회사에서 다른 일 하다가 개발자 없으니까 수학과 출신 데이터 분석가들(애네들은 기본적으로 R이나 python을 배웁니다. ) 에게 서비스 application 개발을 맡겼는데 만들어 놓은 거 보면 완전 개쓰레기로 만들었습니다. -_-;;
이건 흔하게 나오는 문제긴 한데, 나름 고~~~급 학력자들이라 지들이 일 못한거 자체를 인정하지 않고 원색적인..(예..원색적인.ㅋㅋㅋㅋ) 문구 써가면서 ㅄ 새끼가 일 X도 모르는 놈이 깝친다고 심지어는 내부자 해킹(.....)으로 DB를 삭제하기까지 했어요..
대개 개인적인 데이터 분석 수준에서 다루는 개발과 실무에서 대고객 서비스 (특히 B2B는) 구성 형태가 많이 다릅니다. 여기 의외로 개발 꿈나무도 있으니 몇 가지 이야기를 해 볼께요..
1. DATABASE 관리
가 ) 실무에서는 super admininistrator 급 계정으로는 작업하지 않습니다.
보통 sa나 root 또는 admin 이른 이름으로 나오는 계정들이 있고, 개발 서적에서는 기본적으로 이런 부분을 다루지 않는데, 실무에서 spuer admininistrator 급 계정으로 무언가를 하는 일은 없습니다.
DB 설치하고 제일 먼저 하는게 저런 기본 계정 block 처리하고( 대체로 비활성화, 원격 접속 금지..) DB 관리자들을 위해서 일부에게 개인별로 super administrator 등급을 가진 계정을 발급해서 각자 씁니다. ( 당연히 문제 생기면 누가 했는지 추적하기 위해서겠죠?)
이 사람들.. 열어보니 당당하게 python 스크립트(.....) 내부에다가 sa 계정에 id / pw 박아놓고 쓰던데.. 당연히 이러면 안됩니다.
나 ) 실무에서 original database를 공공망에 공개하지 않습니다.
정보 수정이 필요한 계정은 대개 따로 발급을 하구요.. 보통은 읽기 전용 DB를 구축하거나 SELECT만 되는 계정을 따로 발급합니다. 예. 대다수의 서비스는 DB의 데이터를 읽어다가 쓰는 거기 때문에 굳이 UPDATE니 INSERT를 하지 않아요. (게시판이나 만드는 수준에서는 이해하기 어렵겠지만..)
그러니까 데이터의 수정이 가능한 DB는 굳이 인터넷 망에 연동시킬 필요가 없는 거죠. 심지어 주먹구구로 돌리는중소기업들도 가급적 private 망에 넣어서 운영합니다.
다 ) 실무에서는 fail over를 준비해 놓습니다.
뭔가 DB에 문제가 생겨도 서비스가 가능하게 대비를 합니다. 대개 이중화 또는 fail over 체제를 갖추는 건데.. 예전에는 이걸 일일이 구축을 해야 해서 어려웠지만 지금은 AWS 상에서 어지간하면 지원을 해줍니다. 백업 플랜도 존재하구요.
즉 실무에서는 핵심 기능과 비핵심 기능을 분류하고 장애가 발생한 상태에서도 핵심 기능은 제공이 되어야 하는 것이 매우 중요합니다. 이건 단순히 개발 스킬로만 해결되는 문제가 아닙니다. 서비스와 사업에 대한 전반적인 이해를 요구하고, 또한 비IT 부서에 어느 선까지 재해 대비를 할 것인지에 대한 의사 결정 과정이 필요합니다.
너네들이 그냥 코드 까서 함수 만드는게 개발자의 일이 아닌거고, 이런 당신들이 말단 개발자라고 해도 이런 의사결정을 할 수 있는 자료와 범위를 정리해서 보고를 해야 하는 겁니다. 이게 일인 겁니다.
라 ) 애플리케이션 개발 시 경합( contention ) 과 교착 상태 ( deadlock ) 에 대한 고려를 하고 개발을 해야 합니다.
책만 보고 개발하는 실무 모르는 개발 한다는 사람들이 가장 많이 일반적으로 잘못하는 부분인데.. 혼자 개발한거 혼자 DB에 붙어서 혼자서 구동하는 거면 생기지 않을 문제입니다. ( 대다수 비전공자들은 multi thread나 multi process를 구현하지 않을 것이기 때문에..) 그리고 요즘의 DB 접속을 관리하는 라이브러리들, 그리고 DB 자체도 어느 정도는 이런 문제들을 관리를 해 줍니다.
