|
1. 트랜젝션(Transaction)의 이해 | |||||
|
트랜젝션에 대한 이야기 입니다. ^_^ 트랜젝션에 대한 이야기는 많은 곳에서.. 이런 저런 이유로 들어 보셨을 겁니다. 프로그래밍을 하실때도 이 트랜젝션은 분명히 대단히 속도에 영향을 주는 요소 입니다. 특히나 데이터 수정이 있을 경우인 Insert, Update, Delete를 잘못 수행했을 경우 대단히 많은 문제를 줄 수 있으며.. - CPU등의 시스템은 펑펑 놀고 있는데.. SELECT의 조회 속도가 대단히 느려지는 사태가 발생하는 겁니다. 이럴때는 한번쯤 트랜젝션 처리 모듈의 문제를 어플리케이션에서 점검을 해 보셔야 하지요. - 물론 마지막쯔~음에.. 문제상황인 블러킹이나 데드락을 막는 방법과.. 어플리케이션을 개발하실때.. 주의에 주의를 거듭하셔야 하는 부분도 살짝 언급을 해 드릴겁니다.
이 장의 이름은 트랜젝션과 잠금처리인데요.. 트랜젝션은 뭘까요? ^_^ 늘 그랬던 것처럼.. 군더더기 없이 깔끔하게 알아 보도록 하지요.
트랜젝션은 작업의 단위를 지정해 주는 중요한 부분이기 때문입니다.
또한 트랜젝션은 SQL구문이나 쿼리를 실제로 처리할 경우의 가장 작은 단위 입니다.!! 은행이야기를 조금 해 볼까요? 코난이 계좌에 200원이 있고.... 수선이 계좌에 300원이 있다... 짤짤이에서 진 코난이가 100원을 수선이에게 잃어 200원중 100원을 온라인으로 계좌이체 를 시켜줘야 한다.... 은행에사거 온라인으로 입금을 하기위해
하려고 했다... 그런데 웬일.. 정전이 나서... 1번 작업을 끝마치니 시스템이 죽었다... "대우네 은행"에서 그당시 온라인으로 계좌 이체를 시킨 사람이 1000명이었다... 그 999명과 코난이는(도합 1000명) 이 문제를 어케할 것인가? -_-;; 아마 기억하시는분들은.. MSSQL7 중급강좌의 트랜젝션 부분을 역시나.. 손가락 두개로 컷 & 페이스트 한걸 아실 겁니다. -_-;; 양해하시고.. 저런 문제가 발생할 수 있지요.. !!!
저 내용을 우리가 사용하는 구문으로 살짝 돌려 본다면 이런 이야기가 될지 모릅니다.
하지만 위의 쿼리가 아닙니다!!!!! SQL서버에서 위와 같은 처리를 위해서는 위처럼 쓰시면 안됩니다. 위와 같은 구문으로 쓰시면? 위의 쿼리는 다음과 같이 변환 됩니다.
이렇게 변화하게 됩니다. - 내부적으로 SQL서버의 엔진이 저렇게 바꾸는 겁니다. 그렇다면!!! 어떻게 해야.. 하나의 단위로.. 위 두개의 작업을 하나로 묶어서 수행하게 할 수 있을까요? 바로 다음과 같이 명시적으로 begin tran과 commit tran을 사용하시면 됩니다.
이렇게 사용하시면 두개의 작업이 하나의 단위로 처리가 되게 되지요. 별로 어렵지 않으실 겁니다. 그리고 이정도는 컴쪽의 일을 하신다면 한번쯔음~~ 들어 보셨을 이야기일 거구요. 그럼 조금 다른 이야기로.. 내용을 돌려 보도록 하지요.
트랜젝션의 네가지 성격 트랜젝션은 DBMS차원에서.. 다음 네가지 성격을 만족해야만 합니다. 1. 원자성(atomicity) : 트랜젝션은 전부, 전무의 실행만이 있지.. 일부 실행으로 트랜젝션의 기능을 가질 수는 없다. 2. 일관성(consistency) : 트랜젝션이 그 실행을 성공적으로 완료하면 언제나 일관된 데이터베이스 상태로 된다라는 의미입니다.. 즉, 이 트랜젝션의 실행으로 일관성이 깨지지 않는다 라는 의미 이지요... 3. 격리성(isolation) : 연산의 중간결과에 다른 트랜젝션이나 작업이 접근할 수 없다.. 라는 의미입니다. 4. 영속성(durability) : 트랜젝션의 일단 그 실행을 성공적으로 끝내면 그 결과를 어떠한 경우에라도 보장받는다.. 라는 의미입니다....
그렇다면 도대체~~ 저 어려운 단어들의 나열이 트랜젝션의 성격이라는 것은 알겠는데.. 그 트랜젝션 이라는 녀석으로 과연 어떻게 문제가 생겼을때 데이터를 복구하냐?? 이때는 UNDO와 REDO의 이야기가 나오게 됩니다. 우선 많이들 이야기 하시는 이야기로 알아 보지요.
장애(failure)와 회복(recovery) 회복(recovery)이란 장애(failure)가 일어났을 때 데이터 베이스를 장애 이전의 상태로 다시 복구 시켜 일관된 상태로(consistent state)로 복구 시키는 작업이지요 당연하지요? -_-;; 장애를 조금더 알아본다면? 관리자가 구두로 컴퓨터 파워 버튼을 실수로 차버리거나. 해서 문제가 생기는 상황?? 이렇게 대충은 생각이 가능하실 겁니다. 조금만 더 세분화를 시켜 본다면..
이렇게 세분화가 가능해 집니다. 그렇다면 회복이라는 것은? 말 그대로 데이터를 안정된 상태로 복구 시키는 것을 의미하지요.
위에서 말씀드린. UNDO와 REDO를 이용하는 방법에 대해서는... 뒤에서 보실 체크포인트 프로세스와 함께 이루어지는 부분을 주로 이야기 드릴 겁니다. 조금만 더 기다려 주시구요. 그리고 이 강좌를 SQL7중급강좌에서는 이론적인 이야기를 주로 했었는데요.. 제가 쓰고나서도 재미 대단히 없더군요.. 천천히 재미나는 예제로 풀어 나갈테니.. 기대해 주시고.. 다음 강좌인 트렌젝션의 종류 부분을 보도록 하시지요. |
****************************************************************************
|
2. 트랜젝션의 종류 | ||||||||||||||||||||||
|
트랜젝션이라고 하는 많이 듣는 이야기.. SQL서버는 내부적으로 작업의 최소 단위인 이 트랜젝션을 세분화 해 두었습니다.
트랜젝션의 종류~~
이렇게 세가지 입니다. 각각의 트랜젝션에 대해서 소개를 해 드리자면? Autocommit : 자동적인 커밋
이런 작업을 자동으로 다음처럼 바꿉니다.
