뭉치가 알려주는 국어 말뭉치
- 빅 데이터 시대, 언어 데이터 분석하기
- 이상아(서울대학교 기초교육원 교수)

빅 데이터(Big Data) 시대가 도래함으로써 대규모 데이터로부터 필요한 정보를 추출하고 분석하는 것이 필수 능력이 되었다. 대규모 데이터란 사람의 손으로 일일이 검수하고 처리할 수 없는 양의 데이터를 말하며, 이는 결국 자동화된 방법을 통해 다루어야 할 것이다. 여기에서 컴퓨터 프로그래밍이 중요한 역할을 한다.
다양한 언어 자료를 포함하는 말뭉치 역시 그러한 빅 데이터의 한 종류이다. 말뭉치는 신문 기사, 댓글, 상품평, 블로그, 인스타그램이나 유튜브 등의 콘텐츠와 같이 실제 사람들이 작성한 글 또는 발화로 구성된다. 따라서 이러한 자료를 이루는 단어들의 빈도수와 분포, 통사 구조, 문체, 문맥에 녹아 있는 정보 등 텍스트에 내포된 여러 언어적 특성을 끌어내서 분석한다면 여러 흥미로운 결과를 얻을 수 있을 것이다. 필자는 이 중에서도 가장 간단한 정보인 단어의 사용 분포를 가지고 파이선 프로그래밍을 이용한 분석 과정을 소개하고자 한다.
한국어 말뭉치는 현재 국립국어원 모두의 말뭉치와 KLUE benchmark를 포함하여 다양한 개별 출처를 통해 얻을 수 있다. 이들 말뭉치는 특별한 분석 기능을 포함하지 않는 텍스트 데이터 그 자체이나, 대부분 관리 및 분석을 보다 편리하게 하기 위해 csv, json, xml 등의 형식으로 구조화되어 있다. 각 형식은 특정한 문법에 따라 정의되어 있으며, 파이선에서 제공하는 라이브러리¹를 통해 자동으로 처리할 수 있다.
¹ 라이브러리(library): 프로그래밍을 위한 함수, 클래스, 자료 등을 사용하기 쉽도록 묶어 놓은 것
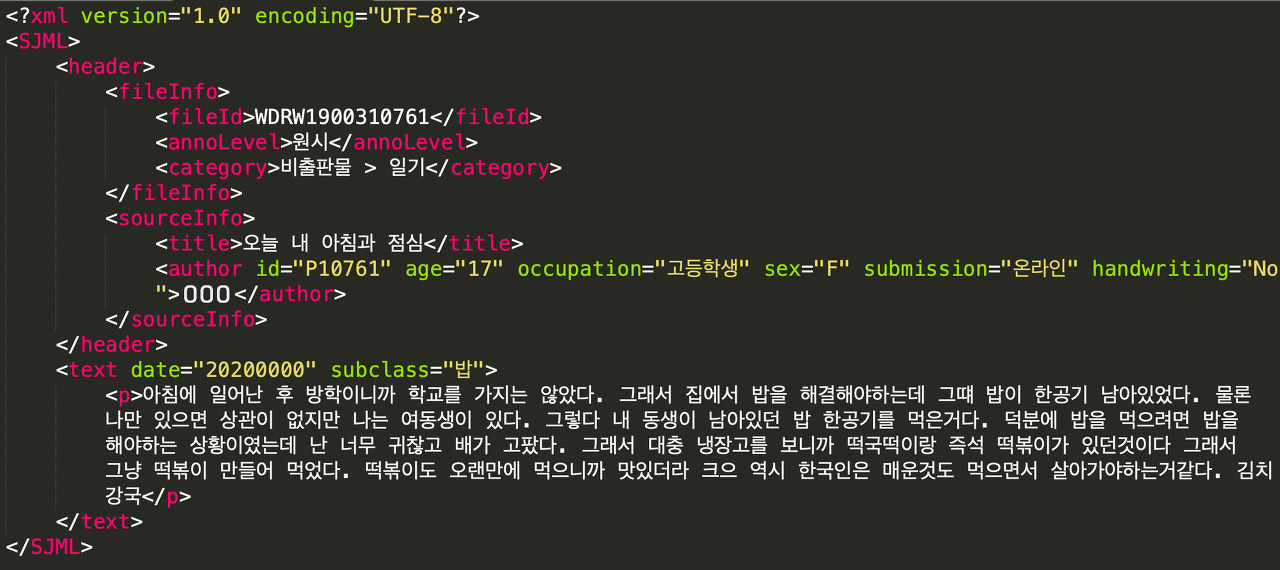
▲ [그림 1] ‘국립국어원 비출판물 말뭉치(버전 1.1)’의 파일 예시
[그림 1]은 국립국어원 모두의 말뭉치에서 배포하는 ‘국립국어원 비출판물 말뭉치(버전 1.1)’에 포함된 글 중 하나를 표시한 것이다. 이 말뭉치는 대중이 작성한 일기, 편지, 수필, 감상문 등의 글을 모아 구성한 것이며, 글 한 편이 하나의 xml 파일로 작성되어 있다. 파일마다 xml 문법에 따른 태그를 이용해서 파일 번호(file id), 글의 종류(category), 제목(title), 저자(author) 등의 메타 정보와, 글의 본문(text)을 별도의 영역으로 표시하고 있다.