그러나 DB 입장에서.. 서로 다른 사용자들이 동시에 같은 메모리에 있는 정보를 읽고 쓰는 것을 완전히 동시에 처리하는 것은 굉장히 논리적 난제입니다. 왜냐하면 동시에 도착했다고 해도 읽는 과정과 쓰는 과정 자체가 미세하나마 시간이 걸리는 작업이니까요 실무용 DB책들을 보면 가장 먼저 강조되는 부분이며, 근본적으로 담당자가 프로그램을 엉터리로 짜면 어쩔 수 없습니다.
당연한 일이지만 이것은 RDBMS( Relational Database Management System )라고 하는 것에 대한 기본적인 이해를 요구합니다. 데이터 분석을 다루는데 굳이 RDBMS를 사용하는 일은 거의 없고(그럴 용도로 만든 물건이 아닌 고로..) 쓴다고 해도 극소수의 사용자가 단순한 작업(예.. 어플리케이션과 DB 관점에서는 엄청나게 단순한 작업들의 반복일 뿐입니다. )만 하기 때문에 RDBMS와 SQL의 본래 목적성과 성능을 충분히 살려내지 못합니다.
언급했듯... 개인이 돌리는 수준이면 별 문제가 없겠습니다만, 서비스를 확장하기 시작하면 이 관점이 결여된 상태에서 만든 코드들은 대부분 심각한 문제를 일으킵니다. ( 최악의 경우 DB의 물리적 OBJECT를 손상시키거나, DEAD LOCK이 복구되지 않아 아예 DMBS를 재기동 해야 하는 막장 상태가 올 수 있습니다. )
마) 기타
뭐 백업 같은 건 다들 하는 거고.. 실무에서 TRANSACTION 로그로 복구하는 건 거의 없습니다. 그냥 데이터 cash를 별도로 적재하고 손실된 데이터는 cash로부터 복구하는게 더 빠르고 쉽습니다. 당연히 이 cash를 생성하는 모듈을 따로 만들어둬야 하겠죠? 장애 대비에서 이런 복구 전략은 매우 중요합니다.
사전에 준비해야 상황이 닥쳤을 때 대응이 되는 건 비단 전쟁만은 아닌거죠.
AWS RDS는 크게 신경 안써도 되지만 DB를 주기적으로 관리해야할 필요가 있습니다. 특히 용량이라던가, 테이블 크기라던가 등등.. 쿼리도 돌리다 보면 처음에는 문제 없다가 갑자기 쿼리 플랜이 변경되는 경우도 흔합니다.
( 대부분의 현대 RDBMS는 최적화 도구 - Optimizer -를 가지고 있습니다. ) 그래서 주기적인 체크가 필요하죠
당연히 혼자서 이런 거 다 못합니다. 그러니까 이걸 업무상으로 처리하는 몇 가지 방안들이 있고 이것은 각 조직에서 현실에 맞게 적용해야할 필요가 있는 거죠.
2. Application 개발에서..
가. sample code란 무엇일까?
이 질문은 굉장히 철학적인 것입니다. 대개, 흔히 초보 개발자들을 포함한 비개발 부서가 코드 짜면 이 부분에 대한 고민이 없이 작업을 하고는 합니다.
구체적인 사례를 들어 봅시다. 여러분은 python으로 SQL SERVER DB에 접속하여 sportsdb라는 DB를 SELECT하고 INSERT / UPDATE하는 프로그램을 짜야 합니다. 이 경우 사용할 수 있는 라이브러리는 대체로 pmyssql 이나 SqlAlchemy 정도입니다. 자 그럼 구글에서 SqlAlchemy MSSQL Connect 로 검색을 해봅시다.
쉽게 찾아집니다. 대체로 하는 행동인 가장 위에 링크를 찾아 보지요
https://excelsior-cjh.tistory.com/77

방문해서 봅시다 그러면 접속 방법에 대해서 SQLAlchemy document까지 소개하면서 보여주고 있습니다.
https://docs.sqlalchemy.org/en/20/core/engines.html
하여 코드는 아래와 같습니다.
from sqlalchemy import create_engine
engine = create_engine('mssql+pymssql://username:passwd@host/database', echo=True)
훌륭합니다. 이제 이 구문을 python 스크립트에 적절하게 붙이기만 하면 DB는 접속이 되는 겁니다.
그리고 심지어는 세션에 대해서도 잘 설명해 주고 있습니다.
from sqlalchemy.orm import sessionmaker
# session 생성
Session = sessionmaker(bind=engine)
session = Session()
도큐먼트 문서에는 이렇게 접속 정보를 잘 기재를 해주고 있습니다.