이렇게 변화시키고 수행되는 트랜젝션을 Autocommit 이라고 합니다. - SQL서버가 위처럼 바꾸는 것이지요.
Explicit 트랜젝션 을 이야기 하자면.. 바로 다음처럼 명시적으로 사용자가 트랜젝션을 정의하고 수행하는 것을 의미 합니다.
이런 식으로 사용자가 직접 정의하는 것을 의미 하지요.
끝으로 Implicit 트랜젝션 입니다. 이녀석은 약간 특이한 녀석으로.. 사용자 - 또는 관리자가 정의해 두어야 하며.. 한번 Implicit 이 활성화가 되면 모든 데이터 변경 작업후 반드시 Commit 문을 날려야만 데이터의 변경이 적용 됩니다. 가끔 들어오는 질문으로.. Q. DBMS관리자가 휴가중이라.. 잠시 SQL서버를 관리하는 중입니다.
라는 구문을 수행했으나.. 이상하게도 데이터가 변경되지 않습니다. 잠시후에 누군가 데이터를 바꿔 두는것인지 어떤지 알 수 없으나 잠시후 다른 사용자가 로긴해 봐 보면 가격이 다시 원상태로 돌아와 있습니다. 아마도 SQL서버의 버그인듯 합니다. 어떻게 해결해야 하나요? - 서비스팩을 설치하면 될까요?
물론 실화이며 종종 올라오는 질문 입니다. 이런 이유는 다음과 같은 설정이 되어 있기 때문입니다. 바로 Implicit transactions 설정이 on으로 되어 있기 때문입니다.
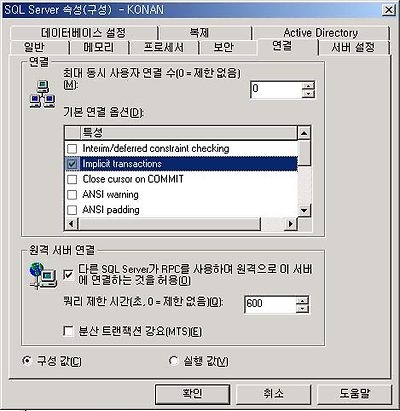
즉 위에서 보시는 바와 같이 set IMPLICIT_TRANSACTIONS on 옵션이 설정되어 있다는 것이며 위의 경우는 해당하는 커넥션 - 연결된 세션에만 설정한 것이고 이 설정을 서버측에서 구성할수도 있습니다. - 이건 관리자가 할 수 있지요.
이렇게 EM -> 서버 등록정보 부분의 연결 탭에서 연결되는 모든 사용자는 기본적으로 implicit transaction으로 연결하게 할 수 있으며..
sp_configure 옵션으로는..
해 보시면...user options 이라는 이름의 설정이 있는데요.. 이 값은.. 여러개의 설정이 이진수로 모여 있는 것입니다. 여기서.. 해당하는 구성값중에서 'user options 옵션' 으로 온라인 도움말을 보시면 상세한 정보를 보실 수 있으며.. 밸루값2가 IMPLICIT_TRANSACTIONS 설정입니다. 예를들어. 현재의 sp_configure의 구성값이 3이라면? DISABLE_DEF_CNST_CHK과 IMPLICIT_TRANSACTIONS이 설정되어 있다는 의미겠지요. - 기본적으로는 설정 안되어 있습니다. 뭐 각설하고... 결론적으로.. 저렇게 set implicit transaction이 걸려 있다면? 이렇게 하시면 됩니다.
어떻습니까? commit tran이라고 주어야만 데이터 변경이 일어 나지요. 이것은 실제 ANSI표준으로 implicit tran이 on이 되어야 표준이지만.. SQL서버는 기본적으로 OFF로 되어 있습니다. - 오라클은 ON이 기본설정 또한 어플리케이션에서 연결할때 ADO로 연결한다면? ADO의 기본 연결 속성으로 implicit transaction은 OFF이기 때문에.. 많은 분들이 저 옵션값을 모르고 계시지요. 참고하시구요. 그럼 언제 저 implicit transaction이 자동으로 begin tran을 시작하는가!! 입니다.
이러한 구문이 쿼리중에 나온다면? SQL서버는 자동으로 begin tran 구문을 넣는것과 같다라고 판단하며 반드시 commit tran을 해야만 수정이 반영되게 합니다.
그럼 저 복잡 짜증인 implicit transaction은 왜 쓰는것인가? 간단합니다. update titles set price = 0 또는 종종 올라오는 update 회원테이블 암호 = 'AAAA' 라고.. where절 없이 무의식중에 쳐버린다면? 말그대로 다이죠.. -_-;; 이런 상황을 막고자... 설정하는 것이며.. 쿼리 분석기로 데이터 수정작업등을 할 경우 안정성을 확보하기 위해 관리자가 서버측에 설정하는 케이스도 있습니다. - 위의 질문과 같은 케이스 이지요. 단순히 commit tran 이라고 적어만 주면 되며.. 일반 사용자의 쿼리를 직접 날려 발생하는 실수를 막고자 하는 것입니다.
다음은 분산 트랜젝션 입니다. 예를들어.. 시스템이 두개가 있을 경우 물리적으로 떨어져 있는 시스템에서 트랜젝셔널한 처리르 하고자 할 경우지요.
이렇게.. Distributed Transaction Coordinator가 활성화가 양쪽 서버에 되어 있어야 하며.. 물론 나중에 배우실 linked Server가 있으면 더욱 좋습니다. 트랜젝션의 시작은..
이렇게 BEGIN DISTRIBUTED TRANSACTION 으로 하시면 되구요. 나머지는 같다고 보시면 됩니다. 중요한 부분으로 DTC활성화가 잘 되어있는지를 항상 조사 하셔야 하며 적절한 권한으로 로긴한 후 객체를 핸들할 수 있는지 역시 잘 파악하셔야 합니다. - 대부분의 경우 이 두가지의 문제로 안될 수 있습니다.
다음으로는 SET XACT_ABORT 에 대해서 알아보도록 할까요? 이녀석을 수행하기 전에 퀴즈 시간입니다. ^_^
자 이정도면 트래젝션의 종류도 말씀을 어느정도 드린듯... 별 특별한 내용은 아니지만.. 저런것이 있다는 것~~ 정도.. 참고하시길 바랍니다. 다음으로 트랜젝션과 체크포인트를 통해.. 안쪽의 데이터를 복구하는 중요 프로세스인 REDO와 UNDO에 대해서 상세히 알아 보도록 하지요. |
****************************************************************************
|
3. 트랜젝션과 체크포인트(Check Point) | |||
|
트랜젝션과 로그는 아주 밀접한 관계가 있습니다. 물론 로그 이야기가 나오니.. 복구 하는 부분과도 대단히 밀접한 관련이 있지요. 또한 SQL서버는 내부적으로 체크포인트라고 하는 프로세스를 발생 시키는데.. 이 작업이 디스크에 쓰기와 관련이 대단히 많습니다. 트랜젝션부터 복구 작업까지 이어지는 이야기를 찬찬히 알아 보도록 하지요.
