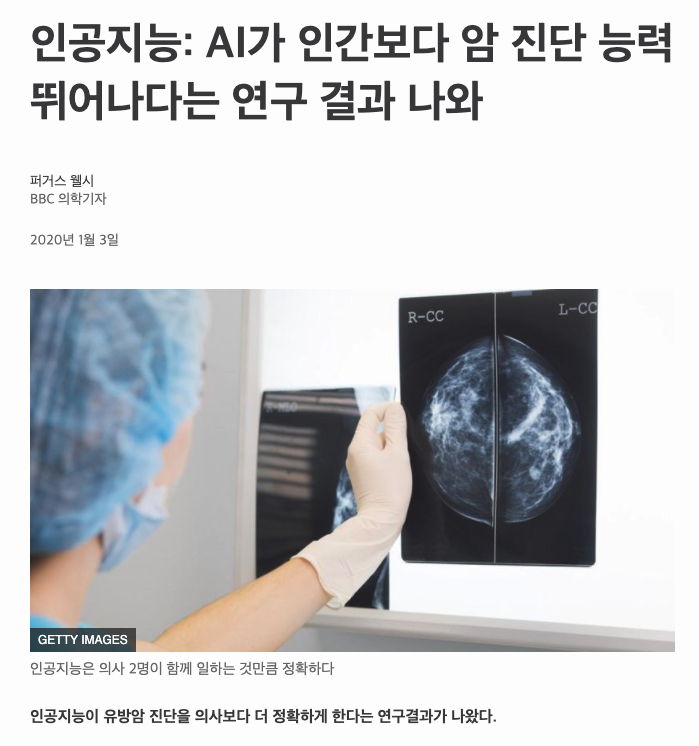
5) 개개인의 사생활과 가정에 활용
AI스피커는 음성인식을 통해 음악감상, 정보검색 등의 기능을 수행할 수 있다.
자율주행차의 확대로 더이상 운전자가 필요없는 자동차가 일반화될 것이다.
6) 보안 및 사아버테러 대응
비정형 데이터
unstructured data
미리 정의된 데이터 모델이 없거나 미리 정의된 방식으로 정리되지 않은 정보
가장 전형적인 비정형 데이터로 텍스트가 있다. 신문, 잡지, 책과 같은 전통적인 방식과 더불어 페이스북, 인스타그램, 트위터와 같은 SNS기록, 이메일, 인터넷 기사 댓글 등에서 엄청나게 많이 생성된다. 이러한 비정형 데이터를 이용해 많은 인사이트를 도출할 수 있다.
데이터 마이닝(data mining)
텍스트 마이닝
데이터마이닝은 데이터 분석을 통해 아래와 같은 분야에 적용하여 결과를 도출할 수 있다.
- 분류(Classification): 일정한 집단에 대한 특정 정의를 통해 분류 및 구분을 추론한다 (예: 경쟁자에게로 이탈한 고객)
- 군집화(Clustering): 구체적인 특성을 공유하는 군집을 찾는다. 군집화는 미리 정의된 특성에 대한 정보를 가지지 않는다는 점에서 분류와 다르다 (예 : 유사 행동 집단의 구분)
- 연관성(Association): 동시에 발생한 사건간의 관계를 정의한다. (예: 장바구니안의 동시에 들어 가는 상품들의 관계 규명)
- 연속성(Sequencing): 특정 기간에 걸쳐 발생하는 관계를 규명한다. 기간의 특성을 제외하면 연관성 분석과 유사하다 (예: 슈퍼마켓과 금융상품 사용에 대한 반복 방문)
- 예측(Forecasting): 대용량 데이터집합 내의 패턴을 기반으로 미래를 예측한다 (예: 수요예측)
알고리즘(algorithm)
대부분의 알고리즘은 유한한 수의 규칙에 따라 구별 가능한 기호들을 조작하여 입력 정수에서 출력 정수를 생성하기 위한 일반화된 작업을 정의한다. 다음은 좋은 알고리즘의 특징이다.
- 정밀성 : 변하지 않는 명확한 작업 단계를 가져야 한다.