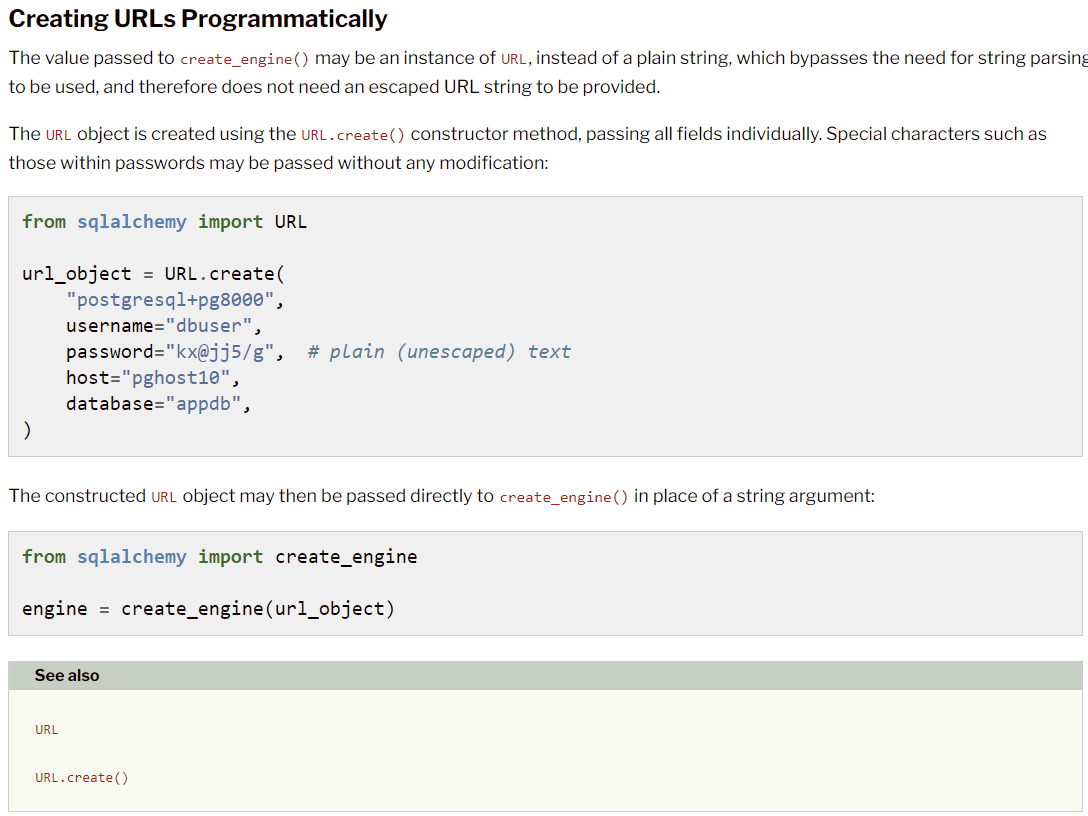
이제 적절하게 DB에 맞추어서(도큐먼트에 다 있습니다.) 선언만 바꿔주면 "개발자 따위"가 하는 SQL SERVER의 DB에 접속이 가능합니다. 그리고 많은 교육 자료와 블로거들이 어렵지 않다 이렇게만 하면 된다고 격려해 줍니다.
그런데 이것만으로는 업무에 적용을 할 수가 없습니다. 즉 위의 sample code는 "SQL SERVER에 SQLAlchemy 라이브러리를 이용하여 접속하는 방법"에 대한 Sample code이지 우리가 해야 하는 업무( sportsdb라는 DB를 SELECT하고 INSERT / UPDATE하는 프로그램를 작성하는 것)에 대한 sample code가 아니기 때문입니다.
이것은 업무에 대한 인식에 대한 차이이며 개발자가 아닌 사람들이 코드만 짤 때 가장 심각하게 저지르는 오류입니다.
우리에게 필요한 샘플 코드는 우리의 업무에 필요한 기능을 포함하는 것이여야 합니다. 단순하게 기능 1개를 구현하는 것이 아니라 말이죠 .
