
안녕하세요 이번 유니코드 부분관련을 발표하게 된 유시혁 입니다.

이 그림은 다양한 문자로 쓰여져 있습니다. 영어에서부터 한글까지 많은 문자들이 혼재해 있습니다. 이 문자들을 한 화면에 출력하는 일은 생각보다 쉽지 않은 일입니다. 여러 나라의 사람들이 한번에 모여 있을 때 서로 언어 전달이 힘든 것처럼 컴퓨터로 다양한 언어를 출력하는 것은 난해한 일입니다. 이런 문제를 해결하는 방법 중 하나가 UNICODE 입니다.

차례는 문자 코드, 유니코드, 매크로, 한글 코드 변환, 실습 순서로 진행 하겠습니다.

우선 문자 코드입니다. 문자코드에는 SBCS, DBCS, WBCS .

SBCS는 영미권 국가, 즉 영어권 국가에서 쓰이는 지역적
문자집합 입니다. 1바이트로 이루어 졌지만, 알파벳의 변형이 있는 독일어나 불어, 그리고 알파벳과 모양이 완전히 다른 그리스어, 러시아어는 전혀 표시 할 수 없습니다.
그리고 7비트 아스키 코드로 인 코딩 되었습니다. 여기서 아스키 코드를 설명하기 전에 ANSI에 대해 알아 봅시다.

ANSI란 미국 내에서 기술표준 개발을 육성하기 위해 설립된 제1차 기관으로 산업계에 소속된 기술자 그룹들과 함께 일하며, 세계표준화기구인
ISO(International Organization for Standardization) 및 세계전자기술위원회인 IEC(International Electro-technical Commission)의 일원입니다. ANSI가 제정한 컴퓨터에 관한 표준 중 대표적인 것으로는 아스키가 있습니다.

ASCII 코드는 American Standard Code for Information Interchange 미국 정보 표준 부호의 약자 이다. 영문 알파벳을 사용하는 대표적인 문자 인 코딩으로써 컴퓨터와 통신장비를 비롯한 문자를 사용하는 많은 장치에서 사용되었습니다. 문제점은 앞에서 봤듯이 2바이트 문자를 사용하는 문화권에서는 사용이 불가능 하다는 점입니다.

다음은 DBCS 이다. CJK 국가에서는 문자(중국은 한자, 일본의 한자와 가나 문자, 한국의 초, 중, 종성을 조합한 문자체계)의 수가 엄청나게 많기
때문에 1바이트 담고자 한 내용을 모두 담을 수 없으며
그래서 나온 방법이 DBCS 입니다.
현재 우리가 사용하고 있는 DBCS는 영문, 기호는 8비트로 표현 한글은
16비트로 표현하는 ANSI의 확장 형 문자 코드입니다.
SBCS와 DBCS가 섞여서 존재하며 때로는 16bit를 넘을 수도 있기 때문에 MBCS(Multi Byte Character Set) 이라고도 합니다. 하지만 MBCS는 코드페이지를 통해 해석되기 때문에 코드페이지가 바뀌게 되면 글이 깨질 수가 있습니다.

다음은 WBCS 입니다. WBCS는 모든 문자를 2바이트로 처리하는 문자로써 유니코드가 이에 해당 합니다. 자세한 사항은 다음장에서 설명 하겠습니다.


유니코드는 각각의 다른 나라의 언어를 시스템의 호환성 및 확장성에 문제를 일으키는 관계로 이를 하나의 문자인 유니코드로 통합시키는 방법입니다. 종류는 UTF8, UTF16, UTF32등이 있습니다. UTF는 (Universal character set Transformation Format )의 약자로써 16비트 유니코드 문자를 7비트 또는 8비트 문자로 변환하기 위한 방법입니다.

UTF-8과 UTF-16은 모두 MBCS에 속해 있는 문자집합 입니다. UTF-8은 ASCII 코드와의 호환성을 목표로 개발된 문자집합으로, ASCII 코드의 영역은 그대로 내포하고 있으며 그 외의 영역을 표시로 해서 ASCII 외의 영역을 사용하는 방법 입니다.

UTF 16은 문자를 2~4 바이트의 가변적인 방법으로 표현합니다.
그리고 아스키 코드 영역 또한 2바이트로 표현하지만 비 아스키 코드 영역도 대부분 2바이트로 표현 합니다. 예를 들어 한글은 유니코드에서 첫 2바이트 영역에 속해 있기에 2바이트로 표현됩니다.