먼저 한가지 퀴즈 입니다. 데이터 변경 작업이 일어날 경우에.. 예를들면 INSERT나 DELETE, UPDATE 작업이 수행될 경우 이 작업이 즉시!! 디스크 - 컴퓨터의 하드디스크의 MDF화일이나 LDF화일에 쓰여지는 것일까요? 답은 아닙니다 입니다. SQL서버는 빠른 처리 속도를 위해서 이 데이터 변경을 캐시에 저장하고 있다가 Check Point Process(체크포인트 프로세스)라고 하는 SQL서버 내부의 프로세스가 활성화 될 경우에 이 캐시상의 데이터 변경을 디스크에 쓰게 됩니다. 왜? - 빠른 속도를 위해서 입니다. -_-;; 그렇다면? 질문? insert를 하자마자 데이터를 select하면 데이터가 삽입된게 보이자나요~~~ 이건 또 몹니까~~~ 코난이가 구라를 치는 것이냐? -_-;; 아닙니다. SELECT를 하게 될 경우.. 1. 디스크의 테이블에서 데이터를 조회한다. + 2. 메모리상의 캐시 영역에더 역시나 데이터를 또한 조회해서 SELECT의 결과셋을 내부적으로 생성 사용자에게 뿌려주게 되는 것입니다.
조금더 흥미 있는 이야기를 들려 드린다면? 진행중인 트랜젝션 역시 디스크에 쓰게 됩니다. 언제? 체크포인트 발생시마다!! 체크포인트는 퍼지 이론에 의애 대략 1분정도에 한번씩 발생합니다. - 주기 변경 가능합니다. 이때 현재 활성중인 트랜젝션(계속 수행중인 트랜젝션) 역시 디스크에 씁니다. 이를 보통 Write Ahead Log(먼저 쓰기 로그)라고 하며 SQL서버는 이 방식을 취하지요. (사실 내부적인 이야기라서 이런 이야기는 많은 개발자 분들은 필요가 없을듯 하지만.. 이 장의 마지막쯤 말씀드릴 COM 구성요소를 생성할 경우 아주 중요한 이야기가 되기 때문에.. 설명을 드리는 것이니.. 이해해 주세요. - 개발자도 알아야만 합니다.!!!!)
그렇다면 이제 우리가 사용하려 하는 트랜젝션과 체크포인트 이야기를 해 보도록 하지요.
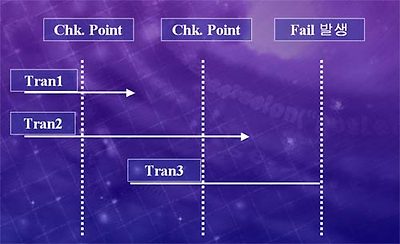
트랜젝션과 체크포인트를 이해하실 때 많이 보셨을만한 그림입니다.
1. 체크포인트 프로세스가 두번 발생했으며 시스템 장애로 꺼져버렸습니다. Tran1, Tran2, Tran3이 있지요. Tran1은 첫번째 체크포인트에서 수행중이였습니다. 그리고 두번째 체크포인트 전에 끝났지요. - 두번째 체크포인트에서 디스크에 써짐 Tran2는 첫번째 체크포인트에서 수행중, 두번째 체크포인트에서 수행중이고 체크포인트 없는 상태에서 트랜젝션이 끝났습니다. Tran3은 두번째 체크포인트에서 수행중 그리고 시스템 실패까지 수행중입니다. 그렇다면 문제가 발생 했을때.. 어느녀석을 복구해야 정석일까요? 이때 바로 맨 처음에 말씀드린 REDO와 UNDO 이야기가 나옵니다. SQL서버는 항상 자동복구라는 프로세스가 SQL서버 시작시 활동하게 됩니다. (정전후 SQL서버를 키니 이상한 스크롤바가 나와서 완료라고 하며 사라지는 것 보신분 계실 겁니다.) 이녀석은 항상 먼저 로그를 확인하고 철회시킬 녀석과 재수행 시킬 녀석을 판단합니다. 복구시는? Tran1은 어떨까요? 체크포인트 전에 Commit이 있으니? REDO(재수행)을 시킵니다. Tran2는 어떨가요? 체크포인트 전에 Commit이 없으니 UNDO(철회)를 시킵니다. - 데이터를 최초의 상태 - 트랜젝션이 시작하기 전의 상태로 바꾼다는 것입니다. Tran3은 그럼??? 역시나 체크포인트 전에 Commit이 없으니 역시나 철회가 됩니다. 그러면? 데이터베이스는 스테이블한 상태가 되면서 계속 작업을 수행하게 되지요.
자.!! 그럼 대강 느끼시겠지만.. 처 체크포인트가 발생하는 시점으로..!! 데이터의 복구와 처리 여부가 결정되니 중요한 녀석이구먼.. 하는 생각이 드실 겁니다. 그럼 저 Check Point는 언제 발생하는가? 1. 자동적으로 1분 정도에 한번씩 발생합니다. 2. 쿼리 분석기에서 CHECKPOINT 라고 수행할 경우 3. SHUTDOWN 구문을 수행할 경우 - 잘 모르시는 분들이 많은데요.. 쿼리로 멈추는 겁니다. 4. SQL서버 서비스를 중단할 경우 이렇게 발생합니다. 기억하실 부분으로.. 1번과 3번 정도가 되겠지요. SQL서버가 멈추어도 수행 됩니다.
잠시 생각을 좀더 드리는 의미로.. sp_dboption에서.. 체크포인트 발생시 로그를 디스크에 기록하지 않고 버리라고 하는 옵션 기억 하시나요?
라고 하시면? 체크포인트시 - 바로 오늘 배우신 체크포인트를 의미 합니다.- 에 로그를 비우는 옵션이지요. 위의 구문은 SQL7과 SQL2000 모두 사용 가능하구요.. 또한 데이터베이스의 복구 모델을 simple모델로 바꿔도 저 옵션이 자동 활성화가 됩니다. SQL2000만 사용 가능한 명령은 아래 입니다.
이렇게 사용 역시 가능하지요. 누누히 말씀 드리지만.. 테스트나 개발용 DB가 아닌 실제 서버에서는.. 위의 방법으로 로그를 비우지 마시고.. FULL 모델이나 대량 로그 모델로 하시고 로그를 주기적으로 백업하라는 말씀을 누누히 드렸습니다. 참고하세요.
또한 checkpoint 발생 주기 변경역시.. 가능하다고 말씀 드렸지요.