나. 업무를 통하여 기능을 정리하기
"SQL SERVER의 sportsdb라는 DB를 SELECT하고 INSERT / UPDATE하는 프로그램를 작성하는 것"에 대한 기능을 정리해 봅니다.
| 이 프로그램은 아래의 기능을 만족해야 한다. 1. DB에 접속할 수 있어야 한다. 2. python으로 공개된 오픈소스 라이브러리를 이용하여 SQL SERVER 접속해야 한다. 3. SELECT / INSERT / UPDATE 가 가능하다 4. DB 오류가 발생하였을 때 어느 쿼리에서 어떤 데이터를 처리하다가 오류가 발생하는지 확인이 가능하다. 5. 1개의 프로그램은 최대 50개의 쿼리를 동시 처리가 가능하다 6. 상호 연동된 테이블 간에( 예를 들면 1부터 50까지의 숫자를 저장할 때 1부터 10까지는 A테이블에 20부터 50까지는 B테이블에 저장하는 관계가 존재할 떄) 연관 관계가 있으면 반드시 원자성(Atomicity)를 확실하게 보장해야 한다 7. 접근 가능한 테이블은 총 26개이며, 중간에 실패가 발생해도 이 프로그램은 나머지 작업을 모두 작업을 진행해야 한다. 8. 1회 동작하고 종료하는 것이 아니라 특정 조건을 만족할 때까지 26개의 테이블의 변경 내용을 모두 적용해야 한다. |
1~3번은 대체로 기획팀 / 사업팀에서 전달해주는 내용입니다. 예 그냥 저렇게만 와요.
나머지 4번 이하의 내용들은 개발자라면 당연히 고려해야 하는 내용들이고 4~8까지를 도출하는 과정에서 유관부서를 모두 확인해서 유관 부서와 협의를 통해 정리해야 하는 내용들입니다. ( 세상에 당연한건 없습니다. 그래야만 하는 이유가 존재하는 거죠)
이런 내용들을 정리하라고 PM / PL 있는 겁니다. 그런데 개발을 전문으로 배우지 않은 사람들은 잘 모를 수도 있죠. 그런데 자기가 개발을 하고 있다면 자기 일이니 챙겨야죠.
자 위의 1~8을 좀 더 개발스럽게 도출해 봅시다.
0. config 파일로부터 DB정보를 수집
1. pytho / pmssql + SQLAlchemy 조합으로 DB 제어 구축
2. SQLAlchemy에서 engine 생성 시 session 정보는 아래처럼 관리
- 생성 시 숫자 : 50개
- 세션 생성 최대 수치 : 1000개
- 세션 timeout 시간 : 10초
- 세션 초기화 시간 : 5분
3. 원자성 보증을 위해서 transaction 구현 필요
4. SQLAlchemy logging 구현
5. python으로 데몬 생성
- sportsdb.basketball.game_status.isEnd = true 이면 데몬 종료 ( => sprotsdb 아래 basketball schema에 game_statue DB 테이블에 isEnd 컬럼의 값이 true 이면 데몬 종료 )
6. 각 구간에 대하여 exception 처리
7. 언어 코드는 UTF-8로 통일
자 이제 기능 정의가 대충 되었습니다. 업무에 대한 sample code를 작성해 봅니다.
다. 업무에 대한 sample code 작성
우선 우리는 정보를 별도의 config에서 수집해야 합니다. 대다수의 실무에서 코드 자체에 DB의 접속 정보를 박아 넣는 경우는 거의 없습니다. python은 컴파일 언어가 아니기 때문에 빌드를 다시 해야 할 필요는 없지만, 그래도 config를 유지하는 것이 기본적인 방법이라고 할 수 있죠.
| # -*- coding: utf-8 -*- import configparser from dataclasses import dataclass, field from typing import Optional import sqlalchemy from sqlalchemy.orm import sessionmaker @dataclass class ConfigDBInfo: config: dict = field( init=False ) config_file: str sports_engine: Optional[sqlalchemy.engine.base.Engine] = None sports_session: Optional[sqlalchemy.orm.session.Session] = None sports_session_factory: Optional[sessionmaker] = None def __post_init__(self): self.config = self.load_db_config( ) self.sports_engine = sqlalchemy.create_engine( f"mssql+pymssql://{self.config.get('db_id', 'config_db_err')}:" f"{self.config.get('db_pw')}@{self.config.get('db_host')}:{int(self.config.get('db_port'))}/sportsdb" , pool_size=300 , max_overflow=1000 , pool_timeout=10 , pool_recycle=30 , connect_args={'charset': 'UFT-8'} ) self.sports_session_factory = sessionmaker(bind=self.sports_engine) def load_db_config( self): config = {} try: parser = configparser.ConfigParser() parser.read( self.config_file ) config = { 'db_id':parser.get('db', 'db_id'), 'db_pw':parser.get('db', 'db_pw'), 'db_host':parser.get('db', 'db_host'), 'db_port':parser.get('db', 'db_port') } except Exception as e: print(f"############################################################") print(f"# config file {self.config_file} read fail In ConfigDBInfo {e}") return config |
DB connect를 하기 위한 python sample code
위의 ConfigDBInfo 는 그 자체로 선언하여 사용할 수도 있지만 기본적인 connect 기능과 필요한 설정을 가지고 있습니다.