우리는 문자집합을 어느 하나로 정해서 프로그래밍을 한다고 할 경우 현존하는 모든 시스템에서 완벽히 유니코드를 지원하지 않을 경우에는 어떻게 할것인가 라는 문제가 있습니다. 이것을 해결하기 위한 매크로가 있습니다. UNICODE는 API 함수의 유니코드이며 _UNICODE는 C함수의 유니코드입니다.

Windows.h 에서는 MBCS와 WBCS를 동시에 수용하는 형태의 프로그램을 구현하기 위해서 이와 같은 형태의 매크로를 정의 하고 있습니다. 이 매크로가 사용되는 예는 다음과 같습니다.
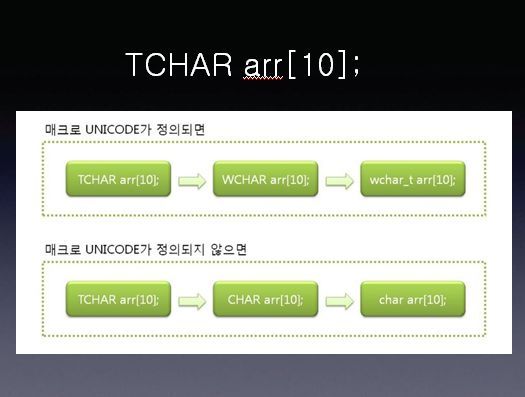
TCHAR arr[10]; 을 선언 했을때, 매크로 UNICODE가 정의되어 있다면 TCHAR arr[10];은 MBCS기반으로 정의되어 있지않다면 WBCS 기반의 문자열로 바뀌게 됩니다.

다음은 _UNICODE로써 C컴파일에서의 유니코드로 tchar.h 일부를 간략화 한것입니다.
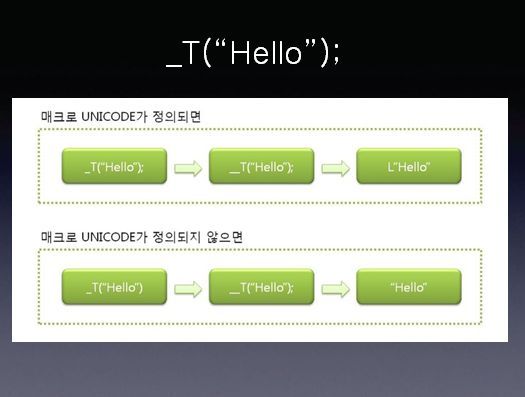
_T(“Hello”); 를 입력하면 (#define _T(x) __T(x) ) 에 의해 __T(“Hello”);
매크로 _UNICODE가 정의되었다면 L이 붙을 것이고 __T(“Hello”); -> L “Hello” 정의되어 있지 않다면 그대로 __T(“Hello”); -> “Hello” 될 것입니다.

컴퓨터는 서로 각기 다른 비트로 코드를 저장하고 있습니다. 때문에 통신상에 에러가 발생할 수도 있는데요, CODE convert 를 이용한 해결방법이 있습니다.
WideCharToMultiByte WideChar 문자를 MultiByte로 바꾸는 것과
그 반대인 MultiByteToWideChar가 있습니다.
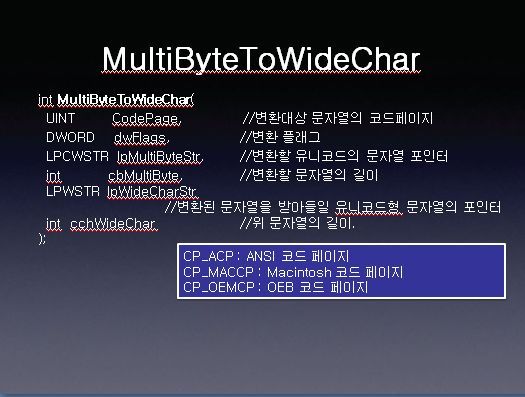
첫번째 변수의 파라미터에는 3가지가 존재합니다. 대부분 ANSI코드 페이지를 변환하는 CP_ACP를 많이 쓰게 될

다음은 반대로 멀티 바이트 문자를 WideChar 형으로 변환하는 방법입니다.
WideCharToMultiByte 와 다른점은 두가지의 인수가 더 포함된다는 점입니다. lpDefalitChar 는 변환할 수없는 문자를 대신 사용할 문자를 지정하며, lpUsedDefaultChar 인수는 디폴트 변환된 문자가 있었는지의 여부를 돌려 받기 위한 출력용 함수이다. 디폴트 변환을 별도로 지정하지 않을 경우 두 인수를 모두 NULL 로 지정할 수 있는데, 이렇게 되면 시스템의 디폴트 값이 사용됩니다.
-나머지 예제 사항은 기술문서에 넣겠습니다.-
이상 발표를 마치겠습니다.