- 유일성 : 각 단계마다 명확한 다음 단계를 가져야 한다.
- 타당성 : 구현할 수 있고 실용적이어야 한다.
- 입력 : 정의된 입력을 받아들일 수 있어야 한다.
- 출력 : 답으로 출력을 내보낼 수 있어야 한다.
- 유한성 : 특정 수의 작업 이후에 정지해야 한다.
- 일반성 : 정의된 입력들에 일반적으로 적용할 수 있어야 한다.
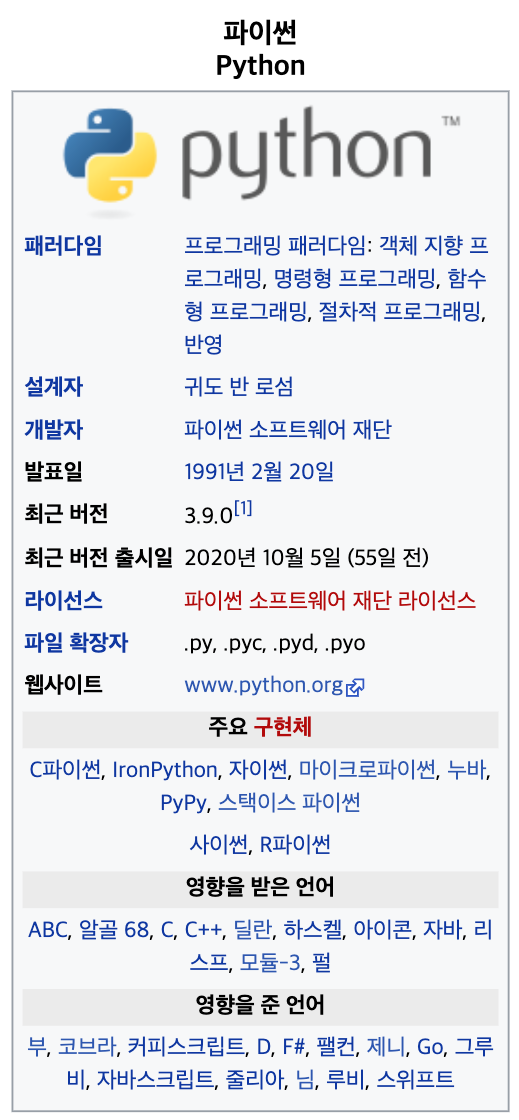
파이썬(python)
파이썬은 다양한 프로그래밍 패러다임을 지원하는 언어이다. 객체 지향 프로그래밍과 구조적 프로그래밍을 완벽하게 지원하며 함수형 프로그래밍, 관점 지향 프로그래밍 등도 주요 기능에서 지원 된다.
파이썬의 핵심 철학은
- "아름다운 게 추한 것보다 낫다." (Beautiful is better than ugly)
- "명시적인 것이 암시적인 것 보다 낫다." (Explicit is better than implicit)
- "단순함이 복잡함보다 낫다." (Simple is better than complex)
- "복잡함이 난해한 것보다 낫다." (Complex is better than complicated)
- "가독성은 중요하다." (Readability counts)
데이터 과학자
1) 컴퓨터 과학 - 프로그래밍, 개인정보 및 보안, 클라우드 컴퓨팅, 분산 시스템, 기술과 인프라
2) 분석학 - 특성추출공학, 자연어 처리, 과학적 통계, 인공지능, 그래프 분석, 데이터 및 텍스트 마이닝, 예측모델링
3) 데이터베이스 - 메시업, 정보추출, 데이터 웨어하우스, 데이터 관리
4) 예술 및 디자인 - 시각화, 의사소통
5) 기업가 정신 - 윤리학, 데이터 제품 디자인, 도메인 지식
예를들면 파이썬 언어로 텍스트 마이닝(자연어 처리) 기법을 이용하고 연구대상으로는 SNS상의 온라인 리뷰를 주로 삼는다. 데이터베이스는 No-SQL을 사용한다.