config 파일을 적절하게 세팅하면 load_db_config 함수에서 이 class가 호출될 때 자동으로 DB 정보가 세팅됩니다.
config 파일은 서버에 별도로 존재하고, 해당 파일을 git 등에 공유하지 않으면 DB 정보가 외부로 유출될 일도 없죠. 중요한 점은 구현 코드와 설정을 완전히 분리함으로서 공유를 필수적으로 해야 하는 구현 코드만 확인하고는 접속 정보를 휙득할 수 없다는 점이고, 이 점은 보안과 안전성을 좀 더 높여 줍니다.
개발업무에 종사하는 비 개발자들의 한계를 맞이하는 부분이 이건데.. 이걸 왜 해야 하느냐고 화를 내는 거죠. 그런데 해야 합니다. 보안 사고는 대채로 비 개발자들이 불편하다, 쓸데없이 복잡하다고 화를 내는 부분에서 비롯되는게 보통이니까요.
SQLAlchemy에서 engine 생성 시 session 정보관리는 아래 구문에서 처리합니다.
, pool_size=300
, max_overflow=1000
, pool_timeout=10
, pool_recycle=300
선언 시 설정으로 처리되는 부분이죠
원자성을 보증을 위해서는 transaction 처리가 필요합니다.
이 부분은 아래와 같은 형태로 sample code를 작성할 수 있겠습니다.
| config = ConfigDBInfo( "config.ini") // 선언 및 DB 접속 connect = config.sports_engine.connect() trans = connect.begin() try : query: str = " UPDATE A ...... " connect.execute(text ( query )) query: str = " UPDATE B...... " connect.execute(text ( query )) trans.commit() except Exception as err2 : trans.rollback() finally: connect.close() |
예 transaction을 설정하고 성공하면 commit 실패하면 전체를 rollback 하여 명시적으로 원자성이 보증되게 합니다.
생성한 세션은 오류 여부와 관계 없이 명시적으로 close 처리하여 닫아 버리죠. 빈번한 세션의 open / close가 발생할 수도 있지만 라이브러리에서는 세션풀을 별도로 생성하니 크게 관계는 없습니다.
이제 개발할 때 원자성이 필요한 부분은 위의 코드를 적절하게 변경하여 사용할 수 있죠. 실제 쿼리가 적용되는 try 영역 안에서 처리를 넣으면 됩니다.
이제 기본적인 DB 에 관련된 코드들이 있으니 로깅이 필요합니다.
| # -*- coding: utf-8 -*- import logging import os import configparser from logging.handlers import TimedRotatingFileHandler from dataclasses import dataclass, field @dataclass class ConfigLogInfo: config_file: str config: dict = field( init=False ) logger: logging.Logger = field( init=False ) dblogger: logging.Logger = field( init=False ) def __post_init__(self): self.config = self.load_logging_config() def load_logging_config( self): config = { } try: parser = configparser.ConfigParser() parser.read( self.config_file) config = { 'log_file': parser.get('logging', 'log_file'), 'level': getattr(logging, parser.get('logging', 'level')), 'backup_count': parser.getint('logging', 'backup_count'), 'sqlalchemy_log_file': parser.get('logging', 'sqlalchemy_log_file'), 'sqlalchemy_level': getattr(logging, parser.get('logging', 'sqlalchemy_level')) } print(f"############################################################") print(f"# config file {self.config_file} read success\n\n\n") except Exception as e: print(f"############################################################") print(f"# config file {self.config_file} read fail In ConfigLogInfo {e}") return config def setup_sqlalchemy_logger( self, config ): # SQLAlchemy 로거 설정 logger = logging.getLogger('sqlalchemy.engine') logger.setLevel(config['sqlalchemy_level']) # 파일 핸들러 설정 handler = TimedRotatingFileHandler(config['sqlalchemy_log_file'] , when="midnight" , interval=1 , backupCount=config['backup_count'] , encoding='utf-8' ) handler.suffix = "%Y-%m-%d" formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') handler.setFormatter(formatter) logger.addHandler(handler) return logger |
교육 과정에서는 logging 에 대해서 별도로 가르칠 시간이 없다보니까 그냥 로깅을 print 문으로 대체하는 경우가 많은데, 전문적인 로깅 프레임워크를 써야 합니다. 니가 짠 프로그램이 언제나 100% 완벽하게 대응된다는 보장은 없어요. 그러니까 뭐가 문제가 생기면 잘 안되면 원인을 찾아야 하는데 코드 보면서 머릿속으로 열씸히 사고를 하지 말고 로그를 넣어서 어느 구간에서 에러가 발생하는지 체크를 해야 합니다.