파이선 라이브러리를 이용하면 이러한 구조를 자동으로 분석하여 원하는 영역의 정보를 추출할 수 있다. 예를 들어 xml 파일 구조에서는 파이선의 xml 라이브러리를 이용해 각 태그 영역에 쓰여 있는 정보를 따로따로 추출할 수 있다. 위 코드는 xml 구조로 작성되어 있는 파일을 분석하여 트리 구조로 저장해 두는 기능을 한다. 이를 이용해 다음 코드와 같이 이 파일에 주석되어 있는 메타 정보 중 태그를 이용해 저자의 나이, 성별, 직업을 추출해 볼 수 있다.

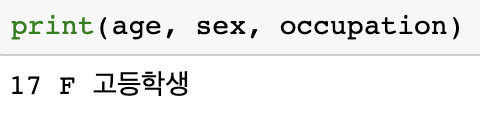
말뭉치 파일 안에 정의된 태그와 ‘age’, ‘sex’, ‘occupation’ 등의 속성 정보를 이용하여 위 글의 저자가 17세 여성이며 고등학생 신분임을 알 수 있다.
또한 작성글의 본문은 와
태그 등으로 구성되어 있으므로 이를 이용해 추출한다.


이렇게 추출한 텍스트에 다양한 방법의 분석 방법을 적용할 수 있다. 예를 들어 텍스트를 형태소 단위로 나누고 각 형태소의 사용 양상을 분석해 볼 수 있을 것이다. 파이선 환경에서 한국어 형태소 분석을 수행할 경우, konlpy 라이브러리를 주로 이용한다.
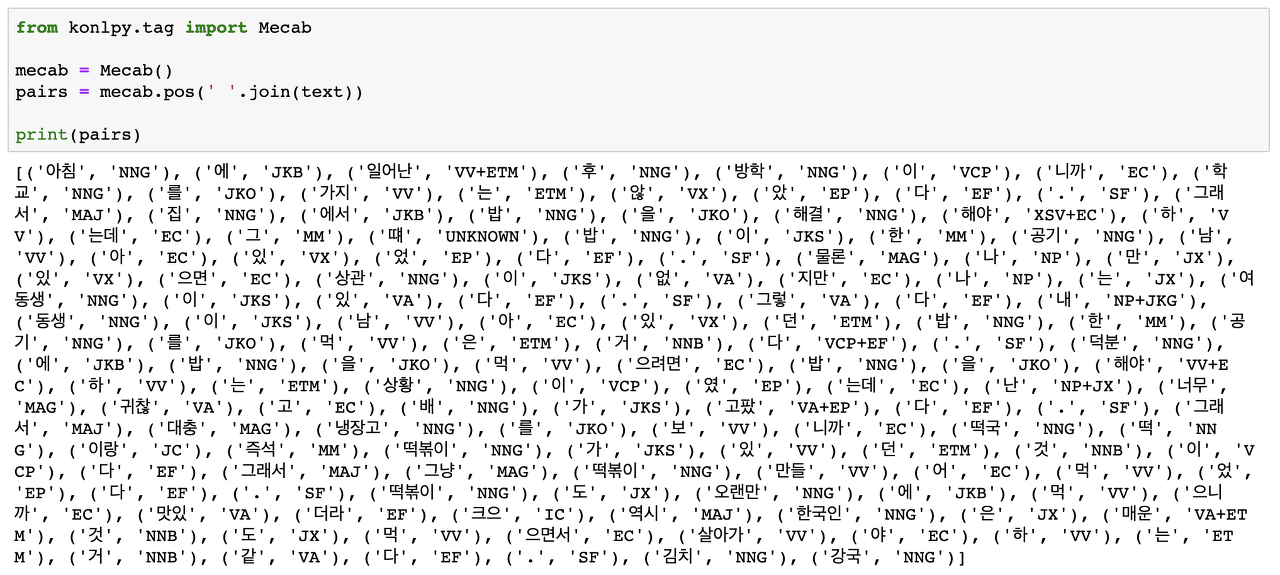
konlpy 라이브러리에서 제공하는 형태소 분석기에 텍스트를 입력하여, 각 형태소와 그에 해당하는 품사를 결과로 얻을 수 있다.