라고 해 보시면? recovery interval (min) 이 보일 거구요. 이것이 발생 주기 입니다. 삽입등의 여러 상황을 고려해 변경이 가능하나 함부로 변경할 경우 느려질 수 있으니 참고하세요.
오늘의 트랜젝션 이야기돠는 틀리지만.. 종종 사용하게 되는 옵션이라 리마인드 해 드린 거구요.. 체크포인트 어떤 녀석인지 이제 감이 좀 잡히시는지요? ^_^ 사실 체크포인트와 자동 복구 부분은 SQL서버의 대단히 아래쪽의 이야기 입니다. SQL서버의 여러 엔진 부분의 다양한 요소를 아셔야 하겠지만.. 위에서 제가 설명드린 부분은 이런 아래쪽의 엔진부분을 숨기고 처음 접하시는 분들도 쉽게 접하실 수 있도록 대단히 많이 래핑한것이니.. 조금더 깊이있는 공부를 원하시는 분들은 참고 하시길 바랍니다.
자 그럼 다음 이야기인 잠금을 이해하는 부분으로 넘어가 보도록 하지요. 이녀석도 별것 아닌 쉬운 이야기 입니다. ^_^ |
****************************************************************************
|
4. 잠금(Lock)의 이해 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
트랜젝션이라는 녀석과 잠금이라는 녀석은 대단히 밀접한 관계가 있습니다. -- 그럼 강좌를 마치겠습니다. 라고 하면 물론 집에 가는길에 등뒤에서 번쩍이는 칼을 보게 될지도 모르니.. 계속 진행하겠습니다. -_-;;
잠금을 설명할때 좋은 샘플이 있습니다. 예를들어.. 공유 폴더에 워드 문서를 두시고.. 워드 문서를 오픈하고.. 다른 사용자나.. - 한번더 워드 화일을 오픈하면? 다른 프로세스나 사용자가 현재 해당 화일을 오픈하고 있습니다. 읽기 전용으로 여시겠습니까? 라는 메세지와 함께 화일은 읽기 전용으로 열리거나 열수 없을 것입니다. 이런 상황이 바로 잠금의 개념과 비슷 합니다. 두 사용자가 모두 쓰기를 해 버리면? 어느것을 적용시켜야 할지 알 수 없겠지요? DB의 경우라면 더더욱 큰 문제가 됩니다. 기본적으로 병행DBMS는 기본적으로 여러명의 사용자프로세스가 붙어서 작업을 하게 되니 위와 같은 병행처리는 기본적으로 제공이 되어야 하지요. 그 개념이 바로 잠금이며 SQL서버는 이 잠금이 대단히 다양하고 세분화 되어 있습니다. 차근 차근 봐 나가도록 하지요.
먼저 잠금 내역을 봐 보도록 할까요? 억지로 잠금을 보실 수 있는 쿼리 입니다.
맨처음 보시는 쿼리는 begin tran으로 트랜젝션 범위 내에서 시작하고 commit이나 rollback 등 트랜젝션 끝 이라는 키워드가 없습니다. 즉, 트랜젝션 중으로 하겠다는 것이지요. 그리고 이때 다른 사용자는 계속 pubs에서 대기하게 되는 겁니다. - 나중에 배우시겠지만 블러킹(Blocking)이라고 합니다.
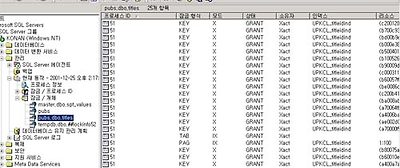
자 그러면 조금더 sp_lock 한 결과를 조금 봐 보도록 하지요. 먼저 type으로 잠금의 타입인데요. 잠금이 걸리는 형식 입니다. 보시면 DB, PAG, KEY, TAB등이 있지요.
잠금이 걸리는 단위는 무엇일까요? 테이블? 페이지? SQL7부터는 로우단위 잠금이 가능했구요... 이 단위를 상세하게 알아 보도록 하지요.
이렇게 잠금이 걸릴 수 있습니다. 로우, 키, 페이지, 익스텐츠등으로 조금더 다양 하지요~ SQL서버는 이렇게 잠금의 단위를 쿼리에 따라서 자동으로 설정합니다. 물론 사용자가 개입해서 잠금을 걸 수도 있습니다. 하지만 이렇게 사용자가 잠금을 거는것은 거의 권장되지 않으며 오로지 BCP, Bulk insert등과 같은 대용량 벌크 작업시 TABLE Lock을 걸 경우를 걸때를 제외하고는 권장하지 않습니다. 벌크작업시는 걸고 하셔야만 제속도를 얻을 수 있습니다. - 많은 분들이 아마 모르셨을듯.. 간단히 사용자가 직접 정의해 잠금을 거는 샘플을 보여 드리면..
이렇게 사용이 가능하며.. 잠금의 힌트로 사용 가능한 옵션들은... 아래와 같습니다.
분명히 말씀 드리지만.. 사용자가 잠금 힌트를 주는 것 보다는.. SQL서버가 자동으로 정하게 하는 것이 대부분의 상황에서 좋으며 잠금의 범위가 커질 경우 역시 SQL서버가 자동으로 락을 에스켈레이션 하게 하는 것이 좋습니다.
자.. 형식은 어떤 것인지 감이 조금 잡히실 겁니다. 역시나 형식과 함께 이어지는 리소스 컬럼의 정보 입니다.
이어서 잠금의 모드 입니다. 이부분이 조금 난해할 수 있으니 잘 봐 보세요.
그리고 이어서 내재 라고 되어있는 잠금이 있는데요.
이렇게 내재된 잠금에 대한 정보 역시 있습니다. 내재 잠금은.. 계층으로 볼때.. 예를들어.. 여러개의 로우에 잠금이 걸린다면? - 페이지 잠금등으로 잠금을 관리 할 수 있습니다. 그런 계층적인 잠금에서 상위 잠금에 대해서 내재된 잠금을 걸고 처리하게 되는 것이지요. 보시는 바와 같이 하위에 대해서 X(단독잠금)이 걸릴 경우 상위 개체는 (IX)내재된 단독 잠금 모드가 걸리게 된다는 의미 입니다.
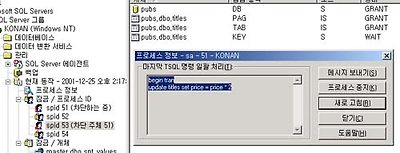
역시나 이런 잠금은 EM으로 보실수 있습니다. 이렇게 EM의 관리 -> 현재동작 -> 잠금 / 개체 부분에서 보실 수 있지요.
자~~ 여기까지가 잠금 / 개체에 대한 이야기이구요. 잠금이 걸린 여러 시스템 개체를 보신 것입니다.