전문가에 요구되는 가장 중요한 능력 중 하나가 비즈니스 환경의 문제를 인식하고 데이터가 주어졌을때 주어진 데이터로 어떻게 비즈니스 문제를 풀 것인가 고민하는 능력이다. 큰 숲을 잘 정리하고 세부적으로 데이터 분석을 실행해야 한다.
분석 프로세스 모델
1) 기업문제 인식
2) 데이터 파악
3) 데이터 선택
4) 데이터 정제
5) 데이터 가공
6) 데이터 분석
7) 데이터 해석 및 평가
8) 데이터 활용
9) PDCA
AI 빅데이터 공부의 첫걸음
1) AI 빅데이터 분석으로 해결 가능한 문제들
가장 처음 시작해야 할 공부는 '수학, 코딩, 알고리즘' 등이 아니다. 경영학적으로 기업문제들이 발생했을때 어떤 데이터 분석기법으로 문제를 해결해야 하는지를 알아야 한다.
1개월에 300명 초진환자. 월 2천명 래원환자
1명에 10개 미만의 데이터베이스
상관관계 분석
문제해결 - 고객감동, 고객유치
2) AI 빅데이터 분석에 대해 살펴보기
기본적인 AI빅데이터의 개념부터 등장배경, 특성, 저장 및 처리 기술들에 대해서 알아야 한다. 전통적인 데이터와는 다르게 빅데이터의 특성에 무엇이 있고 저장 및 처리기술에 어떤 것이 있는지 정도만 알면 된다.
3) 빅데이터 공부에 도움이 될만한 책들
- 빅데이터 기초 : 개념, 동인, 기법

- 인공지능 시대의 비즈니스 전략

- 빅데이터가 만드는 제 4차 산업혁명

빅데이터 비즈니스 이해와 활용

빅데이터 분석과 활용

실제 현장에서 일할때 가장 중요하지만 어려운 것 중에 하나가 비즈니스 문제를 어떻게 정의하고 이 문제를 해결하기 위해서 어떤 데이터로 접근하는가다.
데이터 마이닝 분석 및 방법론
1) 데이터에 대한 이해
데이터의 종류에는 '명목 데이터, 이진 데이터, 순서 데이터, 숫자 데이터, 이산/연속형 데이터'가 있다.
명목데이터 - 사물의 기호나 이름과 같은 데이터
이진 데이터 - 0과 1로 이루어진 데이터
순서 데이터 - 상중하처럼 등급이나 계급이 있는 데이터
숫자 데이터 - 절대영점을 가지고 있으면 비율척도 데이터, 없으면 등간척도 데이터
이산/연속형 데이터 - 정수형이나 연속형이냐에 따라 이산/연속형 데이터로 나눈다.
평균, 중위값, 최빈값, 표준편차, 사분위수
2) 데이터 전처리 기술
데이터 정제(결측치 제거 또는 대치, 노이즈 제거)
데이터 통합(중복데이터 처리, 복사, 단위통합)
데이터 축소(주성분 분석, 속성선택법, 샘플링)
데이터 변환(데이터 정규화, 비닝)
3) 데이터 분석 알고리즘
연관관계 분석
상관관계 분석
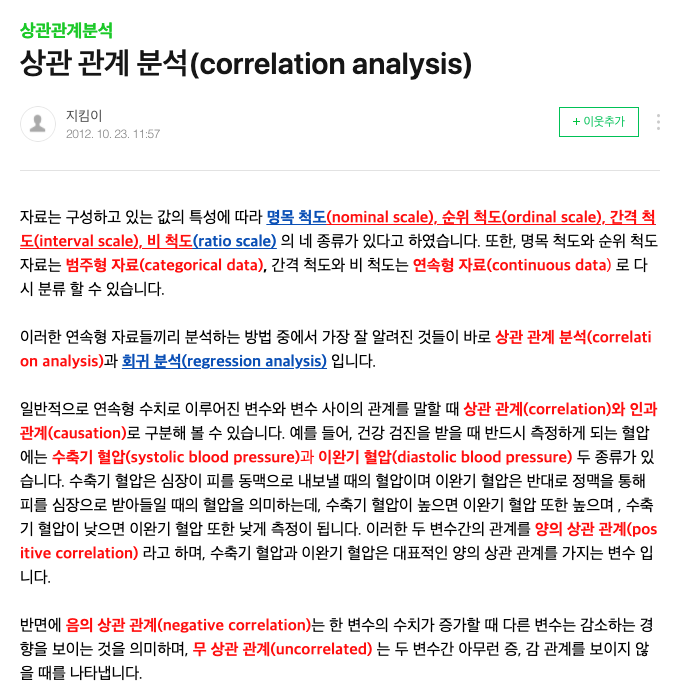
빈발패턴 분석
클래스 분류 분석
클러스터 분석
회귀 분석
아웃라이어 분석
각 분석들을 세부적으로 살펴보면 수많은 알고리즘이 있다.