이러한 분석 과정을 말뭉치 안에 있는 글들 전체에 일괄적으로 적용하면, 글마다 사용된 단어(형태소)의 빈도수와 그 분포를 확인하고 또 연령별, 직업별 등 다양한 기준에 따라 묶어서 비교해 볼 수도 있을 것이다. 필자는 ‘국립국어원 비출판물 말뭉치(버전 1.1)’에 포함된 12,483편의 글 중 그 종류가 ‘일기’와 ‘수필’에 해당하는 10,767편을 선택하여 분석 대상으로 삼았다. 또한 각 글에서 ‘직업’, ‘연령’, ‘성별’과 같은 메타 정보를 얻었고, 글 본문으로부터 일반 명사와 고유 명사에 해당하는 품사를 가진 형태소만을 모았다. 이렇게 얻은 정보는 [그림 2]의 표와 같이 하나의 데이터로 저장해 두었다.
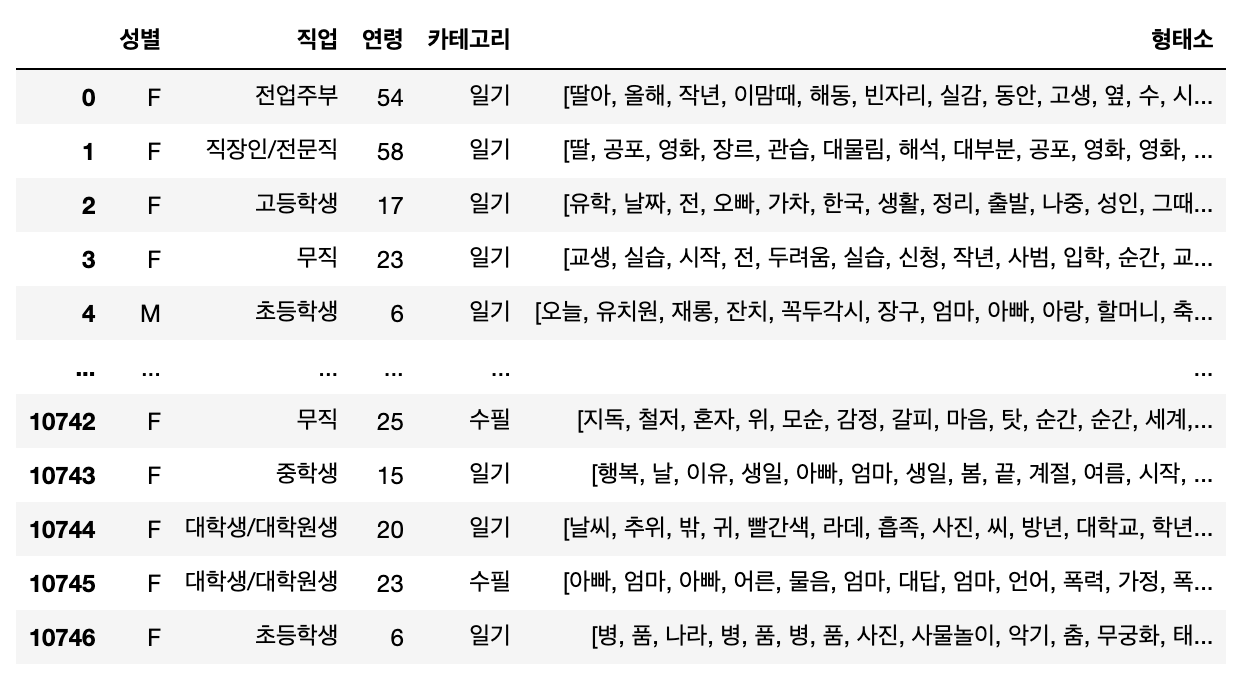
▲ [그림 2] ‘일기’와 ‘수필’ 글의 저자 정보와 명사 정보
이때 저자의 연령을 ‘10대 이하, 20대, 30대, 40대, 50대, 60대 이상’의 6개 그룹으로 나누고, 각 그룹에 해당하는 저자들이 주로 어떤 명사를 사용하여 글을 작성했는지를 세어 볼 수 있다.