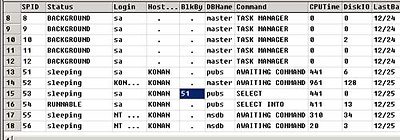
중요하게 또한 보셔야 하는 부분은 잠금 / 프로세스 입니다. 예를들어.. 맨 위의 쿼리를 생각해 보세요. 그 쿼리는 update titles set price = price * 2 라는 구문으로 다른 사용자의 select * from titles 쿼리를 막고 있었습니다. 그렇다면.. 바로 문제가 되는 update쿼리의 사용자가 잠금의 차단 주체(차단하는 녀석)이 될 것이고 select하는 사용자는? 차단을 받고 있을 것입니다. 이것을 볼 수 있게 해주는 것은 sp_who라는 명령이 있는데요.
하시게 되면 blk라는 컬럼에 차단 주체를 볼 수 있게 됩니다. 저의 경우는..
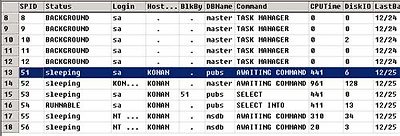
이렇게 SPID 51번 프로세스가 막고 있다고 하네요. SPID 51번 프로세스는 바로???
요녀석일 겁니다... 네 저녀석이라는 것을 자알 알았습니다.. 그렇다면??? 저 SPID 51번 녀석과 53번 녀석이 어떤 쿼리를 수행하는 중인지 알 수 없을까요? 있습니다. 바로.. DBCC명령중의 하나 입니다.
저는 이렇게 나오는군요. 자 그럼 이제 잠금의 차단 주체가 어떤 녀석인지 역시 감이 잡히실 겁니다. ^_^ 이렇게 차단이 일어날 경우를 블러킹(Blocking)이 일어난다고 보통 말을 하게 되며.. 블러킹은 데이터베이스 리소스를 여러명이 사용하기 때문에 당연히 일어나는 것입니다. - 특히 돈이나 재무와 관련되는 프로세스일 경우는 대부분 이 트랜젝션을 이용한 처리를 하기 때문에 종종 블러킹이 일어 나지요. 하지만 대단히 응답속도가 늦거나 - CPU는 놀고 있는데도 불구하고.. 그렇다면 여러 블러킹 처리를 봐 보셔야 하지요. - 이건 뒷부분에서 상세히 적어 보겠습니다.
자.. 쿼리로 하는 방법도 보셨구요. EM에서도 물론 보실 수 있습니다.
관리 -> 현재동작 -> 잠금 / 프로세스ID 부분에서 등록정보를 보시면? 볼 수 있지요.
이정도면 우선적인... 개략적인 잠금을 보신거구요.. 다음 이야기인 잠금과 동시성 부분을 봐 보도록 하시지요. ^_^ |
****************************************************************************
|
5. 잠금과 동시성 | |
|
이번에 드릴 이야기는 잠금과 동시성이라는 이야기 입니다. 동시성이란 것을 가지고.. SQL서버의 중요한 isolation level 이라는 이야기까지 드리게 되지요. 천천히 이야기를 진행해 보도록~~~ 하겠습니다. ^_^
이야기가 늦은듯 하지만... 왼쪽에 보이시는 Friend's Lec부분의 손호성님의 강좌중 데드락 강좌를 보셔도 대단히~~ 많은 도움이 되실테니 참고 하시길 바라구요.
동시성이란 것은 별 내용이 아닙니다. A라는 사용자와 B라는 사용자가 있구요... A라는 사용자는 이전에 보셨던 titles 테이블의 가격을 *2 하고 있으며 B라는 사용자는 읽으려 합니다. 이때 잠금이 걸려서 - 걸려야만 여러 문제를 해결 가능 했지요? - B사용자는 읽을 수 없었습니다.. 하지만.. B라는 사용자는 이런 잠금이 걸려 있더라도 깨고 들어가서 데이터를 읽고 싶었던 것입니다. 그래서 고민을 해 보니... isolation level을 줄 수 있는 것입니다. 혹시나 돌아가고 있는 쿼리가 있다면.. 모두 끄시구요.. 다음을 한번더 수행해 보도록 하지요.
어떠세요? 데이터가 읽어 집니다. ^_^ 자.. 데이터를 자알~~ 읽었습니다만~~~ 맨 처음의 update 쿼리 창으로 다시 돌아오신후.. rollback tran 을 하세요. 그러면 데이터는? *2를 하기 전의 상태로 되돌아 갔습니다. ^_^ 그럼 저렇게 뭔지 모르겠지만 기인~~ set transaction isolation level read uncommitted 라고 붙여서 날린 쿼리의 결과는 뭐지요? - 네 맞습니다. 잘못된 데이터를 불러온 것입니다. 이것은 양극화 된 이야기 입니다. 게시판 로직에서.. 조회수라는 부분이 있습니다. 그 쿼리는 보통 이렇지요.. update 게시판 set 컬럼 = 컬럼 + 1 where 키값컬럼 = 조건 이렇게 update로 잠금을 만들고 조회수를 + 1시키지요. ^_^ 저게 뭐.. 금방 끝나는 건데 신경 안쓰면 되지 않냐??? 라고 하실지 모르지만.. 동시접속자가 한 만명정도 되는.. - 모사이트를 생각해 보세요. 글하나가 올라가게 되면.. 수만명의 사용자가 동시에 와~~ 하고 달라붙어서 게시글을 읽는 부분으로요... 이때 대부분의 사용자는 게시글 하나에 달라붙게 되며 계속 조회수 + 1 때문에 게시글을 보려는 사람은 대기할 수 있습니다. ADO로 만들어진 ASP사이트역시 마찬가지 이지요. - 자동 트랜젝션이 만들어 지기 떄문에.. 하지만 저렇게.. 게시글을 읽는 부분에서.. set transaction isolation level read uncommitted 으로 데이터를 읽는다면? 별 문제 없을 겁니다. - 잠금을 무시하고 데이터를 읽지만... 조회수가 +1이 되었냐 안되었냐는 문제가 아니라는 것이지요!!! 그렇다면 다른 상황으로 계좌 이체를 생각해 보세요. 돈과 관련되면 문제는 항상 심각해 집니다. 계좌 이체 중인 사용자가.. 자신의 계좌와 다른 사용자의 계좌를 조회하니.. 자신의 계좌에서는 1억이 빠져 나갔는데.. 다른 계좌에는 아직 안 들어간걸 보았다면? - 여러 정황으로 문제가 될 수 있다는 것입니다. 적절하게 저러한 NOLOCK을 이용하시면 득을 보실 수 있다는 의미지요. 참고로.. set transaction isolation level read uncommitted 이 명령은.. 연결된 세션 전체에 영향을 주게 되며 - ADO어플일 경우는 해당 쿼리가 수행되는 동안! (NOLOCK)은 해당하는 쿼리에만 영향을 주게 됩니다.