예를들어 클래스 분류 분석은 '의사결정 나무, 서포트백터 머신, 베이즈 분류, 램덤 포레스트, 배깅, 부스팅, KNN, 피드포워드 신경망, 퍼지세트 등' 수 많은 알고리즘이 있다.
여기까지 공부하면 데이터 마이닝에 대한 기본개념은 익힌 것이다.
다음 단계 책
1) 데이터 마이닝 개념과 기법
2) 패턴인식
3) 데이터 마이닝 기법과 응용
최소한의 자격증
'한국 데이터베이스 진흥원"
사회조사분석사 시험
SQL(structured query language) 국가공인 전문가과정
코딩공부 '파이썬과 R언어"
수리통계학 공부
통계학의 수학적 이론으로 확률모형, 통계적 추정이론과 검정이론, 계산 알고리즘의 성질 등을 탐구하는 학문
'정규분포, 지수분포, 감마분포, 카이제곱분포, 포아송분포, 이항분포'
1) 정규분포(가우스 분포)
확률론과 통계학에서, 정규 분포(正規 分布, 영어: normal distribution) 또는 가우스 분포(Gauß 分布, 영어: Gaussian distribution)는 연속 확률 분포의 하나이다. 정규분포는 수집된 자료의 분포를 근사하는 데에 자주 사용되며, 이것은 중심극한정리에 의하여 독립적인 확률변수들의 평균은 정규분포에 가까워지는 성질이 있기 때문이다.
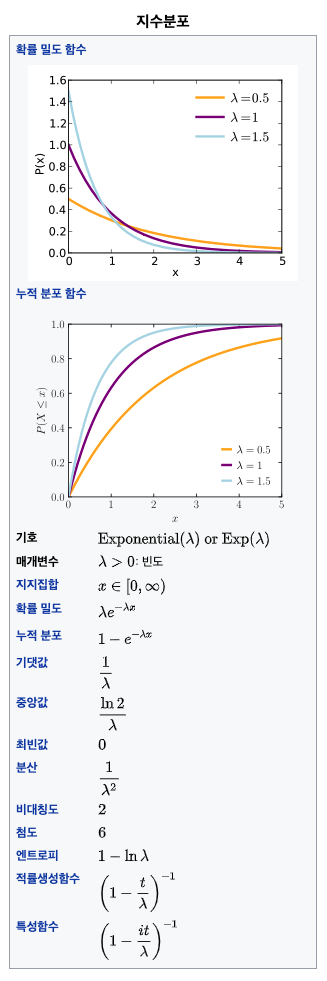
2) 지수분포
확률론과 통계학에서, 지수분포(指數分布, 영어: exponential distribution)는 연속 확률 분포의 일종이다. 사건이 서로 독립적일 때, 일정 시간동안 발생하는 사건의 횟수가 푸아송 분포를 따른다면, 다음 사건이 일어날 때까지 대기 시간은 지수분포를 따른다
3) 푸아송 분포
푸아송 분포(Poisson分布, 영어: Poisson distribution)는 확률론에서 단위 시간 안에 어떤 사건이 몇 번 발생할 것인지를 표현하는 이산 확률 분포이다.