아래는 logging 프레임워크로 처리한 로그의 일부입니다.
| 2023-12-21 10:30:10,598 - sqlalchemy.engine.Engine - INFO - select @@version 2023-12-21 10:30:10,599 - sqlalchemy.engine.Engine - INFO - [raw sql] {} 2023-12-21 10:30:10,603 - sqlalchemy.engine.Engine - INFO - SELECT schema_name() 2023-12-21 10:30:10,603 - sqlalchemy.engine.Engine - INFO - [generated in 0.00016s] {} 2023-12-21 10:30:10,622 - sqlalchemy.engine.Engine - INFO - SELECT CAST('test max support' AS NVARCHAR(max)) 2023-12-21 10:30:10,622 - sqlalchemy.engine.Engine - INFO - [generated in 0.00016s] {} 2023-12-21 10:30:10,629 - sqlalchemy.engine.Engine - INFO - SELECT 1 FROM fn_listextendedproperty(default, default, default, default, default, default, default) 2023-12-21 10:30:10,629 - sqlalchemy.engine.Engine - INFO - [generated in 0.00012s] {} 2023-12-21 10:30:10,646 - sqlalchemy.engine.Engine - INFO - BEGIN (implicit) 2023-12-21 10:30:10,646 - sqlalchemy.engine.Engine - INFO - SELECT [INFORMATION_SCHEMA].[TABLES].[TABLE_NAME] FROM [INFORMATION_SCHEMA].[TABLES] WHERE ([INFORMATION_SCHEMA].[TABLES].[TABLE_TYPE] = CAST(%(table_type_1)s AS NVARCHAR(max)) OR [INFORMATION_SCHEMA].[TABLES].[TABLE_TYPE] = CAST(%(table_type_2)s AS NVARCHAR(max))) A ND [INFORMATION_SCHEMA].[TABLES].[TABLE_NAME] = CAST(%(table_name_1)s AS NVARCHAR(max)) AND [INFORMATION_SCHEMA].[TABLES].[TABLE_SCHEMA] = CAST(%(table_schema_1)s AS NVARCHAR(max)) 2023-12-21 10:30:10,646 - sqlalchemy.engine.Engine - INFO - [generated in 0.00028s] {'table_type_1': 'BASE TABLE', 'table_type_2': 'VIEW', 'table_name_1': "SELECT * FROM dbo.team_sch edule WHERE season_code=43 AND game_code IN ('01', '03', '04', '10', '11', '13')", 'table_schema_1': 'dbo'} 2023-12-21 10:30:10,650 - sqlalchemy.engine.Engine - INFO - SELECT * FROM dbo.team_schedule WHERE season_code=43 AND game_code IN ('01', '03', '04', '10', '11', '13') 2023-12-21 10:30:10,650 - sqlalchemy.engine.Engine - INFO - [raw sql] {} 2023-12-21 10:30:10,662 - sqlalchemy.engine.Engine - INFO - ROLLBACK |
내용을 보면 실제 쿼리를 실행한 데이터와 처리된 시간에 실제 쿼리까지 전부 로깅이 됩니다. 이걸 전부다 일일히 print 해서 출력? 어렵습니다.
시스템 에러도 비슷해서 실제로 프로세스 내부에서 print 로만 처리하는 건 한계가 있습니다. 이런 것을 잘 출력할 수 있게 만든게 로깅 프레임워크고, 대체로 오픈소스 프레임워크 좋은것이 많으니까 로깅을 별도로 설정하고 구축하는 겁니다.
그럼 위에 원자성 보증 샘플 코드에 log를 추가해 봅시다.
| try: config = ConfigDBInfo( "config.ini") pass except Exception as e: logger.error(f" [Error] DB connect failed: {e}") return connect = config.sports_engine.connect() trans = connect.begin() try : query: str = " UPDATE A ...... " connect.execute(text ( query )) query: str = " UPDATE B...... " connect.execute(text ( query )) trans.commit() logger.info(f'table A / B 동기화 성공--') except Exception as err2 : logger.error(f'[Error] {err2}') trans.rollback() finally: connect.close() |
고작 몇 줄이 추가되었을 뿐이지만, 당신이 만든 프로그램에서 뭔가 문제가 생기면 그게 뭔지는 모르지만 뭐 때문에 안되는지 명료하게 보여줍니다. 최소한 위 비즈니스 로직에서 문제가 생기면 [Error]는 확실하게 생깁니다.