그럼... 이제 저 isolation level에 대한 이야기를 풀어 보도록 하지요. 이는 한글로는 트랜젝션 격리 수준이라고 말합니다. SET TRANSACTION ISOLATION LEVEL 과 같은 구문 정보를 가지게 되구요. 아울러... 각각의 해당하는 트랜젝션 격리 수준은 다음과 같습니다. READ COMMITTED 데이터를 읽을 때는 공유 잠금이 유지되도록 해서 READ UNCOMMITTED 불필요한 읽기나 격리 수준 0을 구현합니다. 이렇게 하면 공유 잠금이 만들어지지 않고 단독 잠금이 무시됩니다. 이 옵션을 설정하면 커밋되지 않은 데이터나 불필요한 데이터를 읽을 수 있습니다. 데이터의 값이 변경될 수 있으며 트랜잭션이 끝나기 전에 데이터 집합에 행이 나타나거나 사라질 수도 있습니다. 이 옵션은 트랜잭션에서 모든 SELECT 문의 모든 테이블에 NOLOCK을 설정하는 것과 같습니다. 네 가지 격리 수준 중 제한이 가장 적습니다. REPEATABLE READ 쿼리에서 사용되는 모든 데이터에 잠금을 배치해 다른 사용자가 데이터를 업데이트할 수 없도록 하지만, 다른 사용자가 데이터 집합에 새 허위 행을 삽입해 현재 트랜잭션의 이후 읽기에 포함될 수 있도록 합니다. 병행성이 기본 격리 수준보다 낮기 때문에 필요할 때만 이 옵션을 사용하도록 하십시오. SERIALIZABLE 데이터 집합에 범위 잠금을 배치해 트랜잭션이 완료될 때까지 다른 사용자가 행을 업데이트하거나 데이터 집합에 삽입할 수 없도록 합니다. 네 가지 격리 수준 중 제한이 가장 많습니다. 병행성이 더 낮기 때문에 필요할 때만 이 옵션을 사용하도록 하십시오. 이 옵션은 트랜잭션의 모든 SELECT 문의 모든 테이블에 HOLDLOCK을 설정하는 것과 같습니다.
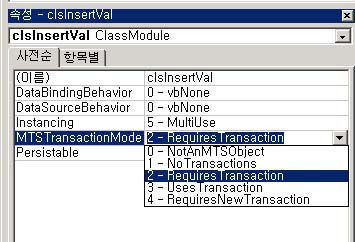
이런 상황이 나오게 됩니다. - 상세한 정보를 원하신다면 온라인 도움말을 참고하세요. SQL서버를 사용하시면서.. 기본은 READ Committed 입니다. 그리고 READ uncommitted를 위와 같은 게시글 정도에서 종종 사용하시게 될 것이구요. 끝으로 SERIALIZABLE인데요. 이 옵션을 설명 드리고 싶어서.. 저렇게 주저리 주저리 적은 것입니다. 많은 분들이 최근 VB로 COM구성요소를 생성하고 사용하는데요..
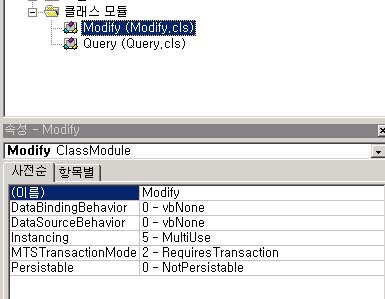
이렇게 MTSTransactionMode를 잡아 주실 겁니다. 여기서 일반적인 데이터를 조회하는 모듈에서는? 1 - NOTransactions 를 사용하실 것이며 데이터를 수정하는 부분에서는 2- RequiresTransaction 을 이용하라고 배우실 겁니다. 이곳의 2- RequiresTransaction을 설정하시게 되면 DB차원에서는 저 트랜젝션 격리수준이 SERIALIZABLE로 잡히게 됩니다. - 무지막지하게 쎈~~ 녀석이 되지만.. 모 좋습니다. 그런데.. 문제는~~ 대부분의 분들이.. 클래스 모듈을 하나로만 생성하시고.. 데이터를 조회하는 부분이나 수정하는 부분을 하나의 클래스에서 모두 수행하게 생성합니다. 즉 - SELECT 쿼리를 수행하는 모듈 역시 SERIALIZABLE한 격리수준으로 처리가 된다는 것이지요. 혼자서 개발을 하고 작업을 한다면 문제가 없지만.. 실제 프러덕션 서버에 적용을 시킨 후에는 문제가 될 수 있지요. 그러면 구성요소 만들때 어떻게 하라는 거냐 트랜젝션을 쓰지 말라는거냐? 간단합니다.
이렇게 데이터를 조회하는 모듈과 수정하는 모듈을 분리하고 처리하는 것입니다. Modify에는 당연히 트랜젝션 필요로 설정하고.. 데이터 조회 모듈인 Query에서는 트랜젝션 사용안함인 1로 처리하시는 것이지요. 이렇게 해당하는 모듈을 분리해서 처리하시면 됩니다. 이 이야기를 드리고 싶어서... 대단히 긴 여정을 밟아 왔군요. ^_^ 많은 분들은 아는 이야기겠지만.. 여러군데에서 저런 문제를 사용하는 개발자 분들을 보아 왔기 때문에.. 이부분을 꼬옥~ 이야기 드리고 싶었습니다.
자.. 동시성에 대한 이야기는 맨 처음에 쬐금 나오고.. isolation level에 대한 이야기만 풀게 되는군요. ^_^ 그외의 트랜젝션 격리 수준들은 제 경험상으로도 거의 사용하실 일이 없으실 것이구요. read uncommitted부분과 SERIALIZABLE 한 부분.. 그리고 기본 모드인 read committed 부분만 참고 하시길 바랍니다. ^_^ 상세한 샘플은.. 사실 제가 사용한 적이 거의 없으니.. 다른분들도 거의 사용 안하실 거라고 혼자만의 생각을 하면서.. -_-;; 이만 넘어가도록 하지요. 혹시.. 위의 세개가 아닌 다른 트렌젝션 격리 수준을 사용하시는 분들은?? 꼬옥 자유 게시판에.. 정황이야기 적어 주시면 감사하겠습니다. - 샘플 만들기 어렵습니다. T.T;;;
그럼 다음 이야기.. 잠금관리 부분으로 넘어가도록 하지요. ^_^ |
**************************************************************************
|
6. 잠금 관리 | |
|
이번에 드릴 이야기는.. 별 내용은 아닙니다. ^_^ 잠금이 걸리는 상황을 타개해보자..의 연장이라고 보시면 됩니다. 잠금을 보고 확인하는 부분은 간단하게 말씀을 드렸구요. sp_who나 sp_who2를 이용해 잠금을 유발하는 사용자 - 프로세스 - 를 보실 수 있으며 역시나 이녀석들을 죽이거나 어떻게 처리를 해 줘야 하겠지요. 방법은 두가지 입니다. 1. kill 명령으로 죽인다. sp_who 로 잠금을 유발하는 녀석을 검사하고.. kill 프로세스ID 명령으로 죽이시면 됩니다. 물론 거의 사용하실 일 없습니다. kill 명령으로 죽인다고 문제가 해결되는 경우는 없습니다. 100명의 오퍼레이터가 있으며 개별 오퍼레이터가 사용하는 모듈을 각각 10~30개의 VB로 만들어진 모듈을 사용한다. 그중 하나의 오퍼레이의 1개 모듈이 잠금을 유발한다면? 아무리 kill 명령으로 죽여봐야 모듈의 버그를 잡고 다시 배포하지 않는 이상 계속 문제가 발생할 것이기 때문입니다. 2. lock timeout을 이용하는 방법 사실 이녀석은 데드락을 줄이는 부분일 수 있지만.. 적절한 응답시간을 얻기 위해서 사용하는 것도 좋은 방법 입니다.