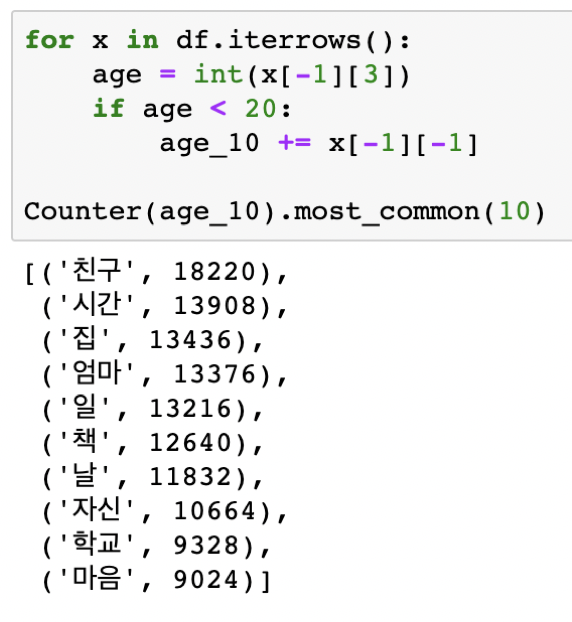
다음 코드는 20세 미만의 저자들을 ‘10대 이하’라는 그룹으로 묶고, 이 그룹에 해당되는 저자들의 텍스트 모두에서 사용된 명사들 중 가장 빈도수가 높은 순서대로 10개를 추출한 것이다. 순서대로 ‘친구’, ‘시간’, ‘집’, ‘엄마’, ‘일’, ‘책’, ‘날’, ‘자신’, ‘학교’, ‘마음’이 추출된다. 이때 각 형태소 옆의 숫자는 해당 형태소가 ‘10대 이하’ 저자들의 글에서 사용된 빈도수를 뜻한다.
이렇게 각 그룹에서 사용된 명사들 중 빈도수가 높은 것들을 추출하고, 이것들을 그룹별로 시각화하여 비교해 볼 수 있다. 먼저 각 연령 그룹별로 사용 빈도수가 가장 높은 명사를 10개씩 추출하여 [그림 3]과 같이 표로 정리해 보았다. 이에 따르면 연령 그룹별 단어의 사용 양상이 조금씩 다름을 알 수 있다.
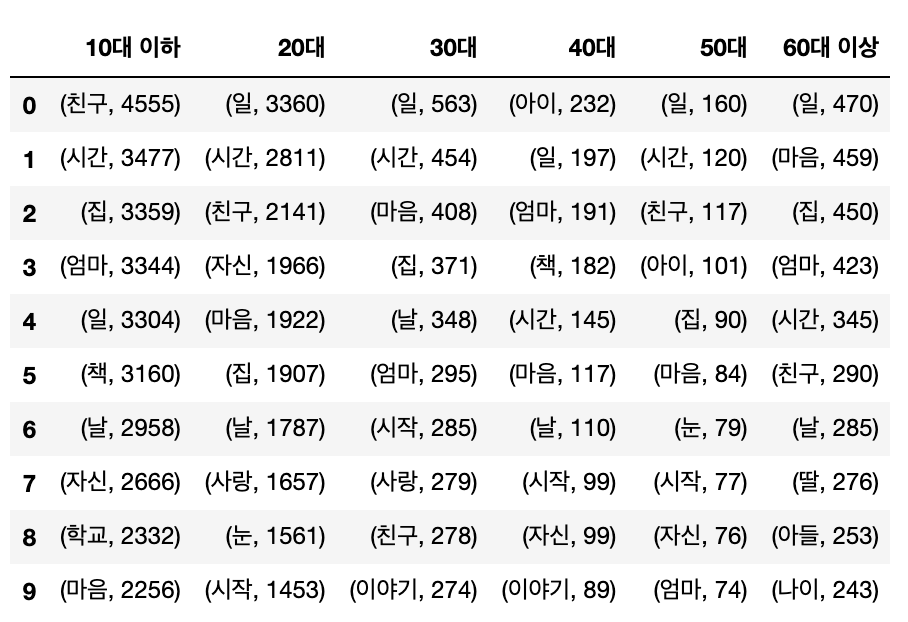
▲ [그림 3] 연령대별 고빈도 사용 명사 목록
이러한 결과를 그래프나 그림 등을 이용해 시각화하면 그 차이가 더욱 쉽게 눈에 들어온다. 여러 방법이 있겠지만, 단어 빈도수 및 분포를 시각화할 때는 아래 [그림 4]와 같은 워드클라우드(word cloud)를 자주 사용한다.