- 일정 주어진 시간 동안에 도착한 고객의 수
- 1킬로미터 도로에 있는 흠집의 수
- 일정 주어진 생산시간 동안 발생하는 불량 수
- 하룻동안 발생하는 출생자 수
- 어떤 시간 동안 톨게이트를 통과하는 차량의 수
- 어떤 페이지 하나를 완성하는 데 발생하는 오타의 발생률
- 어떤 특정 량의 방사선을 DNA에 쬐였을 때 발생하는 돌연변이의 수
- 어떤 특정 면적의 다양한 종류의 나무가 섞여 자라는 삼림에서 소나무의 수
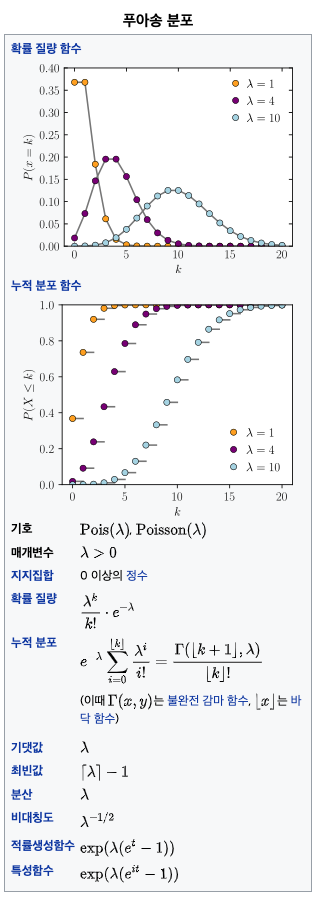
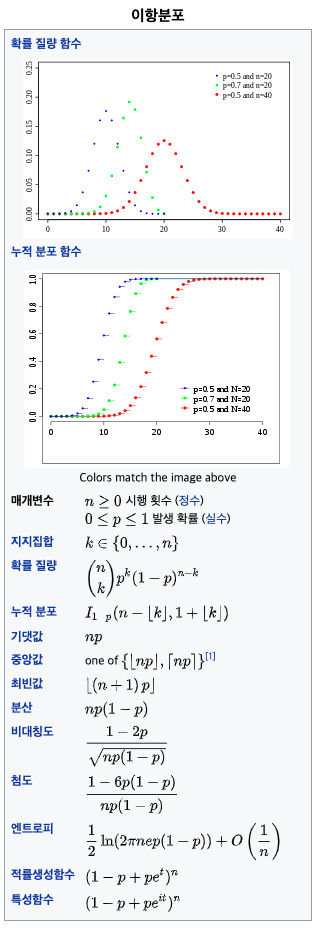
4) 이항분포
이항 분포(二項分布)는 연속된 n번의 독립적 시행에서 각 시행이 확률 p를 가질 때의 이산 확률 분포이다. 이러한 시행은 베르누이 시행이라고 불리기도 한다. 사실, n=1일 때 이항 분포는 베르누이 분포이다.
딥러닝에 관한 공부
딥러닝을 구현하기 위한 두가지 요건 '충분히 많은 데이터의 양과 연산가능한 컴퓨터'

홍콩 과기대 교수 '김성훈 교수' 강의
데이터베이스에 대한 기본적인 이론을 익혀라
캐글경연대회
캐글은 2010년 설립된 예측모델 및 분석대회 플랫폼
전문연구분야를 정하기
1) 텍스트 마이닝
2) 추천 알고리즘
3) 영상처리 분석
4) 이상탐지
5) 이미지 분석
6) 딥러닝
7) 기계학습
8) 시뮬레이션
9) 금융공학
텍스트 마이닝에서 중요한 것
1) 전처리 단계 - 단어추출, 단어정제, 단어마다의 가중치생성
2) 분석 단계 - 토픽모델링, 감성분석(sentiment analysis), 문서요약, 단어네트워크
참고) 토픽모델
기계 학습 및 자연언어 처리 분야에서 토픽 모델(Topic model)이란 문서 집합의 추상적인 "주제"를 발견하기 위한 통계적 모델 중 하나로, 텍스트 본문의 숨겨진 의미구조를 발견하기 위해 사용되는 텍스트 마이닝 기법 중 하나이다. 특정 주제에 관한 문헌에서는 그 주제에 관한 단어가 다른 단어들에 비해 더 자주 등장할 것이다. 예를 들어 개에 대한 문서에서는 "개"와 "뼈다귀"라는 단어가 더 자주 등장하는 반면, 고양이에 대한 문서에서는 "고양이"와 "야옹"이 더 자주 등장할 것이고, "그", "~이다"와 같은 단어는 양쪽 모두에서 자주 등장할 것이다. 이렇게 함께 자주 등장하는 단어들은 대게 유사한 의미를 지니게 되는데 이를 잠재적인 "주제"로 정의할 수 있다. 즉, "개"와 "뼈다귀"를 하나의 주제로 묶고, "고양이"와 "야옹"을 또 다른 주제로 묶는 모형을 구상할 수 있는데 바로 이것이 토픽 모델의 개략적인 개념이다. 실제로 문헌 내에 어떤 주제가 들어있고, 주제 간의 비중이 어떤지는 문헌 집합 내의 단어 통계를 수학적으로 분석함으로써 알아 낼 수 있다.