네 이렇게 관리가 가능합니다. 하지만.. 다시 말씀 드리면.. 문제가 되는 모듈을 찾고 이부분을 해결하는 것이 더더욱 중요하지요.
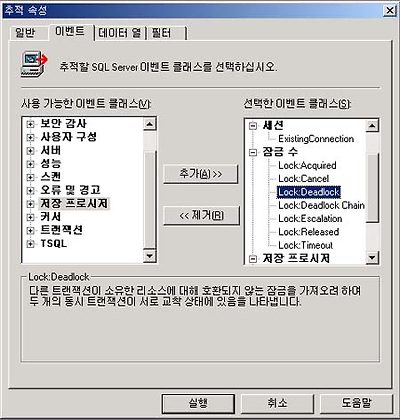
이렇게 보시는 바와 같이.. 성능 모니터링에서 잠금과 관련된 - 데드락 포함 - 여러 이벤트를 조사할 수 있습니다. 또한.. 수행중 데드락(Dead Lock) 이라고 하는 교착상태에 빠질 경우에 역시 참고하실 수 있습니다.
DaedLock이 발생할 경우는 트랜잭션 교착 상태가 발생하여 실행이 중지되었습니다 식의 오류 메세지가 발생하며.. 역시나 성능툴로 모니터링이 가능하구요. 이어서 프로필러를 이용 하시면..
이렇게 Deadlock을 조사할 수 있습니다. 그러면 어느 모듈이나 어느 부분이 문제를 발생하는지 판단이 가능하겠지요. ^_^ ... 잠금 관리에서.. 갑자기 데드락까지 넘어 가는군요.. 끝으로. 잠금으로 발생하는 여러 상황을 보셨습니다. 모니터링 하는 방법도요..
이런 케이스가 있더군요.. sp_who2 로 뭐.. 잘 블러킹을 볼 수 있습니다. - 하지만 동시에 문제의 쿼리를 볼수는 없더군요. 블러킹등이 발생하는 상황은 잘 알 수 있습니다. - 하지만 로깅을 하고 나중에 분석하려할때 대단히 어렵더군요.
이런 저런 이유로.. 프리웨어를 제가 만들었구요.. 사실 담배값 - 아시죠. This 한갑은 1300원.. 에 팔까.. 담배는 피우면서 만드니.. T.T 했으나.. 뭐.. 사실 신경쓸 부분이 이쪽이 아니고.. -_-;;; 사이트 정신에도 위배 되기 때문에.. 프리웨어로 공개 합니다. ^_^ 말은 이렇게 해도.. 참 목구멍이 포도청이라.. 힘든 결심이었답니다. T.T
자료실에서 다운로드 받으실 수 있구요.. 이곳 자료실을 참고 하시길 바랍니다. 이곳에서 받으실 수 있습니다.
물론 코난이나.. 다른곳으로 정보 전송 없습니다. - 스파이 웨어 같은거 할줄 알면 좋겠으나. -_-;; 물론 그런것 없으며.. 나중에 기회가 되면 -__-+++ COM 구성요소로 업글해 만들 생각은 있습니다. - 현재는 C/S입니다. 버그가 있다면 그냥.. 메일만 주시고.. Windows2000 서버와 어드밴스드 서버, 프로에서는 잘 돌아 갑니다. 물론 SQL서버가 설치된 시스템이나.. 원격 시스템(랜상을 기준으로 만들었습니다.)도 잘 됩니다. 도움말 없다고 미워 마시고.. 이곳을 참고해 보세요..
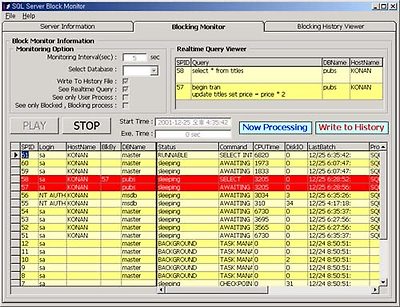
대충 쿼리 분석기 처럼 붙으면.. 이런 서버 정보 화면 나옵니다. 아시죠? 서버 정보일 뿐입니다. -_-;;
중요한 블러킹 화면으로.. 시작 - 멈춤이 있구요.. 보시면.. blkby라는 컬럼이 있지요? 블럭하는 녀석이고.. blk된 녀석까지 붉은 색으로 했습니다. 그리고.. 오른쪽 윗부분에 SPID와 Query를 실시간으로 - 사실 약간의 딜레이가 있으므로 LAN상의 SQL서버 시스템을 이용하시길 권장합니다. - 보실 수 있습니다. 옵션중에는.. 리프레시 간격을 초단위로 조절이 가능하며.. 히스토리로 로깅하시고..블럭 히스토리 탭에서 나중에 다시 블럭된 쿼리를 보실 수 있습니다. - 어느 모듈이 문제인지 즉시 확인 가능하겠죠? 나머지는 직접.. 해 보시길.. 테스트는 SQL2000에서 했으며.. SQL7에서도 돌아는 가는 걸로 압니다. System Admin 롤의 계정을 사용하셔야만 하며 - 그래야 DBCC명령 등 잘 됩니다. 내부적으로 master DB에 하나의 저장 프로시져를 생성하고 그녀석으로 위의 정보를 보여주는 겁니다. - 버그가 있더라도 양해하시고.. 그냥.. 있는 그대로 사용해 주시길 바랍니다. -_-;; 저역시 가끔 사이트에서.. 블러킹 확인할때의 용도로만 사용합니다. 한 컨커런트한 유저가 50명 정도가 되어도 끄떡 없이 잘 보여주니 참고하세요.