▲ [그림 4] 연령대별 고빈도 사용 명사 시각화(워드클라우드)
이 워드클라우드는 상위 1,000개씩의 명사들을 이용하여 구성한 것이다. 각 워드클라우드에서는 글자 크기가 클수록 빈도수가 높은 단어를 나타낸다. 이에 따라 위의 연령대별 워드클라우드를 살펴보면, 연령대 그룹에 따라 빈도수가 높은 단어들이 조금씩 다르게 나타나는 것을 확인할 수 있다. 예를 들어 ‘엄마’, ‘아빠’, ‘이야기’, ‘마음’ 등 흔히 사용되는 단어들은 서로 다른 연령대 그룹에서도 공통적으로 쓰이지만, 10대 이하 저자들의 글에서는 ‘언니’, ‘동생’, ‘할머니’, ‘게임’이, 20대와 30대 저자들의 글에서는 ‘일’, ‘시간’, ‘사랑’(20대), ‘여행’(30대)이, 40대와 50대 저자들의 글에서는 ‘일’, ‘아이’, ‘가족’(50대)이, 60대 이상 저자들의 글에서는 ‘딸’, ‘아들’, ‘마음’, ‘인생’ 등이 다른 집단들과 달리 두드러지게 나타난다. 또한 이 글에는 포함하지 않았으나, 위의 코드에서 저자의 직업이나 성별 등의 정보도 추출할 수 있으므로, 직업과 성별에 따른 단어의 사용 분포를 비교 분석해 볼 수도 있을 것이다.
그 외에도 파이선 코드와 라이브러리 등을 이용하여 다양한 각도의 분석이 가능하다. 위 예시에서는 단일 단어의 단독 사용 빈도수를 분석했지만, 실제 텍스트 분석, 자연어 처리 영역에서는 바이그램(bigram), 트라이그램(trigram)² 등을 이용한 단어의 공기(collocation), 여러 단어들이 문장 안에서 결합되면서 이루는 통사·의미적 구조, 문맥 등 다양한 언어적 특성을 텍스트로부터 이끌어 낼 수 있다. 그것을 이용해 특정한 저자 그룹의 의견을 비교 분석하거나, 특정한 시기에 신문 기사나 누리소통망(SNS) 등에서 폭발적으로 언급량이 증가하는 키워드를 분석하는 것 등이 가능할 것이다.
² 바이그램, 트라이그램: 문장 내의 단어들 중 연속하는 2개, 3개 등의 단어를 하나로 묶어서 다루는 단위
또한 이러한 언어적 특성을 기계 학습, 딥러닝 등의 모델과 결합하여 사용한다면 텍스트 데이터에 대한 연산과 예측을 통해 더욱 복잡하고 추상적인 언어 분석을 수행할 수 있다. 여기에는 현재 국립국어원 모두의 말뭉치를 비롯한 여러 출처에서 제공하는 데이터에 대한 의미역 분석, 어휘 의미 분석, 문법성 판단, 개체명 분석, 상호 참조 해결, 문서 요약 등의 과제들이 해당된다. 예를 들어 개체명 분석 말뭉치에서는 텍스트 안에 특정한 인명, 지명 등의 개체명이 포함되어 있고, 정교하게 학습된 언어 모델이 텍스트 처리를 통해 문자열의 어느 위치에 어떤 개체명이 해당되는지를 포착해 내는 것이다.

프로그래밍을 이용한 말뭉치 분석은 대규모의 말뭉치에 대해 체계적인 작업을 일괄로 수행하여 더욱 효율적인 자료 이해를 돕는다. 이러한 장점이 현재 구축되어 있는 말뭉치를 포함하여 더 새롭고 다양한 언어 자료에 적용되어 여러 분야의 연구와 산업 등에 도움이 되기를 기대한다.