이제 데몬을 생성하는 샘플 코드를 만들어 봅시다. 샘플이니 복잡하지 않고 예외도 그렇게 꼼꼼하게 처리를 안합니다.
| # -*- coding: utf-8 -*- import argparse import multiprocessing import daemon import time import config_info import config_log from sqlalchemy import text from datetime import datetime, timedelta def run_process(target_function, logger, dblogger, config_info): target_function(logger, dblogger, config_info) def do_kbl_live_check(logger, dblogger, config_info): while True: try: // 비즈니스 로직 추가 - sportsdb.basketball.game_status.isEnd = true 이면 데몬 종료 pass except Exception as e: dblogger.error(f"do_kbl_live_check process failed: {e}") break time.sleep(60) if __name__ == "__main__": config_info = config_info.ConfigInfo() log_info = config_log.ConfigLogInfo(config_info.config_path + config_info.config_file) with open(log_info.config['log_file'], 'a+') as log_file: with daemon.DaemonContext(stdout=log_file, stderr=log_file): dblogger = log_info.setup_sqlalchemy_logger(log_info.config) dblogger.info("SQLAlchemy logger is configured.") processes = [] kbl_process = multiprocessing.Process(target=run_process, args=(do_kbl_live_check, logger, dblogger, config_info)) processes.append(kbl_process) # 시작된 모든 프로세스에 대해 시작 및 조인 for process in processes: process.start() for process in processes: process.join() |
import daemon 을 위해서는 별도의 라이브러리가 설치가 요구됩니다. 이건 나중에 페이퍼 워킹으로 정리를 해놔야 겠죠. 이제 데몬이 만들어지고 조건을 만족하면 작동을 중지합니다.
배열형으로 만든 것은 sample code에 필요한 함수를 추가해서 이 프로그램에서 기능을 추가할 때 관리하기 편하게 만들어 둔 겁니다.
모든 코드에는 # -*- coding: utf-8 -*- 를 넣어야 uft-8이 유지될 것이고, 남은 것은 비즈니스 로직을 추가할 때마다 try - except를 구현해서 logging을 제대로 해서 원인을 알 수 있게 하되 except 가 발생해도 계속 프로그램이 진행 되도록 하는 거죠. ( 대부분의 로직은 do_kbl_live_check 에서 발생하게 됩니다. )
자 이제 업무상 샘플코드 만드는 작업이 종료되었습니다. 이제 우리가 받은 기능정의는 우리가 구현한 샘플 코드 내부에서 어레인지 하는 정도로 대부분의 업무를 처리할 수는 있습니다. 남은 것은 실제 남은 26개 테이블에 대한 SELECT / INSERT / UPDATE 쿼리를 하나하나 만들어서 동작시키는 작업이죠.
3. 누가 하는 것인가?
가. 조직에 꼰대들만 있어서 제대로 일을 못하게 한다구요?
개발은 다른 일과 다르게 당신이 코드를 짜는 겁니다. 저런 기본적인 처리가 안되어 있다면 대체로 하지 말아야 하는 명료한 원인이 있는게 아니라 누군가는 해야 하는데 그냥 안하는 거죠.
선택은 3가지 정도가 있겠네요. 그냥 게으른 사람이 되던가, 아니면 절이 싫으니 IT 쪽 개발 말고 다를 일을 찾던가, 아니면 대신 해줄 사람을 찾으면 됩니다. 대체로 전 2번을 추천하긴 합니다. 뒷담화나 하면서 본인은 무죄인척 하지 말구요.. 사실 저런 기본적인 코드 처리가 어려운 것도 아니고, 그냥 짜서 올리면 쓰고 안쓰고의 문제지 잘 작동하는 이상 남이 그 코드를 굳이 쓰지 말라고 할 이유도 없습니다. 저렇게 일을 하게 해달라는 건 넌센스에요.
야근이건 주말 근무건 당신이 시간을 투자해서 하면 되는 일입니다. 어려운 것도 아니고 코드를 많이 짜야 할 필요도 없어요(제대로 구축을 하면 코드 짜는 양은 오히려 줄어들게 되어 있습니다. ) 근데 안한다? 안시켜준다? 그리고 불평불만?