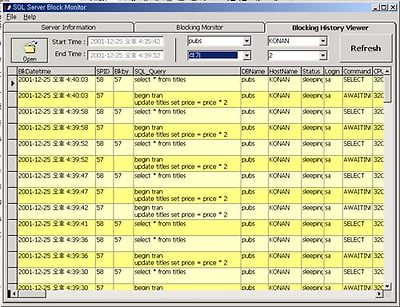
히스토리 분석 탭으로... DB선택, 호스트 이름 선택, 어플리케이션 이름 선택.. 그리드의 높이 조절 기능이 있으니 참고하세요. - 이정보는 서버가 아닌 로컬 시스템에 이진 화일로 저장 됩니다. - 엑세스 형식 항상 걸고 사용하는 것은 권장하지 않으며.. 위에 말씀 드린대로.. 원하는 정보만 볼수 있게 만든 기능성 프로그램입니다. 소스 공개는.. 나중에 시간 여유가 되어서 3Tier로 재구축이 가능하게 된다면 그때 공개 하도록 하구요. 허접하지만.. 나름대로 여러 목적으로 이용 가능합니다. 어느 SQLER의 회원님은 웹서버 로드 밸런싱 확인 용도로 쓰시더군요. -_-;;
패키징을 인스톨 실드 7.1 DEV버젼으로 했구요.. 그리두는 모두 제가 좋아하는 투루디비그리드.. -_-;; ADO 2.6을 사용하며.. 히스토리는 엑세스로 생성 했습니다.
그럼 끝으로.. 데드락 이야기를 하도록 할까요! |
************************************************************************
|
7. 데드락(Deadlock)처리 |
|
트랜젝션과 잠금의 마지막 이야기는 데드락 입니다. 앞에서 언급을 해 드렸지만... 데드락은.. 사용자1과 사용자 2가 있다고 가정해 보겠습니다. 그리고 테이블A와 테이블B가 있다고 가정해 보지요..
사용자1은 트랜젝션 처리를 테이블A -> 테이블B -> 작업후 완료.. 이렇게 처리를 하며..
사용자2는 트랜젝션 처리를 테이블B -> 테이블A -> 작업후 완료 이렇게 처리를 합니다.
이럴 경우... 사용자1이 테이블A를 잡을때, 동시에 사용자2가 테이블 테이블B를 해들했다고 가정한다면.. 각각의 처리들은 모두 다음 개체를 사용하려고 서로 노려만 보고 있는 것입니다. 이런 상황을 교착상태라고 하며.. 이 데드락은 역시나 SQL서버가 중재를 해서.. 하나의 프로세스를 Victim(희생양)으로 해 버리는 식으로 처리합니다. 이렇게 데드락이 걸리는 상황을 간략히 말씀 드렸구요..
이 데드락을 피하는 방법은 잘 구성된 솔루션 개발 계획입니다. 예를들어.. 회사내부에 제품 삭제를 하기 위한 프로세스가 있다면? 1. A테이블 수정 2. B테이블 수정 3. C테이블에서 삭제 4. 제품 삭제 이렇게 운용이 될 겁니다. 그리고.. 사용자 삭제 프로세스라는 녀석이 있다면? 1. Y테이블 삭제 2. X테이블 삭제 3. C테이블 삭제 4. B테이블 삭제 5. A테이블 삭제 6. 사용자 삭제 이런 프로세스로 생각하실지 모르나.. 보시는 바와 같이.. 프로세스 수행 방식이 서로 엇갈리는 - 데드락 발생 가능성이 높은 프로세스 처리 방식이 되었습니다. 이럴때.. 하나를 바꿔 주시면 됩니다. 저는 사용자 삭제 프로세스를.. 1. A테이블삭제 2. B테이블 삭제 3. C테이블 삭제 4. X테이블 삭제 5. Y테이블 삭제 이렇게 순서를 바꾼다면? 프로세스 수행중에.. 트랜젝션 처리가 교착될 염려는 없겠지요. 이렇게 바꾸는 것을.. 시리얼하게 바꾼다고 보통이야기 합니다.
하지만.. 저렇게 프로세스 흐름을 바꾸기란 정말 쉬운일이 아닙니다. 해보신분은 아실 겁니다. 개나소나 다~ 참조하는 user테이블의 한 계정을 지우려면? 이곳 저곳의 참조하는 객체를 먼저 지운후 user테이블을 지워야 하지요. 저는 개인적으로 30개 정도의 테이블에서 삭제후 user테이블을 지우던 기억이 납니다.-_- 저렇게 바꿀수가 없을것 같다구요? 말도 안될것 같지만 가능합니다.
저장 프로시져와 같은 프로그래밍 로직으로.. 순차를 정해.. 정 먼저 지울 녀석이 있다고 해도.. 적절하게.. 변수로 키값을 select로 받아만 두고 변수에 저장후 나중에 지우거나.. 이렇게 처리가 분명 가능합니다. 그리고 수정이 걸리는 부분은 저렇게 처리가 가능하지요.
막을 수 있는 근본적인 방법? 간단합니다. 프로젝트를 기획 하시면서.. 컴퍼넌트 디자인 프로세스나.. 구현 단계에서 해당하는 테이블 접근 순서를 문서화 하는 것입니다. 그리고 또한 트랜젝션 처리 모듈은 따로 관리를 해서.. 트랜젝션 처리 순서 모듈을 문서화 해두고.. A저장 프로시져가.. L-> M -> N 이라고 접근을 한다.. 그러나 B저장 프로시져를 생성할때도 J -> K -> L 이라고 개체를 접근하게 해야 겠다는.. 기준이 남도록 적절한 문서화를 해 두시면.. 대형 프로젝트로 여러명이 나누어 개발을 할 경우라도 저러한 교착상태나 블러킹을 최소화 하실 수 있게 되는 것입니다.
만약 데드락이 발생한다면? 바로! 해당 어플리케이션 모듈의 디버깅을 들어가시면 되겠지요. ^_^ 데드락 샘플을 보시기 보다는.. 이렇게 개발단계의 시리얼라이즈한 개체 핸들 순서의 문서화가 더 중요한 부분이기 때문에.. 이정도로.. 데드락 처리를 마치도록 하겠습니다.
오래간만에 강좌를 적으니.. 조금 어깨가 뻐근~~ -_-;; 하네요.. 이제 약간 여유가 생겼으니.. 빠르게 강좌 마무리에 들어 가도록 해야겠군요. ^_^
샘플이 이번에는 별로 없어 실망이라구요? ^_^ 제가 잠금과 데드락이나(사실 거의 발생 안합니다. - 이름만 무서운 데드락일 뿐입니다.) 이런 문제를 접하면서.. 이 장에서 설명드린 내용 이상의 내용은 거의 없습니다. 나중에 자신이 필요하다면.. 추가적으로 공부를 진행하시면 도움 되겠지요. ^_^
자 수고하셨구요.. 혹시나 이 강좌의 내용에 문제가 발견 된다면? 바로 메일이나.. 게시판에 글을 남겨 주시길 바랍니다. ^_^
그럼 이만. |