참고) 감성분석(Sentiment Analysis)
감성 분석(Sentiment Analysis)이란 텍스트에 들어있는 의견이나 감성, 평가, 태도 등의 주관적인 정보를 컴퓨터를 통해 분석하는 과정입니다. 자연어 데이터에 들어있는 감성을 분석하는 일은 오래 전부터 연구되어왔습니다. 그럼에도 언어가 가지고 있는 모호성 때문에 쉽지 않았던 것이 사실입니다. 아래의 예시를 통해 어떤 어려움이 있는 지 보도록 하겠습니다.
“Honda Accords and Toyota Camrys are nice sedans.” (혼다 어코드와 도요타 캠리는 좋은 세단이다.)
위 문장은 혼다와 도요타의 차종 각각에 대해서 긍정을 나타내고 있습니다. 하지만 추가적인 내용이 붙었을 때 이들에 대한 평가가 달라지는 경우도 있습니다. 아래 문장을 보도록 하겠습니다.
“Honda Accords and Toyota Camrys are nice sedans, but hardly the best car on the road. (혼다 어코드와 도요타 캠리는 좋은 세단이지만,도로에서 가장 좋은 차는 아니다.)”
위와 같은 추가 설명이 붙는다면 위 문장은 대상에 대해 긍정을 표하고자 하는 문장인지, 부정을 표하고자 하는 문장인지 파악하기 매우 어렵게 됩니다. 이러한 언어의 모호성은 감성 분석을 어렵게 하는 원인이 됩니다.
감성 분석이 사용되는 곳은 다양합니다. 기업 내부적으로는 고객 피드백, 콜센터 메시지 등과 같은 데이터를 분석하며 외부적으로는 기업과 관련된 뉴스나 SNS 홍보물 등에 달린 댓글의 긍/부정을 판단하는 곳에 사용되고 있습니다. 개인 단위에서는 영화를 보기 전에 리뷰를 참고하는 것과 같이 특정 제품이나 서비스를 이용할 지를 결정하는 데에 사용할 수 있습니다. (우리는 단지 머신러닝 방법론을 사용하지 않았을 뿐 은연중에 감성 분석을 하고 있습니다.) 이외에도 광고의 효율을 높이거나 특정 약품이 사람들에게 실제로 효과가 있는 지를 알아보는 데에도 사용할 수 있습니다.
이미지 분석에서 중요한 것
1) 전처리 단계 - 이미지 특징추출
2) 분석단계 - 이미지 분포, 이미지 경계선 추출, 유사한 이미지 판별 등
한가지 언어만 잘하면 된다
AI 빅데이터 분석을 위해서는 대표적으로 '파이썬, R, 스파크'가 쓰인다. 이책에서는 파이썬과 R언어를 추천했다.
빅데이터 전문가과정은 오래 걸리지 않는다. 1년정도 열심히 하다보면 어느덧 전문가가 되어 있다. 1년만 공부하면 전문가가 될 수 있다.