기본적인 것들을 못하게 한다고 투덜댈 거면 그냥 다른 일을 하시면 됩니다. IT가 당신의 적성과는 안 맞는 겁니다. 전 프로그래밍이 한 번도 재능이 필요하다고 생각해본 적은 없어요. 저 같이 평범한 머리 나쁜 사람도 할 거 다 합니다. 그런데 이런 문제들에 봉착했을 때 투덜이 스머프가 되어서 꼰대 타령이나 하는 사람은 이 일을 하면 안되고 오래 못합니다. ( 하면 사고치죠.. 똥 코드를 만들어서 투척하고..)
다시 한 번 이야기 하지만 위에 실무 레벨은 엄청 대단한게 아니라 어디서든 하는 거고, 비 개발자들은 일을 모르니까 안하거나 게을러서 안하는 겁니다. 진짜 꼰대면 저걸 하지 말라고 하는게 아니라 안되어 있는 걸 다 묶어서 당신에게 해야할 일을 짬처리 해서 하라고 시키는 사람이겠죠..
결론. 프로그래밍은 당신이 하는 겁니다.
당신이 모든 일을 다 할 필요는 없어요. 하지만 당신이 짠 산출물은 당신이 한거죠. 주변 환경이고 뭐고 당신이 스스로를 개발자라고 생각을 하던 말던 당신이 IT 업무 부서에서 개발을 했다면 말이죠.
근본적으로 IT업무 자체가 기본적으로 독립성을 깔고 갑니다. 그래 당신이 짠 코드리뷰 하는 조직이 얼마나 있을까요? 대체로 기능 요구 내고 테스트 케이스 통과하면 적용 가는 겁니다. 현실적으로 그래요.
그런데 똥코드 투척하고 제대로 갖춰진게 없어서 코드를 못짠다? 그거 언제하느냐? 그냥 당신은 다른 일을 하는게 나은 겁니다. 적어도 코드를 짜는 그 순간은 당신은 자유롭게 일하는 거에요. 그리고 제대로 검증을 통과하면 그냥 적용 할 수 밖에 없어요. 대체로 나중에 문제가 생겨서 당신이 책임지게 되는 것이고....
나는 개발자가 아니라고 항변해도 소용 없어요. 그럼 개발을 아예 마셔야죠. 그래 요리 못하는데 요리 시켜서 억지로(?) 해서 그 요리 먹고 사람이 죽어 나가면 당신은 책임이 1도 없는 건가요? 누가 시킨다고 의사 면허증도 없이 진료보고 처방한 다음에 사람 죽으면 당신 책임은 없는 건가요?
비개발자들이 뭐든 배워서 개발을 할 때 아예 뭘 몰라서 시키는 대로나 할려고 하면 차라리 나아요. 문제는 나름 경력 먹었다고 또는 나름 개발 커뮤니티에서 좀 친다고 잘난척 하면서 저런 기본적인 내용들을 안 챙기는 사람들이 문제죠..
댓글
댓글 리스트-
답댓글 작성자구경하는사람24 작성시간 23.12.22 델카이저 답변 감사합니다.
-
작성자▦무장공비 작성시간 23.12.21 허허
또 공돌이는 공돌인데 하는 일 자체는 IT는 결이 다르군요.
나도 이런거 쓰면 도움이 될만한 사람이 있으려나...? -
답댓글 작성자델카이저 작성자 본인 여부 작성자 작성시간 23.12.22 뭐 있겠죠..ㅋㅋㅋㅋㅋㅋ 사실 MZ들이 배워야 하는 건 스킬이 아니라 일인데 애들이 스킬과 일을 구분을 못해서..
-
작성자judas 작성시간 23.12.22 협업을 못해요..협업을..
자기꺼 돌아가면 땡인거죠.. 옆은 생각을 안해요..
인터페이스가 중요도가 높고 인터페이스 잘하는게 고수인데... 그런거 다 체크하라고 하면 절차 그지같다고 바로 불만 나오죠...ㅋ -
작성자ilmonde 작성시간 23.12.23 보안운영 업무 맡고 있고 촉탁이다 보니 프로젝트만 자꾸 넘겨받는데 개발자 여럿 겪어보면 가),나),다),라) 이해하고 있는 사람이 정말 없죠. 결국 개발자라고 코드 짜는 것만 알고 다른 경험이 없어서 그런건데 대화를 해도 애초에 이해를 못하니 PM 역할이 정말 중요합니다만 우리나라에서 PM이란 존재는 ㅋㅋ
중소기업은 중소기업대로 대기업은 대기업대로 실무업무를 아는 개발자란 존재가 너무나도 귀합니다.